College debt is a hot topic right now. Elizabeth Warren wants to cancel most of it. Bernie Sanders wants to cancel all of it. Donald Trump loves the idea of bankruptcy (not from college debt — just as a general principle).
But since forgiving student debt, like any meaningful reform in America, is a silly pipe dream, let’s instead fix it by eliminating information asymmetry. Because if there’s anything American college students are not, it’s informed consumers.
Colleges are expensive, and costs have grown wildly faster than overall wage growth. We all know that some majors, and some for-profit colleges, provide almost no value. But since undergraduate education is a cash cow for universities, self-regulation of tuition growth — growth used to boost spending on new dorms, rec centers, and bureaucrats — by the universities themselves is utterly unrealistic.
The crowning achievement of the Food and Drug Administration — right alongside keeping children from dying of Salmonella — is accurate, mandatory, Nutrition Facts. Nutrition Facts are a universal constant. Without them, the American consumer would be forced to perform difficult calculus like “quantify how much lard is in a medium-sized lardburger.”
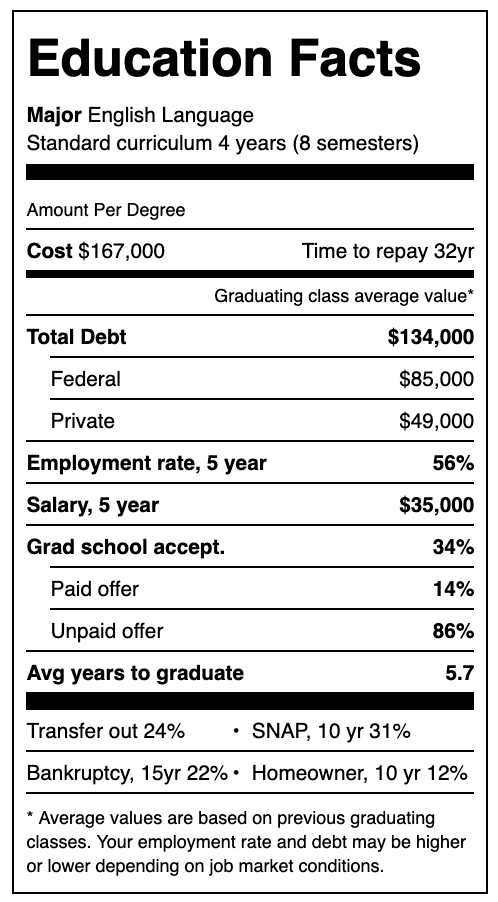
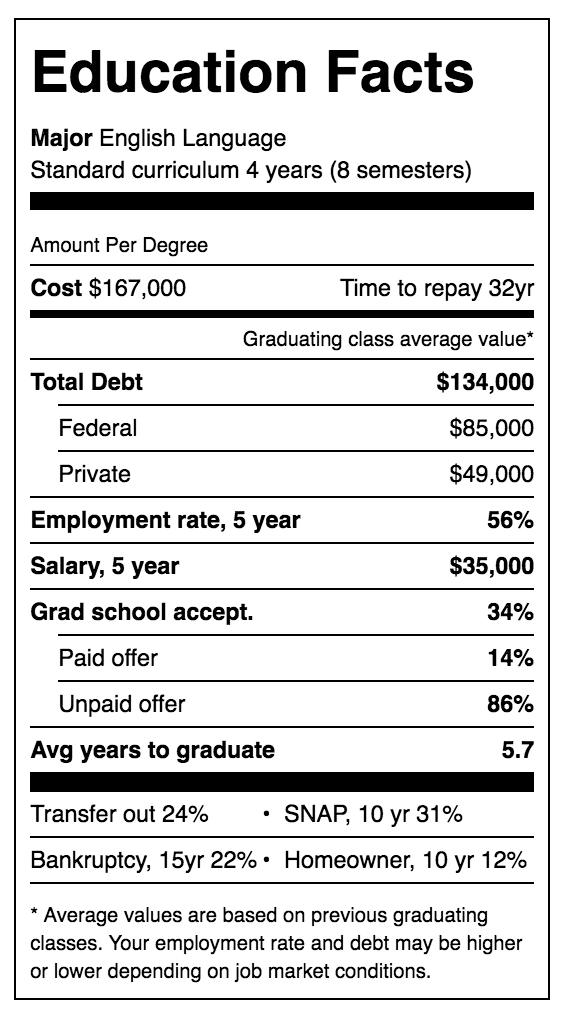
So, building on the wild success of Nutrition Facts, here’s my modest proposal: Federal Department of Education mandated Education Facts labeling:
This summary statistics table will give students the ability to identify which colleges can actually improve their futures, and which exist mainly as a parasitic drain on society. Advertising will be totally legal — but must come coupled with vital statistics. These will focus on:
Debt. The big kahuna. How far underwater is the average Philosophy major when they swim off the graduation stage?
Salary and employment. 5 years post-graduation, where is your career? Can you dig yourself out of your debt before your children die?
Grad school acceptance. If you’re going to die in debt, at least do it in style. Can your undergraduate education help shelter you from the real-world with another 8-15 years of graduate school?
These statistics won’t just be available online. McDonalds publishes nutrition facts online, but the mobility scooter market is as hot as ever. These Education Facts will be attached to every form of advertisement produced by an institution of higher learning.
To help build a vision of this fully-informed world, I have illustrated a few examples:
College brochures — The paper deluge that every high-school student wades through during Junior through Senior years. Education Facts would help triage this garbage pile, by filtering the wheat from the for-profit scams:
Billboards: Colleges are huge on billboards now-days. It is only appropriate that claims like “career launching” be substantiated, in similarly giant font:
Sports: College sports are, without a doubt, the most ironic yet effective form of higher-education advertising on the planet. The only ethical use of this time and attention is to put numbers and figures in front of the eyeballs of impressionable high-school students:
This will not be an easy transition for America. While calorie-labelling Frappuchinos at Starbucks inspired consternation, guilt, and shame across America, it did in fact cut calorie consumption markedly.
Education Facts will hurt lousy colleges. It will hurt schools which peddle useless majors to naive students. But the students of America will come out of it stronger, more informed, and more solvent than ever before.
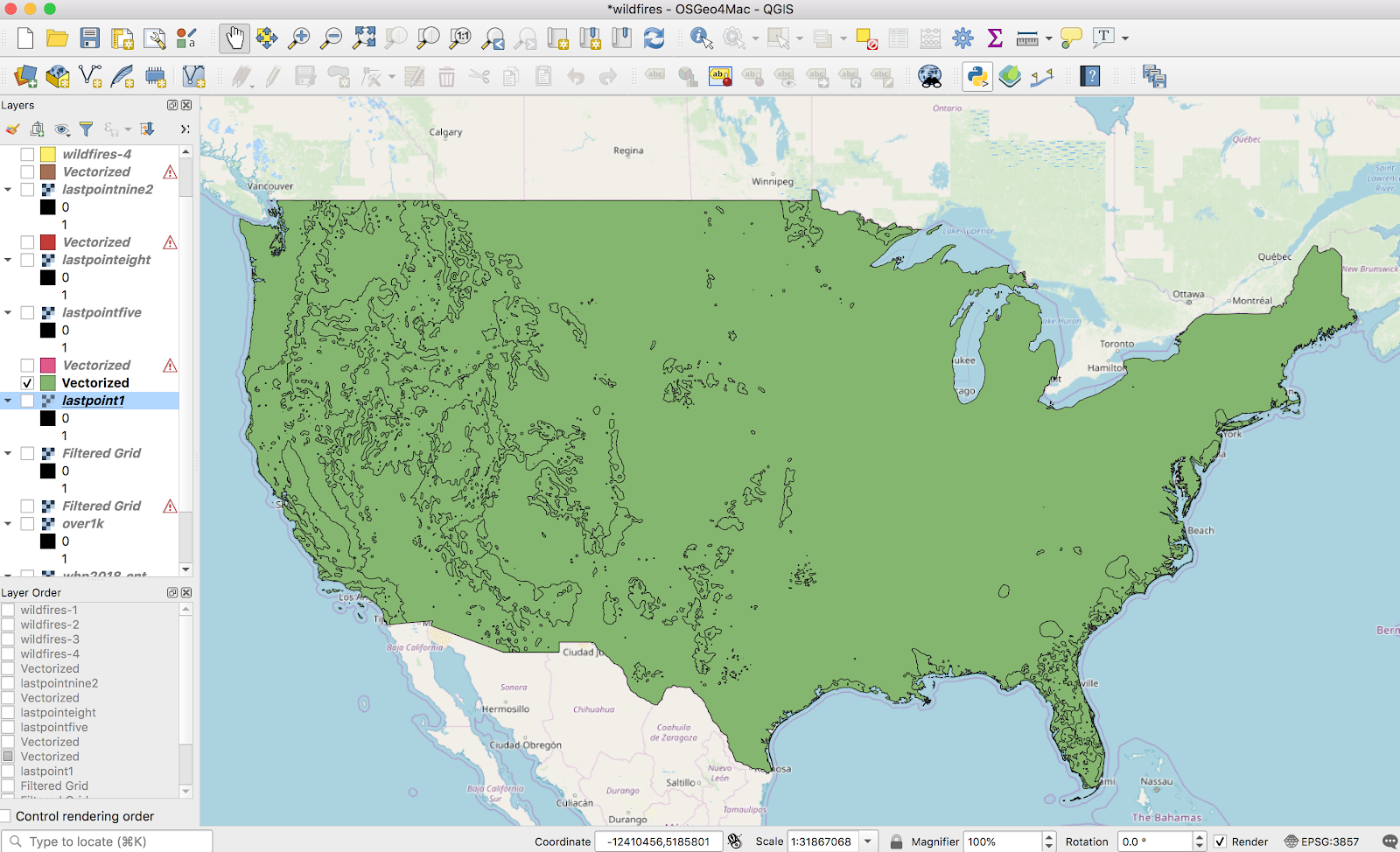
I thought was done learning new QGIS tools for a while. Turns out I needed to learn one more trick with QGIS — the Gaussian filter tool. The Gaussian filter is sparsely documented basically undocumented, so I figured I’d write up an post on how I used it to turn a raster image into vector layers of gradient bands.
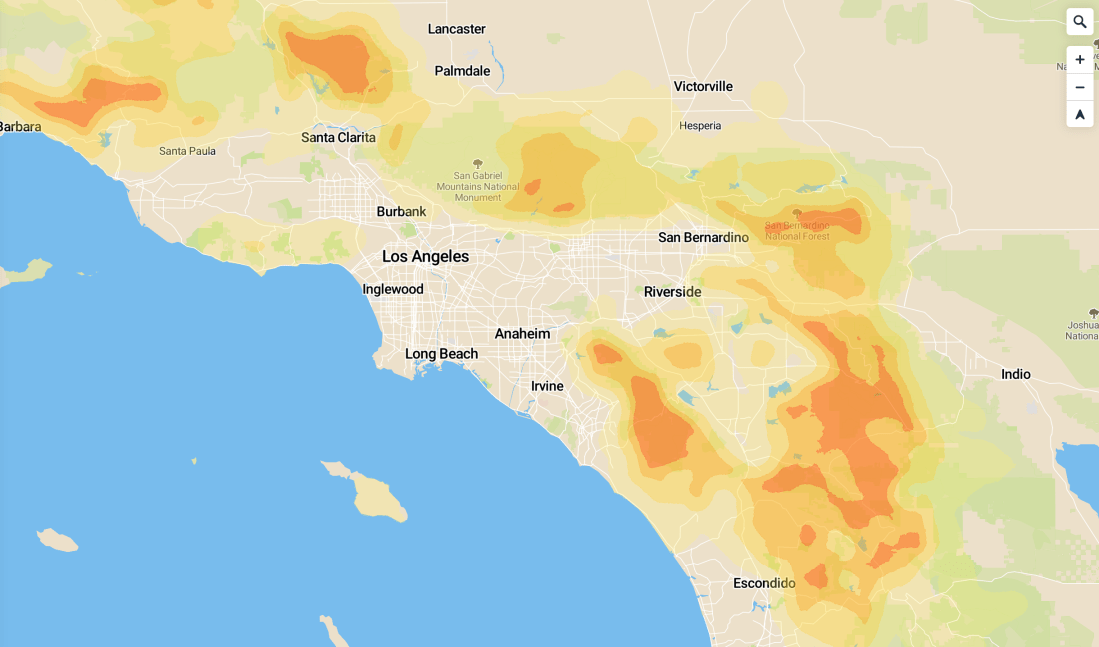
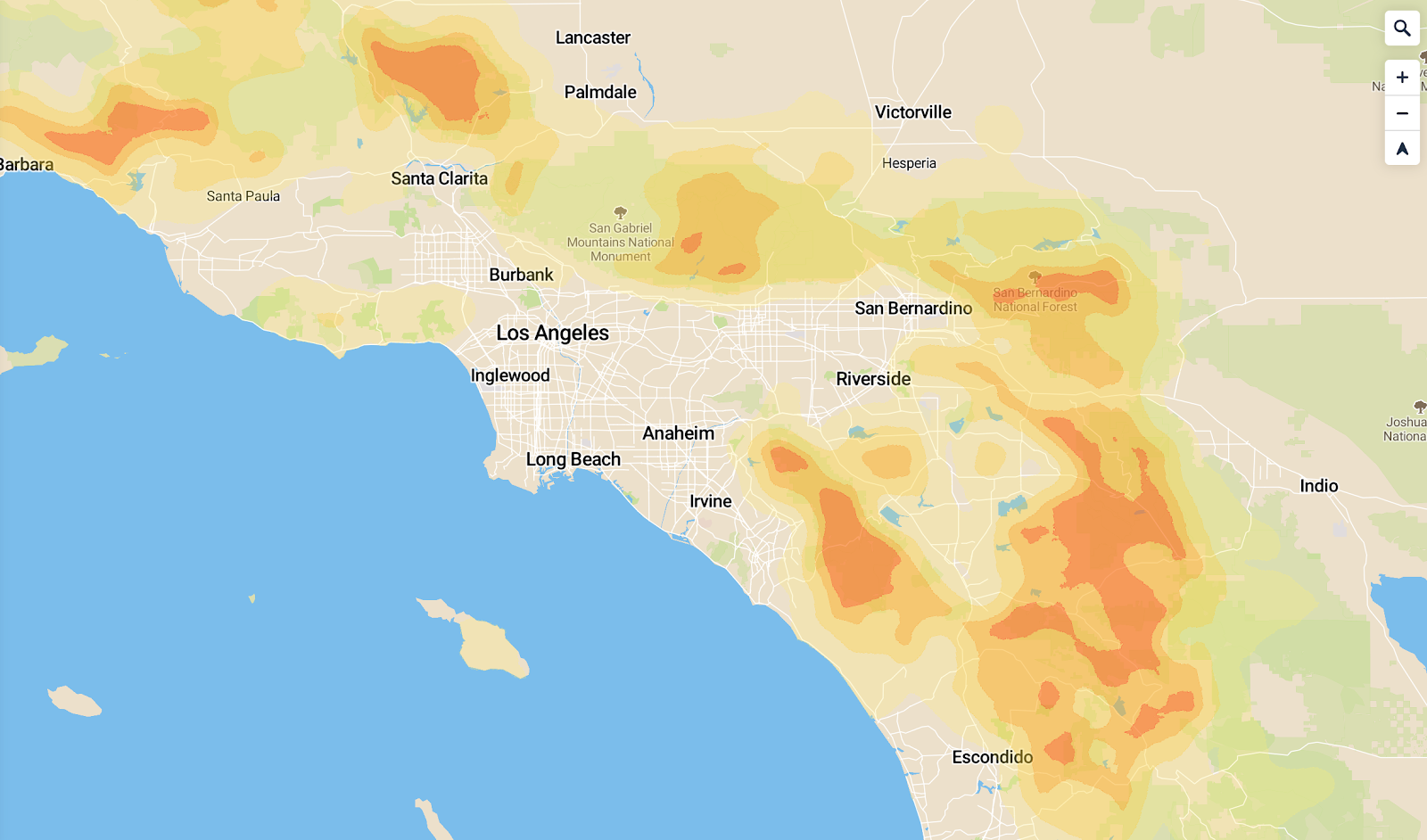
Motivation: In my spare time I’m adding more layers to the site I’ve been building which maps out disaster risks. California was mostly on fire last year, so I figured wildfires were a pretty hot topic right now.
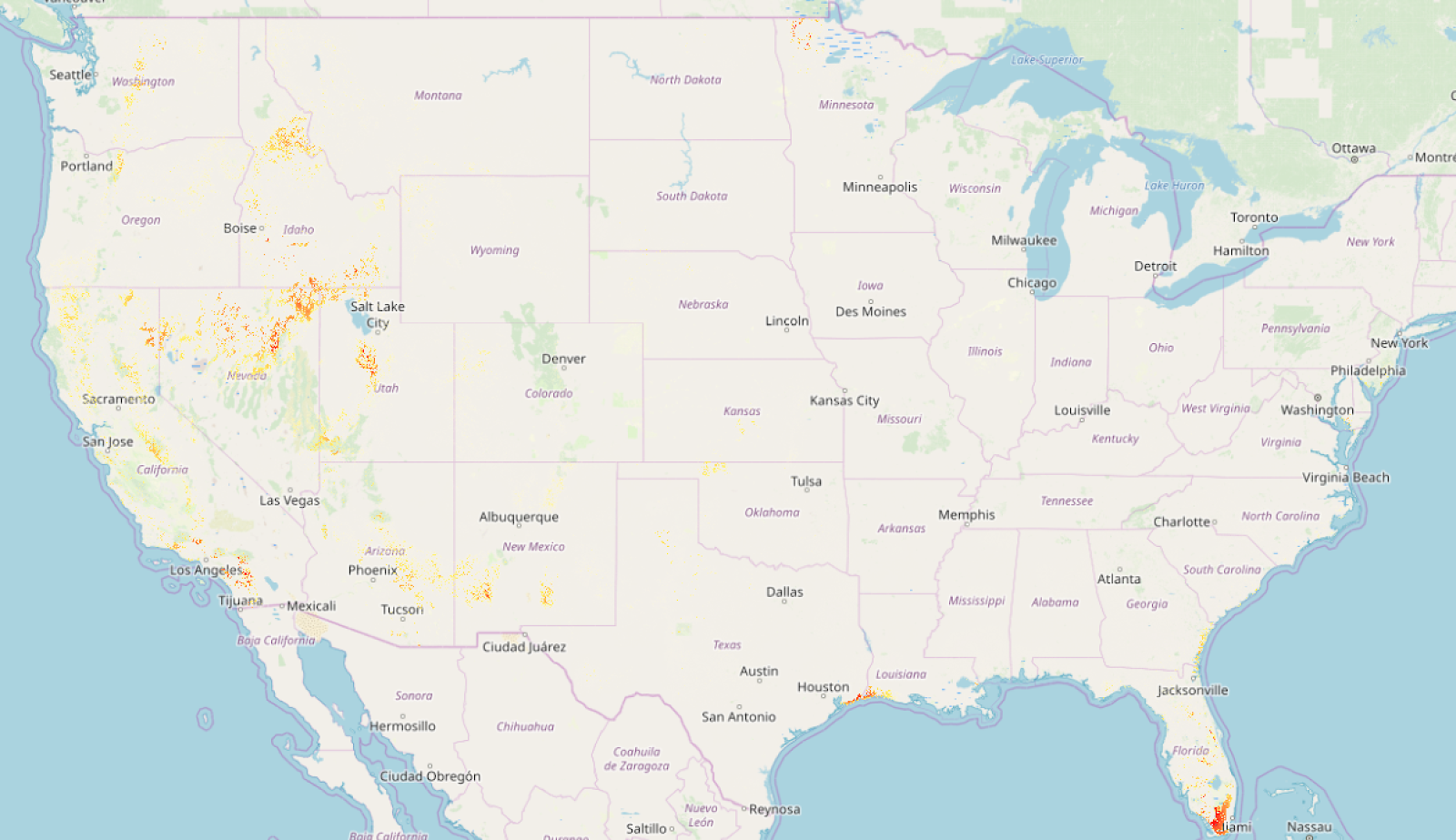
The most useful data-source I found for wildfire risk was this USDA-sourced raster data of overall 2018 wildfire risk, at a pretty fine gradient level. I pulled this into QGIS:
(I’m using the continuous WHP from the site I linked). Just to get a sense of what the data looked like, I did some basic styling to make near-0 values transparent, and map the rest of the values to a familiar color scheme:
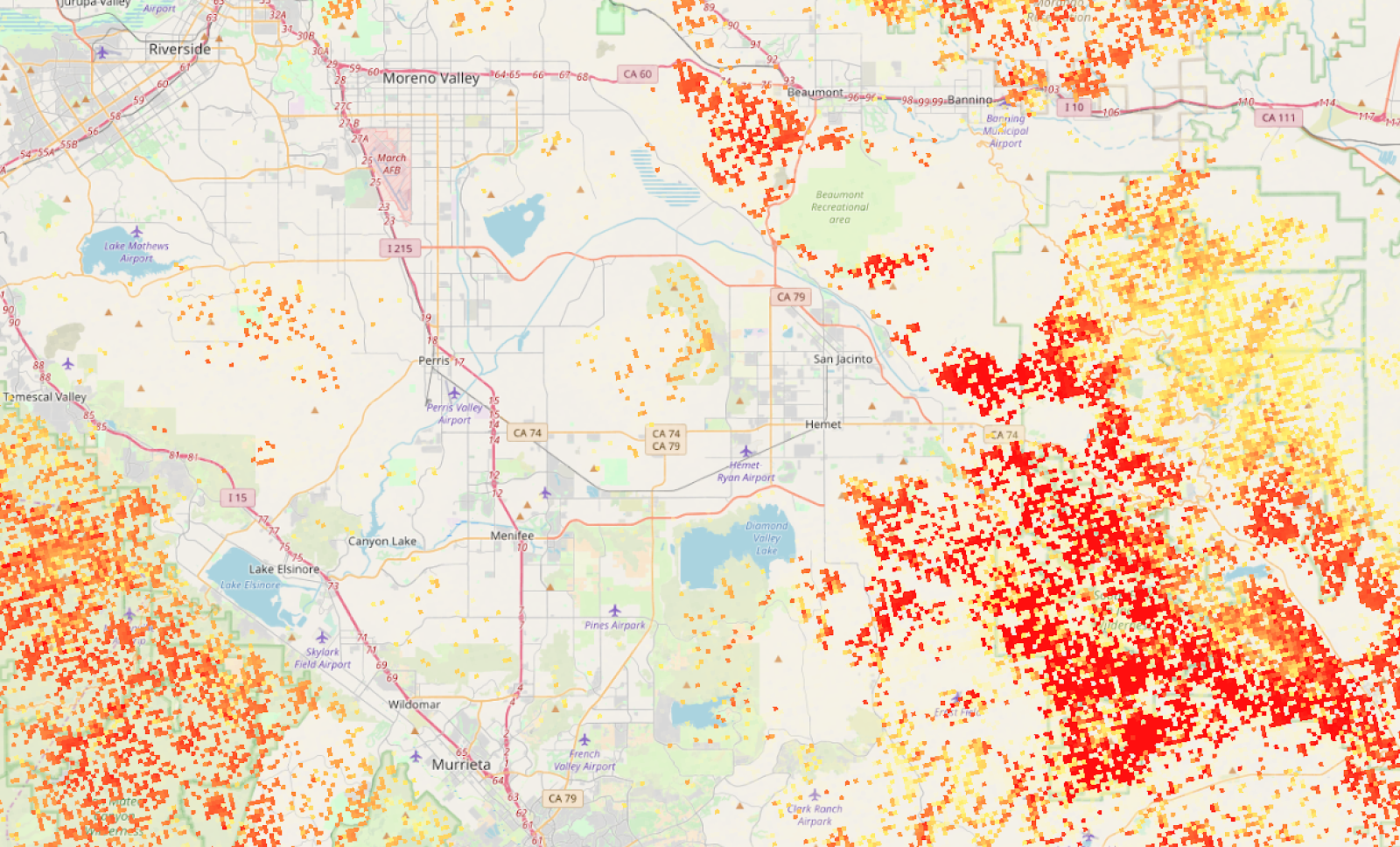
This actually looks pretty good as a high-level view, but the data is actually super grainy when you zoom in (which makes sense — the data was collected to show national maps):
This is a bit grainy to display as-is at high zoom levels. Also, raster data, although very precise is (1) slow to load for large maps and (2) difficult to work with in the browser — in MapBox I’m not able to remap raster values or easily get the value at a point (eg, on mouse click). I wanted this data available as a vector layer, and I was willing to sacrifice a bit of granularity to get there.
The rest of this post will be me getting there. The basic steps will be:
Filtering out low values from the source dataset
Using a very slow, wide, Gaussian filter to “smooth” the input raster
Using the raster calculator to extract discrete bands from the data
Converting the raster to polygons (“polygonalize”)
Putting it together and styling it
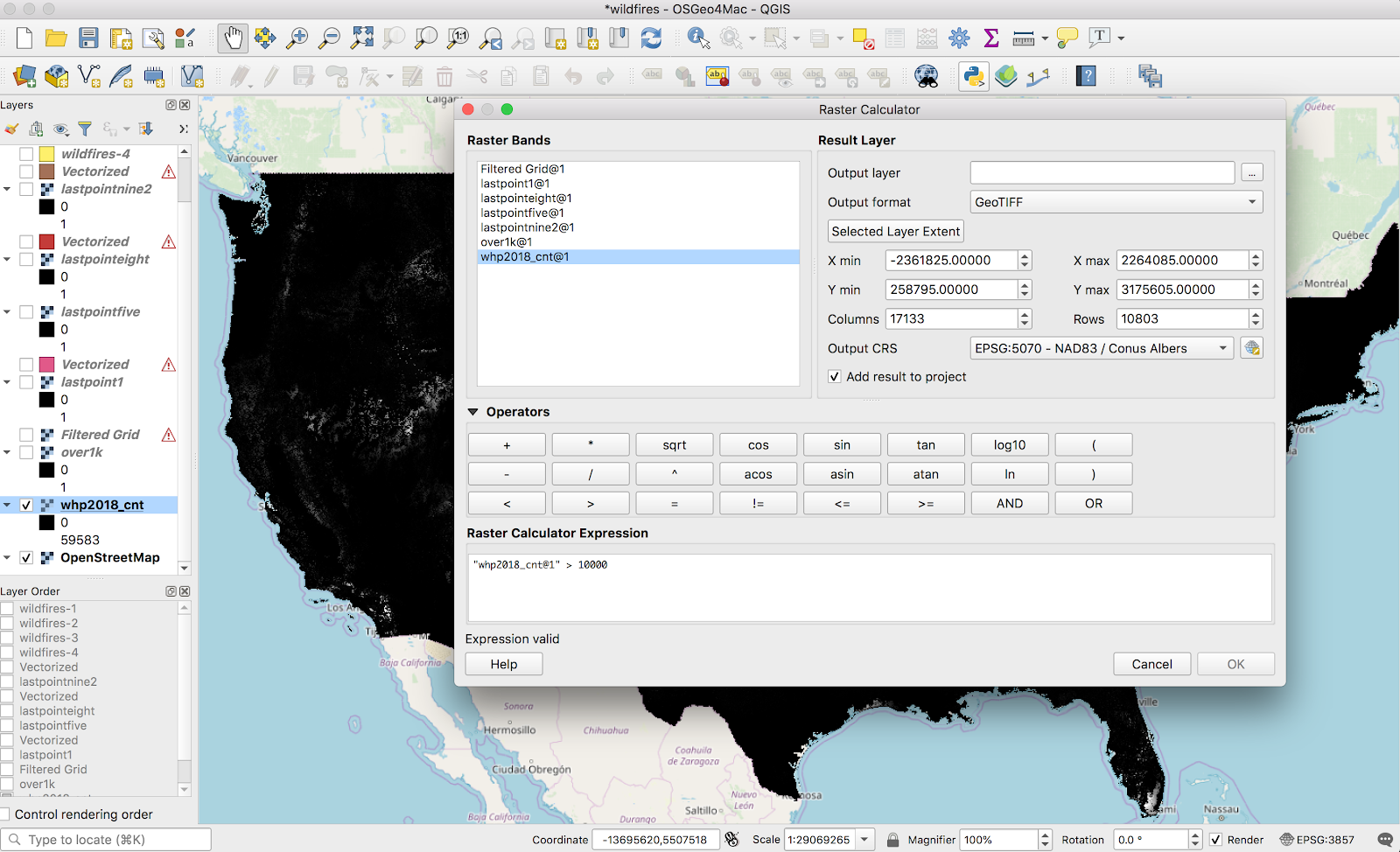
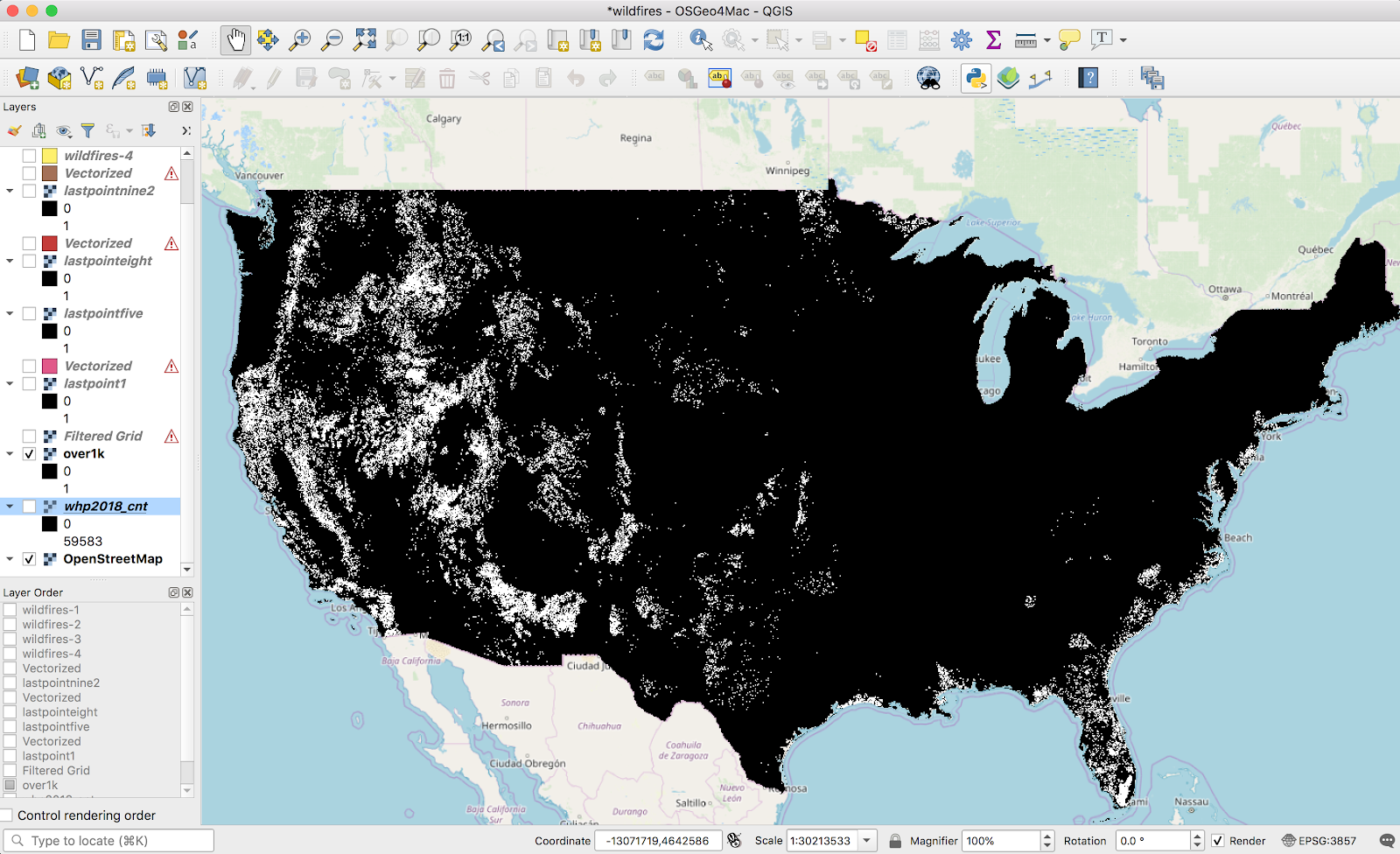
The first thing I did was filter values out of the original raster image below a certain threshold using the raster calculator. The only justification I have for this is “the polygonalization never finished if I didn’t”. Presumably this calculation is only feasible for reasonably-sized raster maps:
(I iterated on this, so the screenshot is wrong: I used a threshold of 1,000 in the final version). The result looks like this:
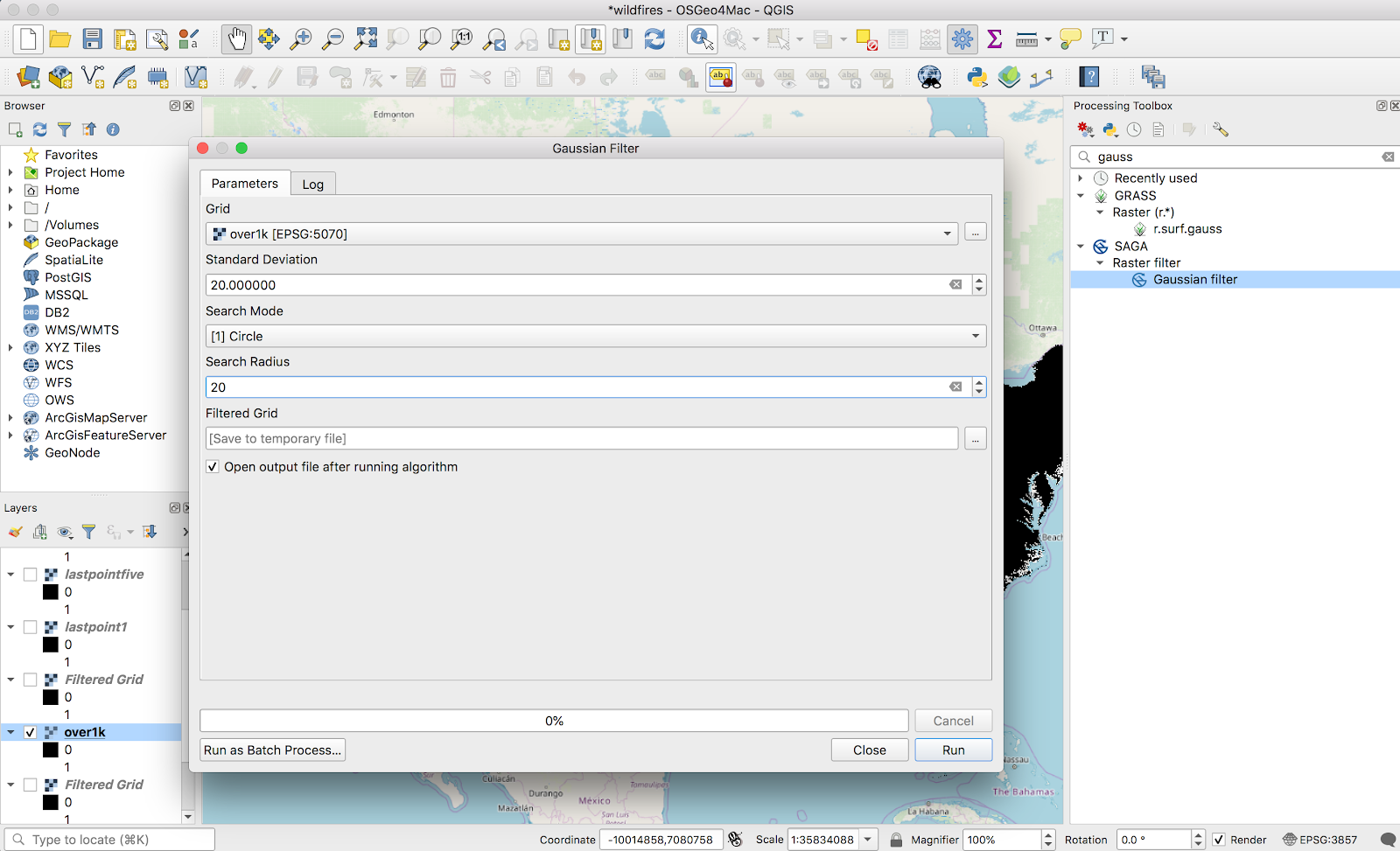
Next step is the fancy new tool — the Gaussian filter. A Gaussian filter, or blur, as I’ve seen elsewhere, is kind of a fancy “smudge” tool. It’s available via Processing → Toolbox → SAGA → Raster filter.
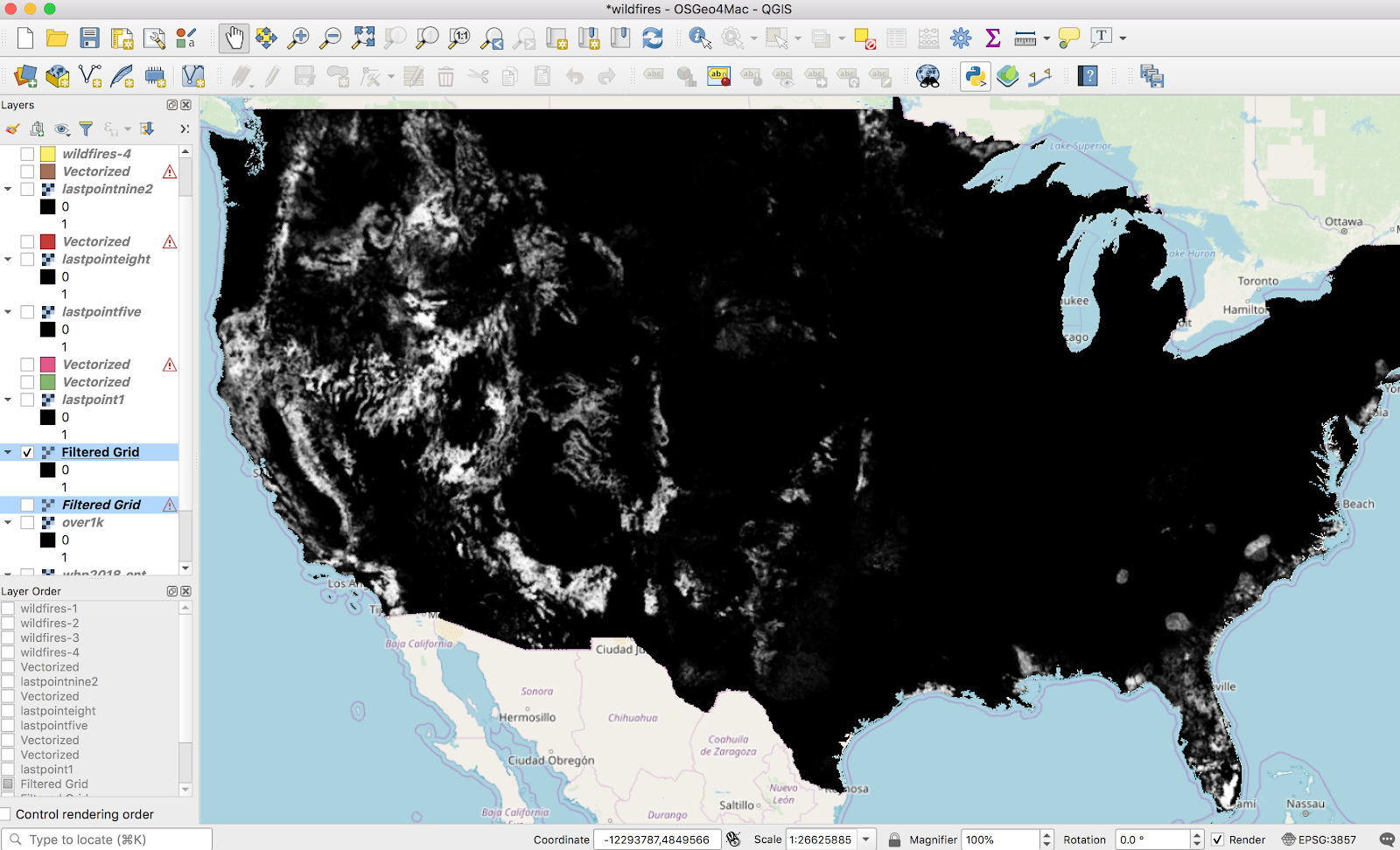
This took forever to run. Naturally, the larger values I used for the radius, the longer it took. Iterated on the numbers here for quite a while, with no real scientific basis; I settled on 20 Standard Deviation and 20 search radius (pixels), because it worked. There is no numerical justification for those numbers. The result looks like this:
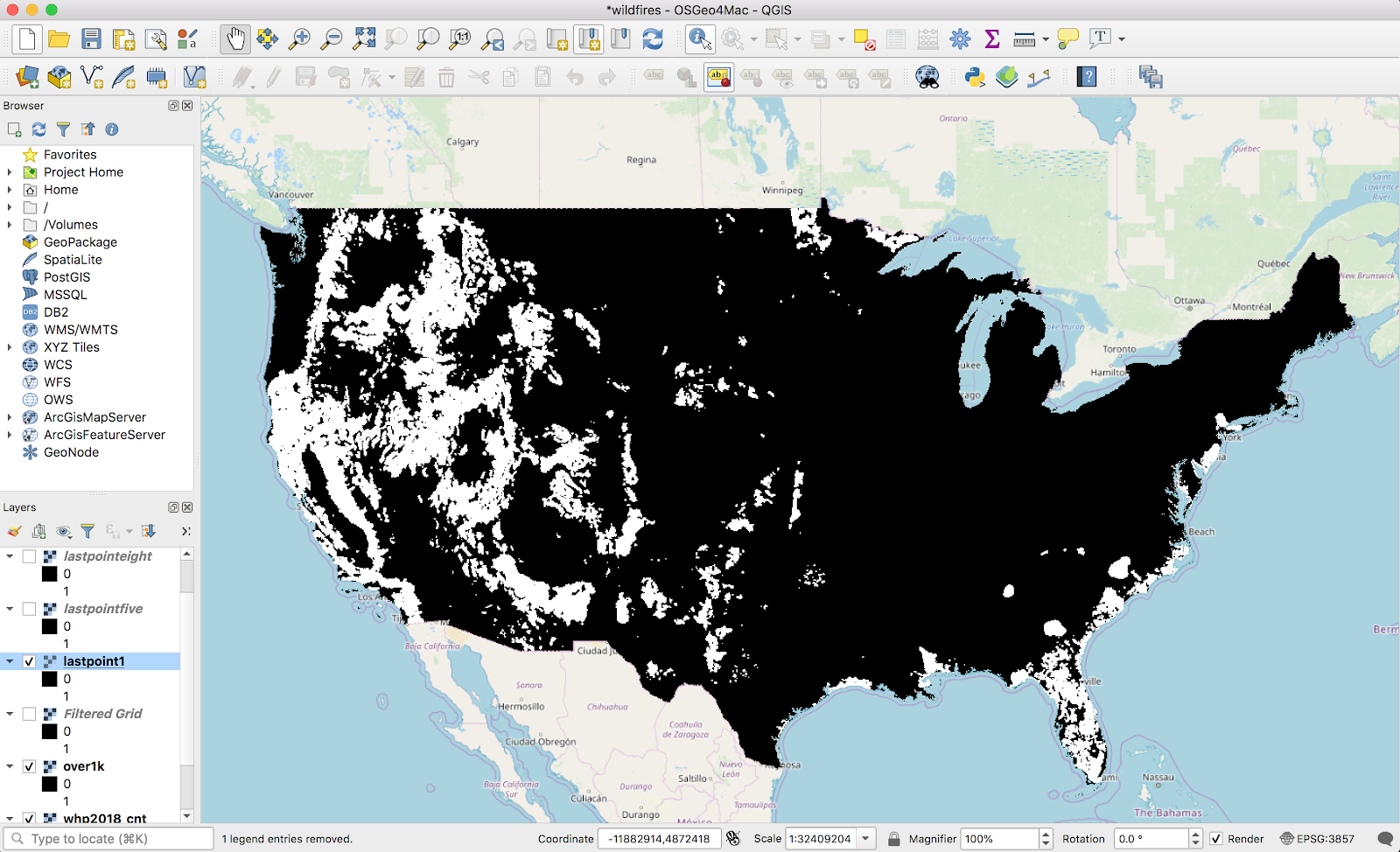
Now, we can go back to what I did a few weeks ago — turning a raster into vectors with the raster calculator and polygonalization. I did a raster calculator on this layer (a threshold of .1 here, not shown):
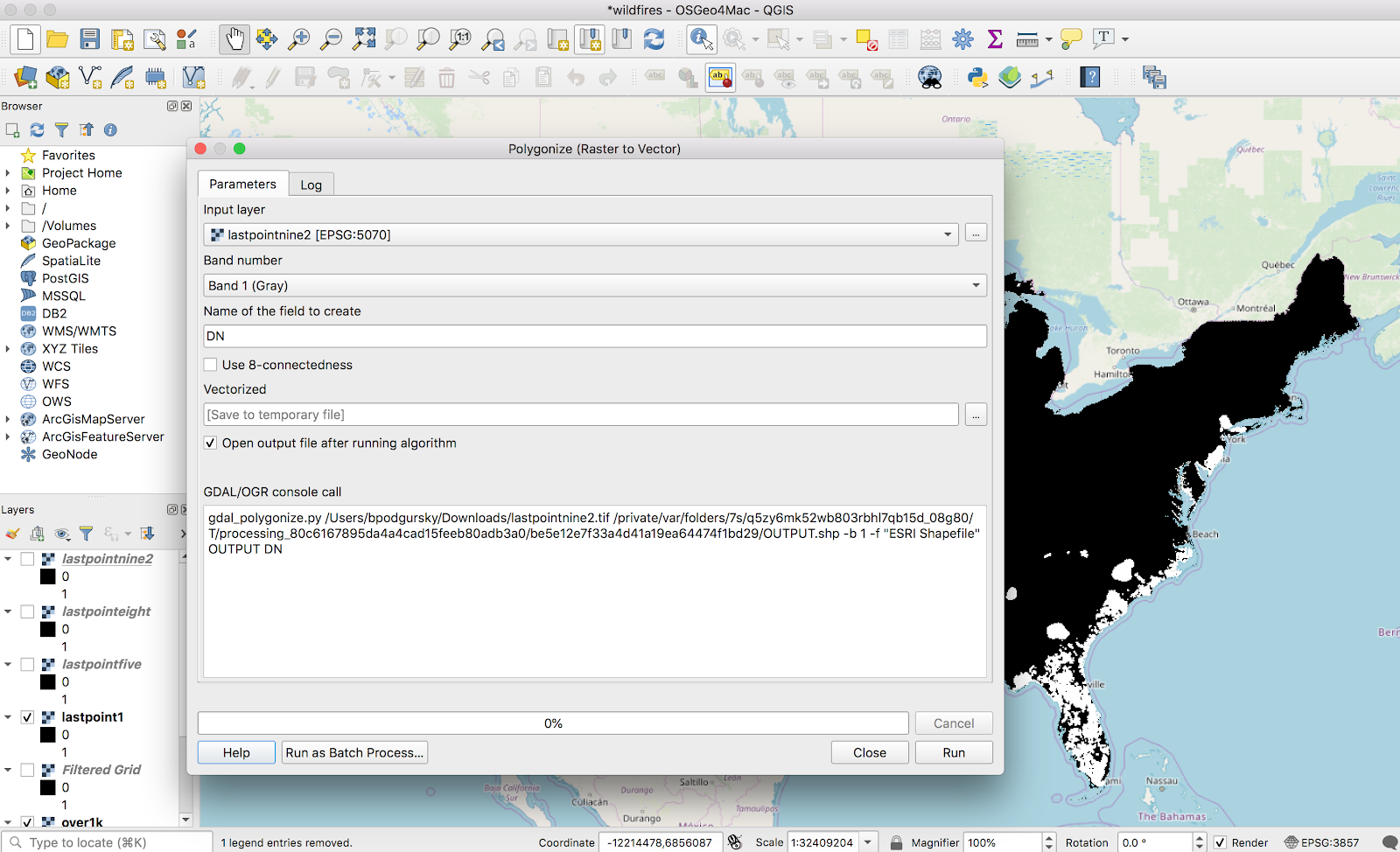
These bands are actually continuous enough that we can vectorize it without my laptop setting any polar bears on fire. I ran through the normal Raster → Conversion → Polygonalize tool to create a new vector layer:
This looks like what we’d expect:
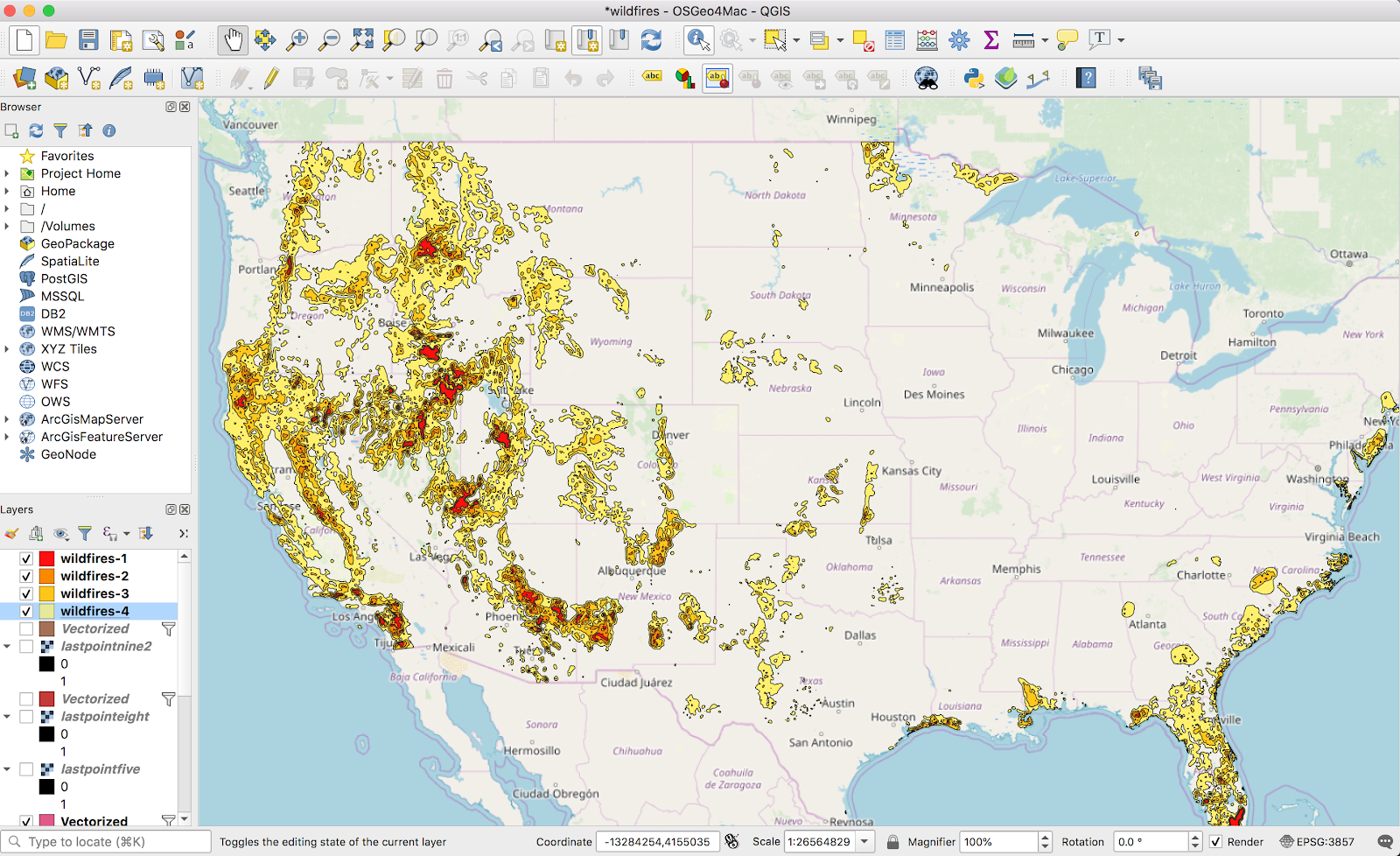
Fast forward a bit, filtering out the 0-value shape from the vector layer, rinse-and-repeating with 3 more thresholds, and adding some colors, it looks pretty good:
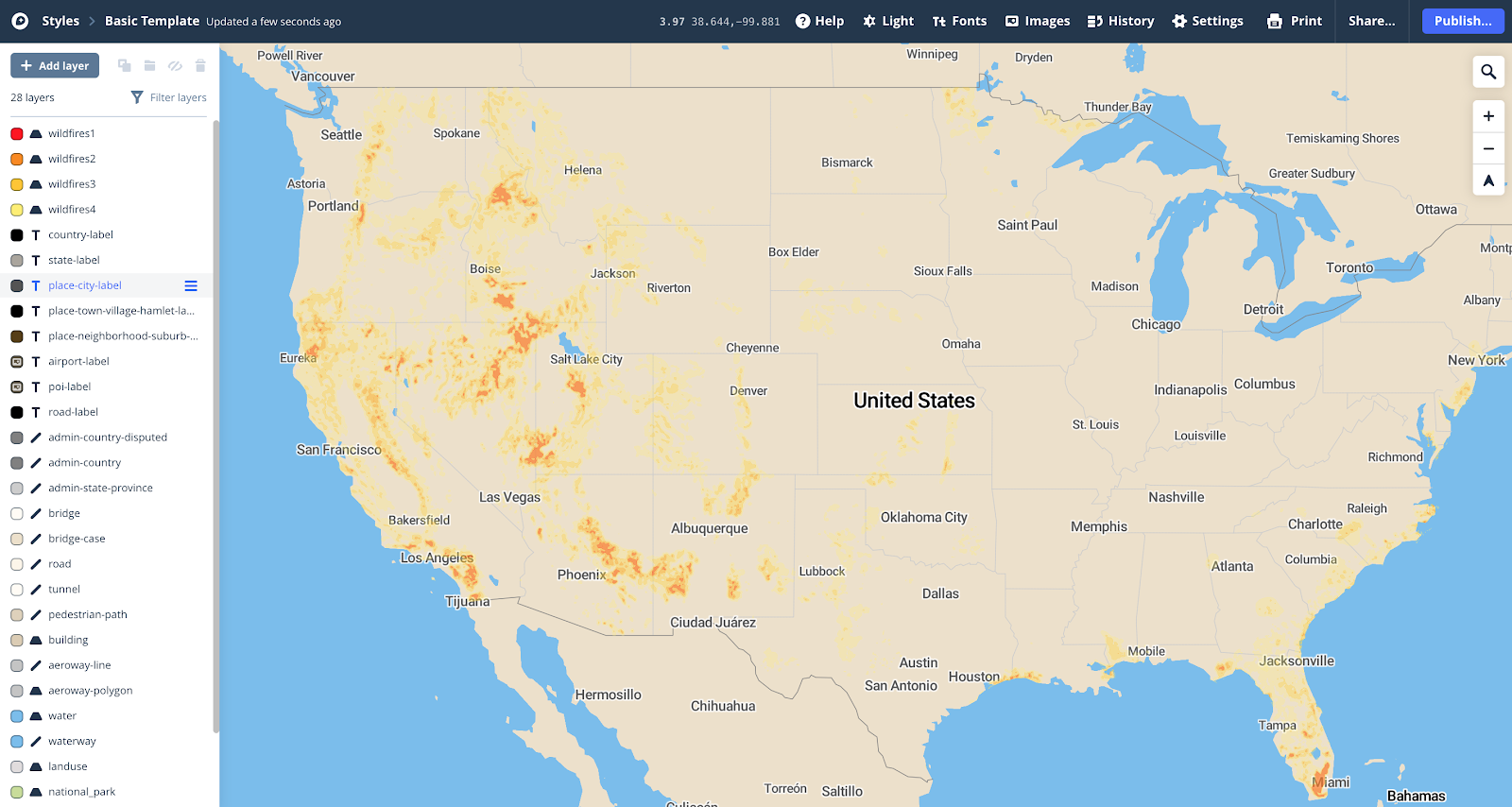
I want this on Mapbox, so I uploaded it there (again, see my older post for how I uploaded this data as an mbtiles file). Applied the same color scheme in a Style there, and it looks nice:
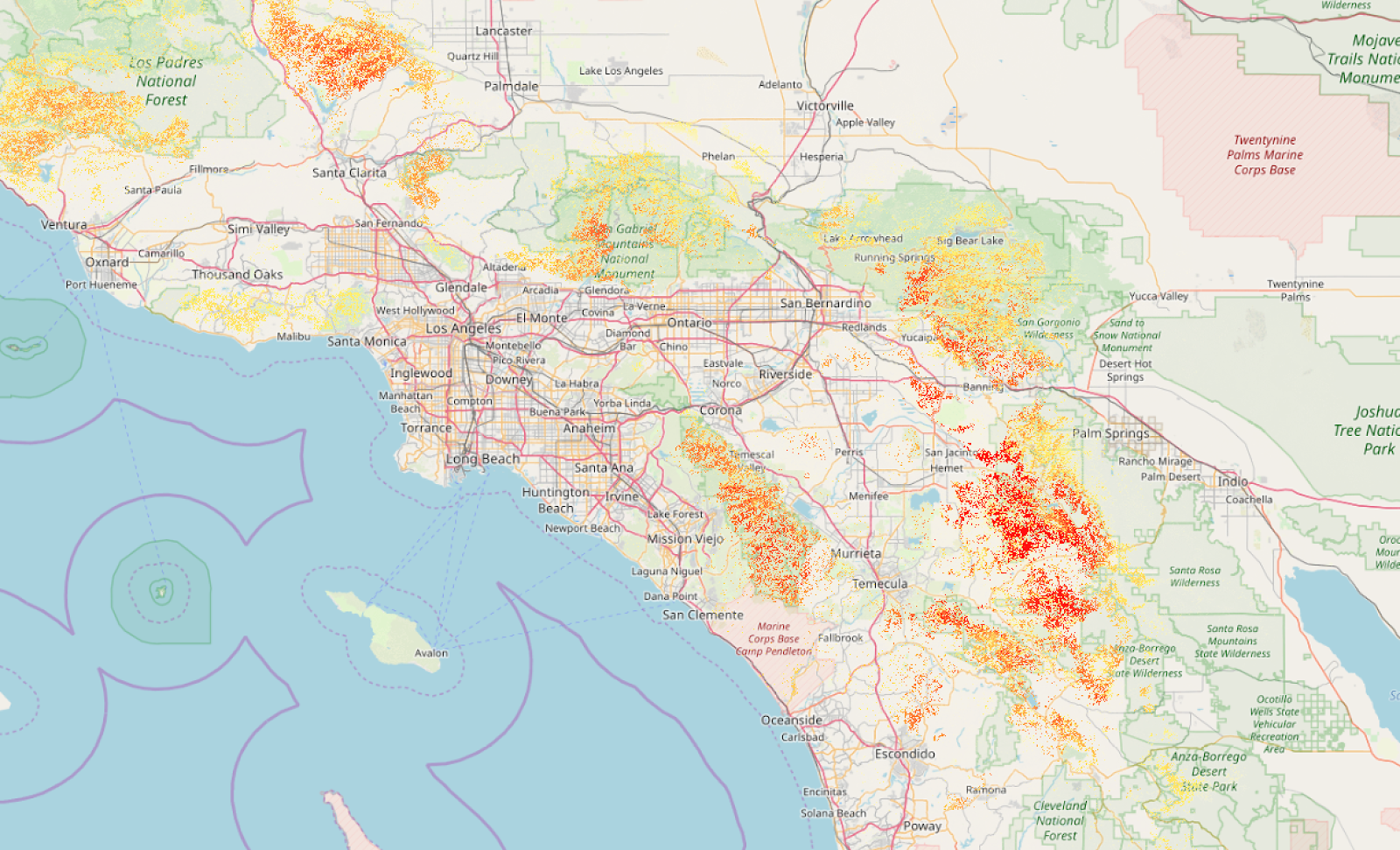
Just as a summary of the before and after, here is Los Angeles with my best attempt at styling the raw raster data:
You get the general idea, but it’s not really fun when you zoom in. Here’s it is after the Gaussian filter and banding:
I found these layers a lot easier to work with, and a lot more informative to the end user. It’s now visible as a layer on bunker.land.
I thought this tool was nifty, so hopefully this helps someone else who needs to smooth out some input rasters.
(warning: this all is probably obvious to people who know Firebase, but I didn’t see any direct references to this feature, so I figured I’d write it up)
Over the past few weeks I’ve been learning my way around Firebase; I use it to host my current side-project, a webapp (bunker.land), which uses Mapbox GL JS to render an interactive map of natural disasters, nuclear targets, and the like.
Today I took a shot at adding a convenience feature; during the initial page load, I wanted to zoom to the user’s actual location, instead of just defaulting to the center of the US. Mapbox and Firebase have made this project stupidly easy so far, so I was optimistic this would also be easy.
Precise geolocation is certainly possible through Mapbox GL JS, but I’d have to use the actual browser location APIs; those require permissions, which is a noisy user-experience if it happens during initial page-load:
(and frankly, people have no reason to give my random webapp their location. I’m not that important.)
A lighter-weight version of geolocation would be to just geo-locate based on the user’s IP address. IP geolocation isn’t very accurate — IP addresses move around, so I’m not going to get more precision than a city. For my purposes, that’s fine. And unlike real location, I don’t have to get permission to see a user’s IP address.*
Mapping IP address to a location still takes a dataset and a bit of work though. A number of sites offer IP to location services, but I wasn’t really thrilled about creating an account with a location service, managing an API key, and giving my credit card to internet randos just for this convenience.
Luckily, I discovered an easier way: it turns out that even though I’m using Firebase and not AppEngine, all the AppEngine request headers are attached to my Firebase function requests. Among those is x-appengine-citylatlong, which is (more or less) exactly what I want.
So, I built a tiny Firebase function which does nothing except listen for requests and pipe the location back into the response so I can use it in Mapbox:
(this function ended up being pretty trivial, but I struggled for a bit because it wasn’t obvious (to me) how to directly return JSON from a Firebase function. Firebase functions are (rightfully) built around the idea of returning Promises, because most Firebase functions proxy async services — storing data in database, putting it on GCS, etc. It’s pretty unusual that a function is able to do what I do here — respond immediately, based only on the headers.)
Anyway, this function does exactly what I want it to do; it returns the coordinates of the request:
On the Mapbox side, we can use this to flyTo the coordinates as soon as the map is loaded:
// wait until the map is loaded
map.on('load', function () {
// fetch the user coordinates from firebase
var getCoordinates = firebase.functions().httpsCallable('getCoordinates');
getCoordinates({}).then(function (result) {
if (result.data.coords) {
let latLong = result.data.coords.split(",");
// note that lat/long are reversed in appengine
map.flyTo({
center: [
parseFloat(latLong[1]),
parseFloat(latLong[0])],
zoom: 11
});
}
});
})
Really, that’s it. I’ve plugged a slightly more complicated version of this code into bunker.land, and now it zoom to (roughly) the user’s location after the map loads. With this trick, the geolocation is easy, cheap and simple, my favorite kind of trick : )
* do not try to teach me about GDPR. I do not care.
I posted a couple days ago about how I used QGIS to generate heatmaps of tornado activity based on raw point data. Since I had invested time (kind of) learning the tool, I figured I should put together a few similar layers.
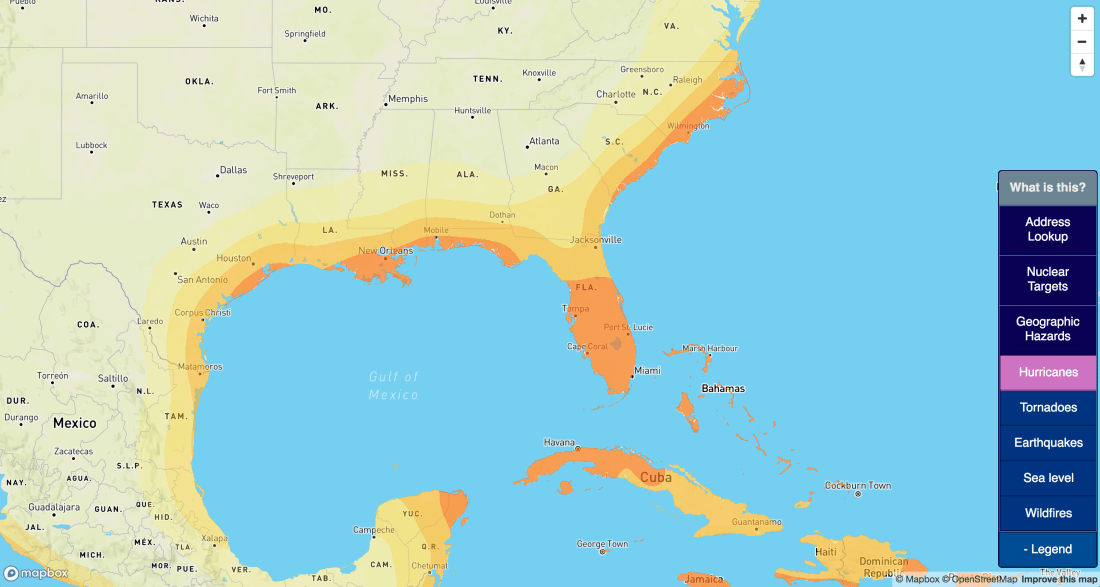
The most obvious choice was hurricane risk. I ended up using a pretty similar procedure to when I generated the tornado heatmap, but massaging the data took a few extra steps:
The input data came as vectors instead of points
My data covered the whole globe, but I wanted the final vectors to only cover land areas
Again, I was happy with the result, so I figured I’d write it up.
Similar to what I ran into with the tornado risk data, I couldn’t find any hurricane hazard GIS shapefiles. I did again find a raw dataset of all hurricanes the NOAA has records on, which was enough to get started.
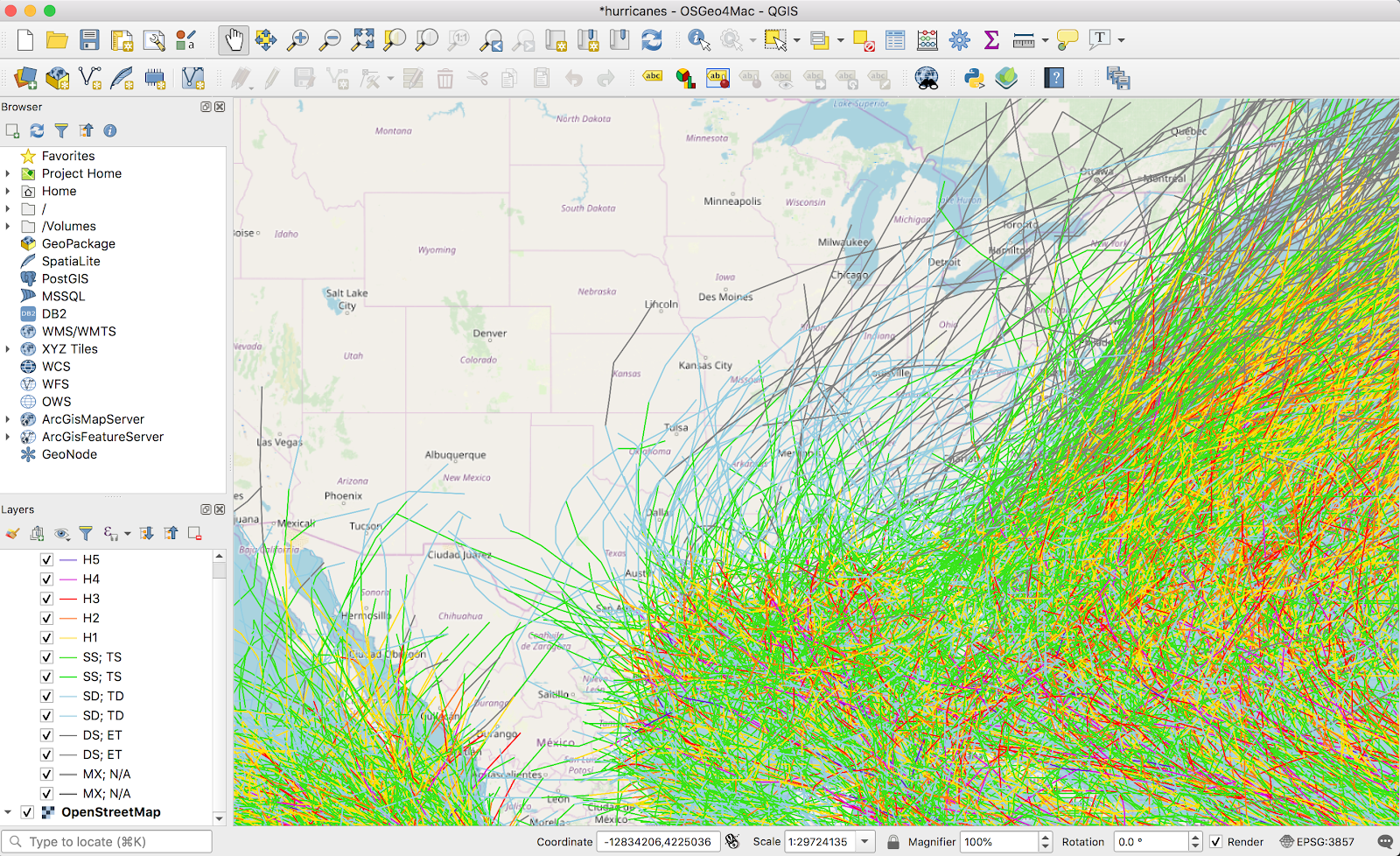
Importing all the vectors (I think there were about 700,000) from this MapServer took a while, and the result was, as expected, a bit cluttered:
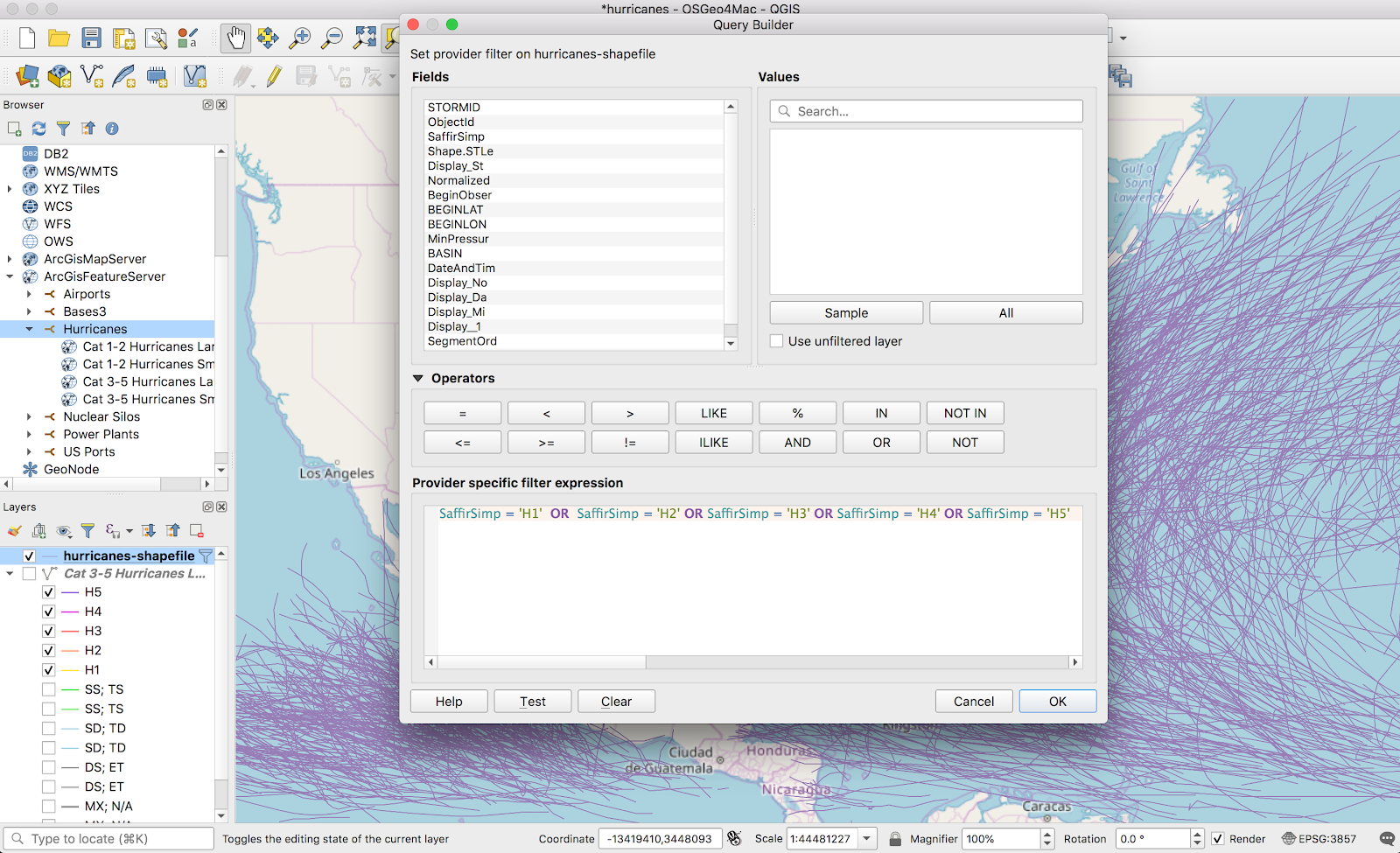
There’s probably a better way to filter the data down, but I ended up exporting the records to shapefiles so I could filter on attributes. The dataset had a lot of tropical storm data, and I filtered out everything except proper hurricanes (H1-H5).
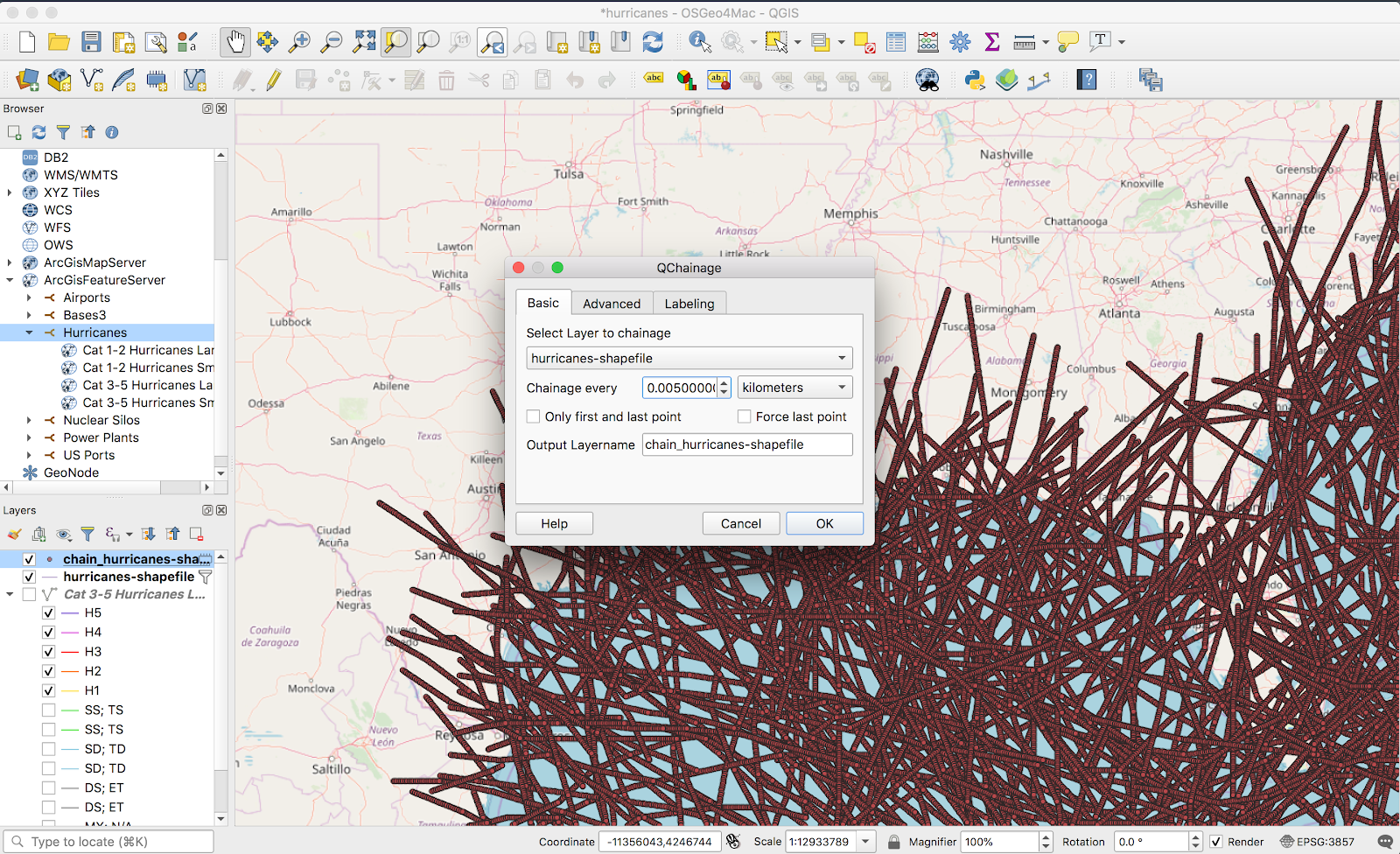
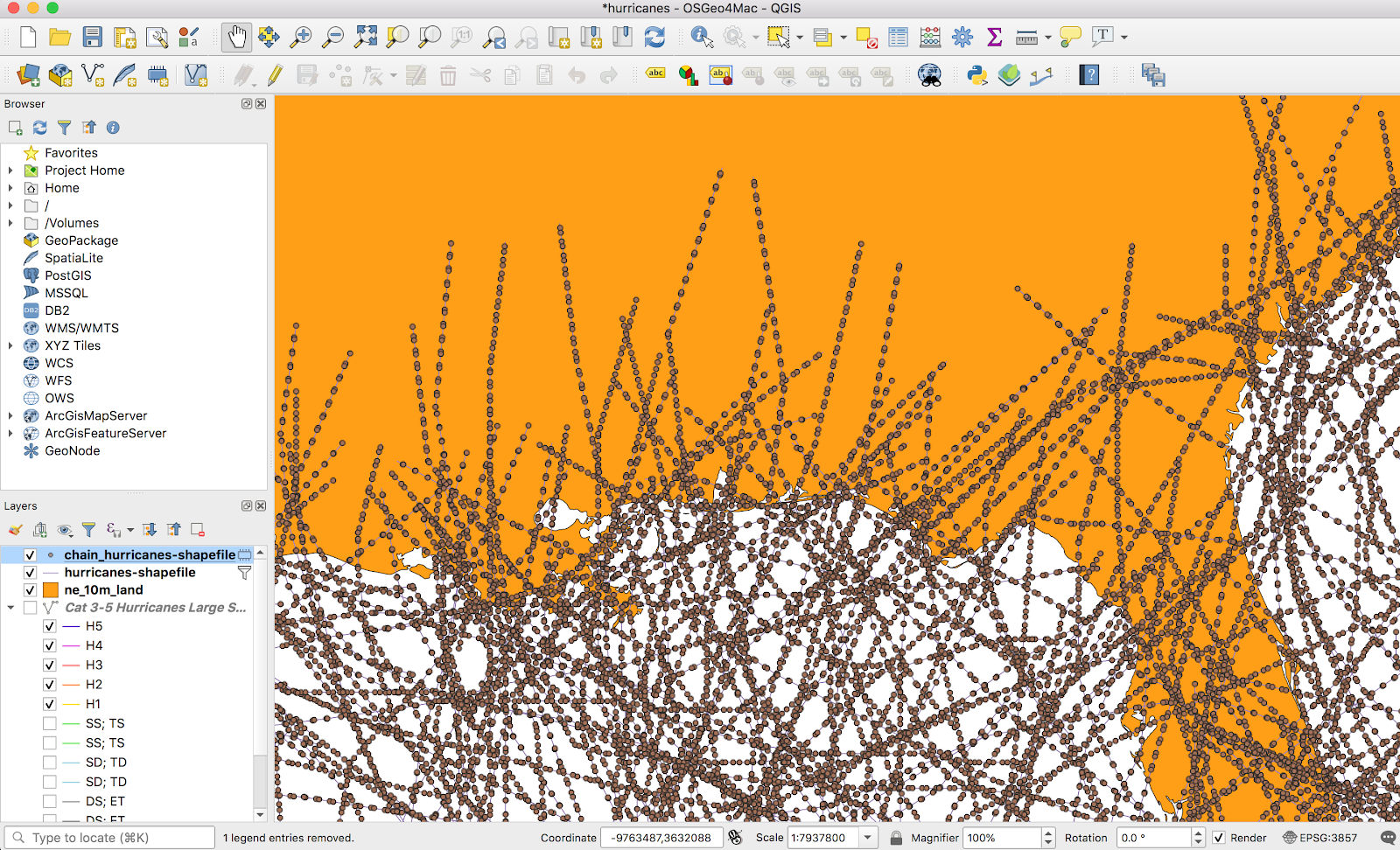
Here things got a bit different. The heatmap function I used for tornadoes only works on points, and these vectors were all lines. Luckily, there was a brute force but straightforward solution: turn the line into a bunch of points. QChainage is a simple plugin that does exactly that. Once it’s installed, it’s available from the Vector → QChainage menu.
The above screenshot is a bit deceptive — I ended up using a point spacing of 20km in the final version. The only main downside of a higher frequency is longer processing time when generating the heatmap. The result kind of looks a mess from above:
But looks a lot better once I zoom in:
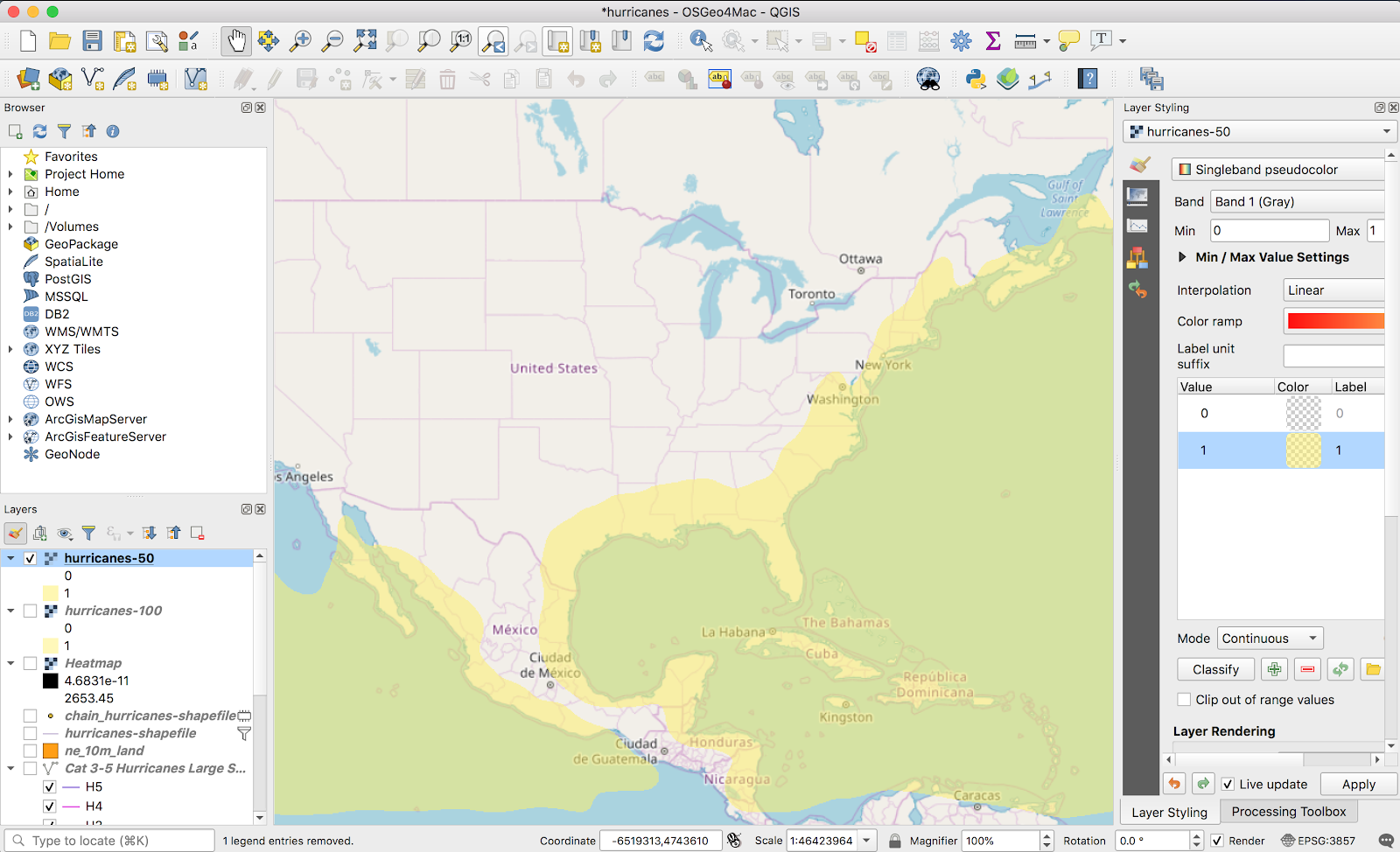
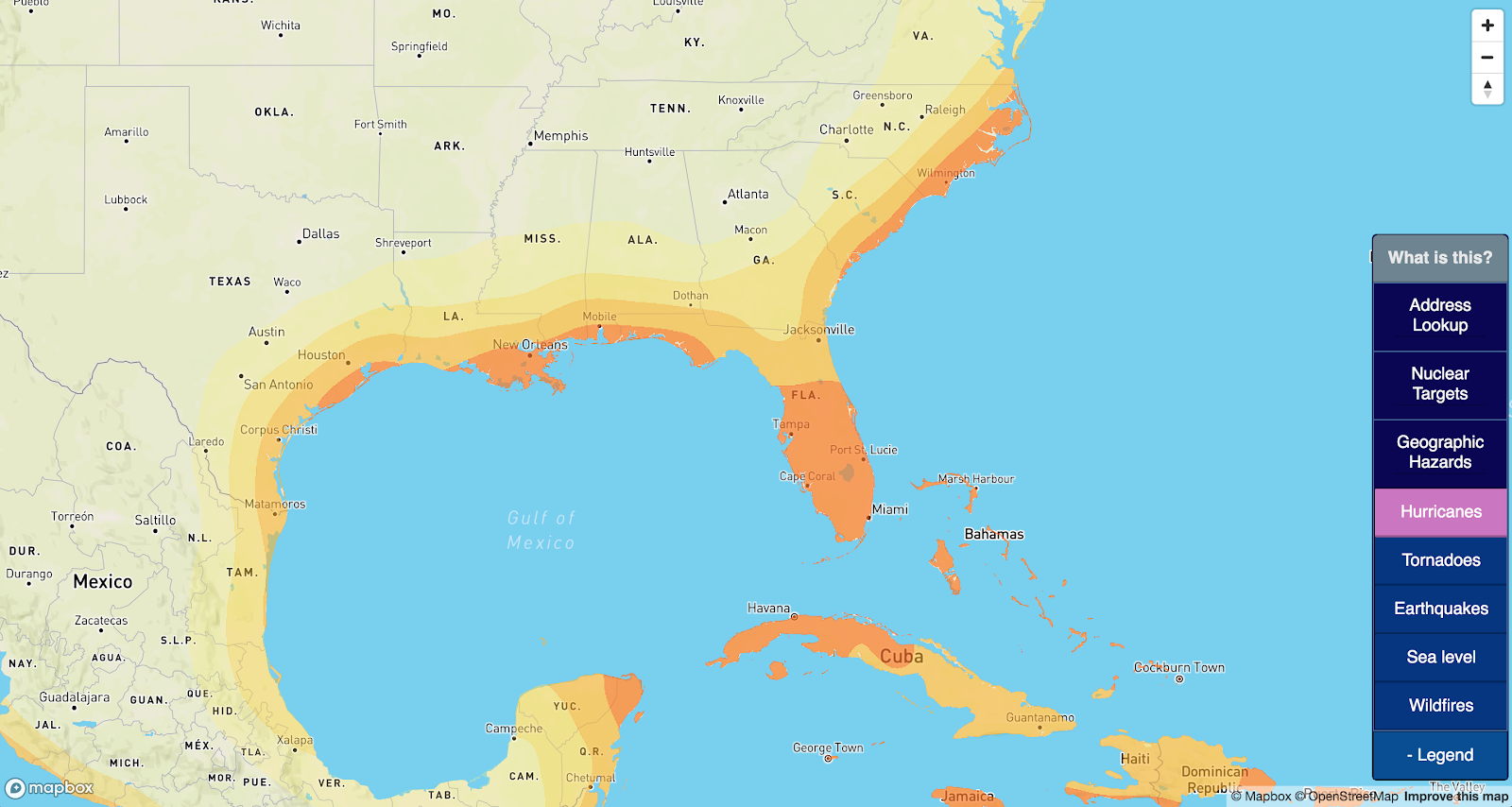
From here, I’ll fast forward through the same stuff I did last time; I used the points to generate a heatmap, this time using 250km point radii, and pulled a vector out of it. I iterated on thresholds until the most expansive layer more-or-less lined up with other reputable sources. My layer:
Except for a few lumps in Virginia and Maine, it looks pretty comparable.
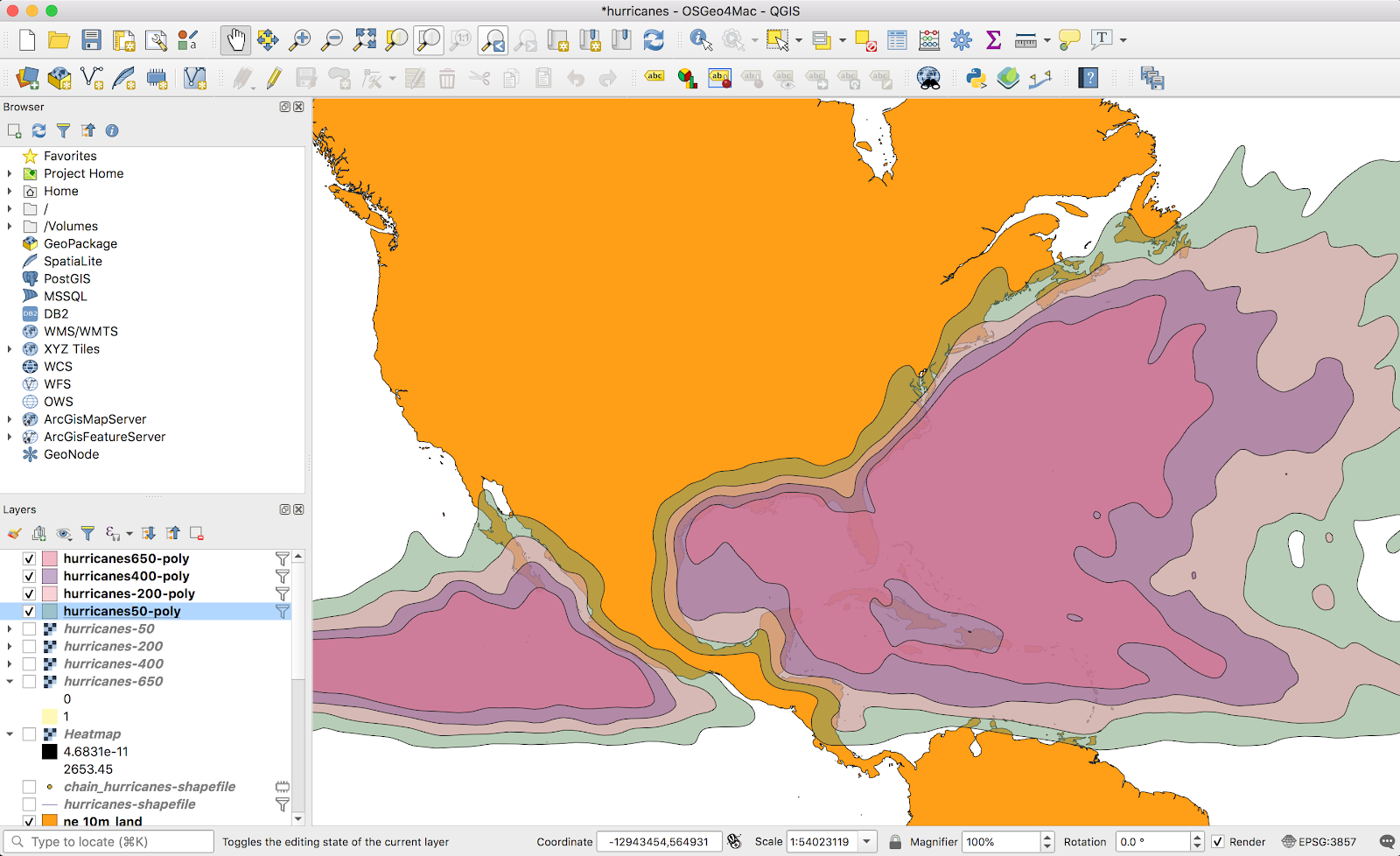
Jumping forward a bit more, I again went with four gradients to get a map that looked like this:
I was a bit torn. While this looks cool, the highlights on the ocean are distracting when the goal is to highlight risk areas on land; I needed to filter the shapes down to only land areas.
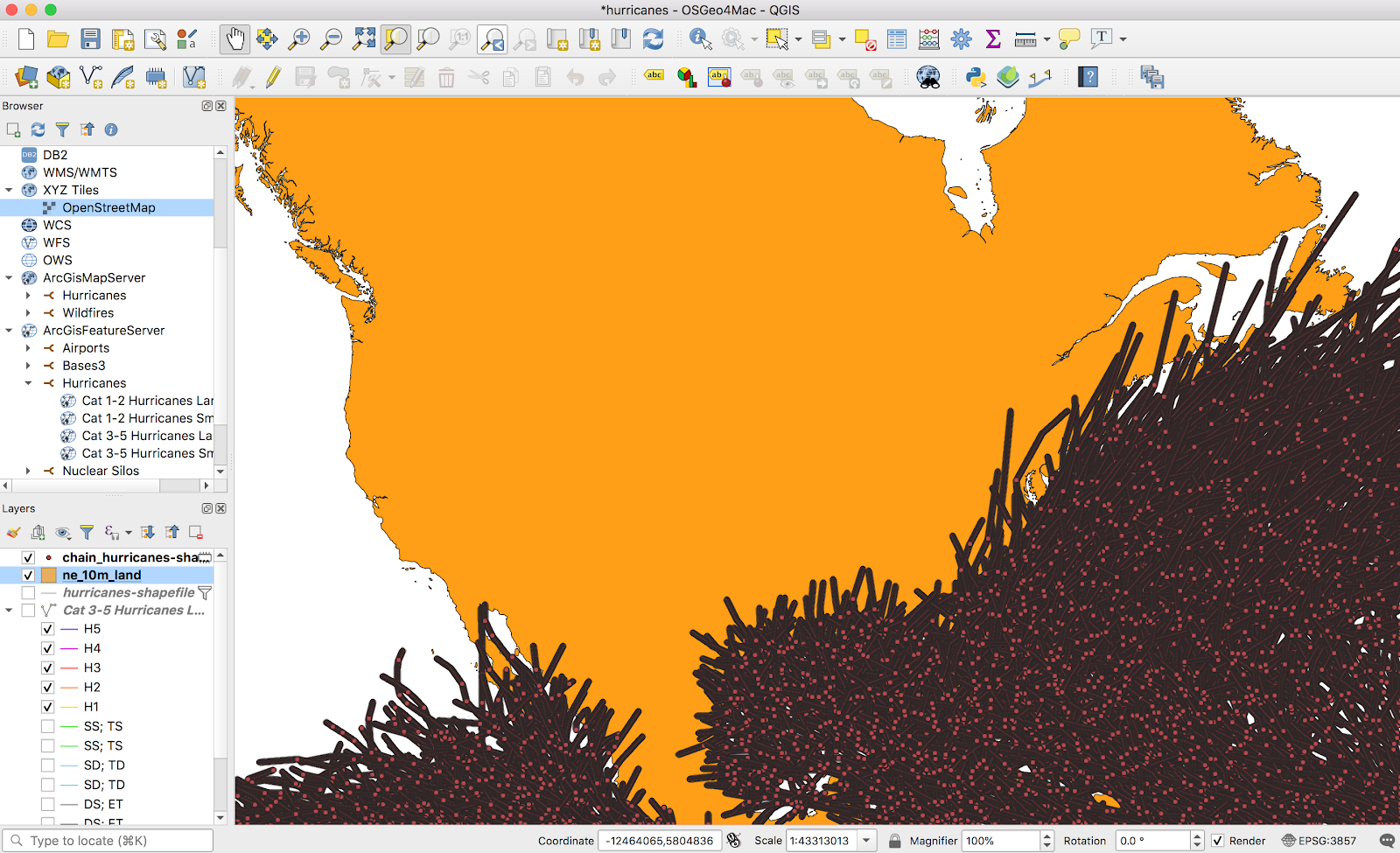
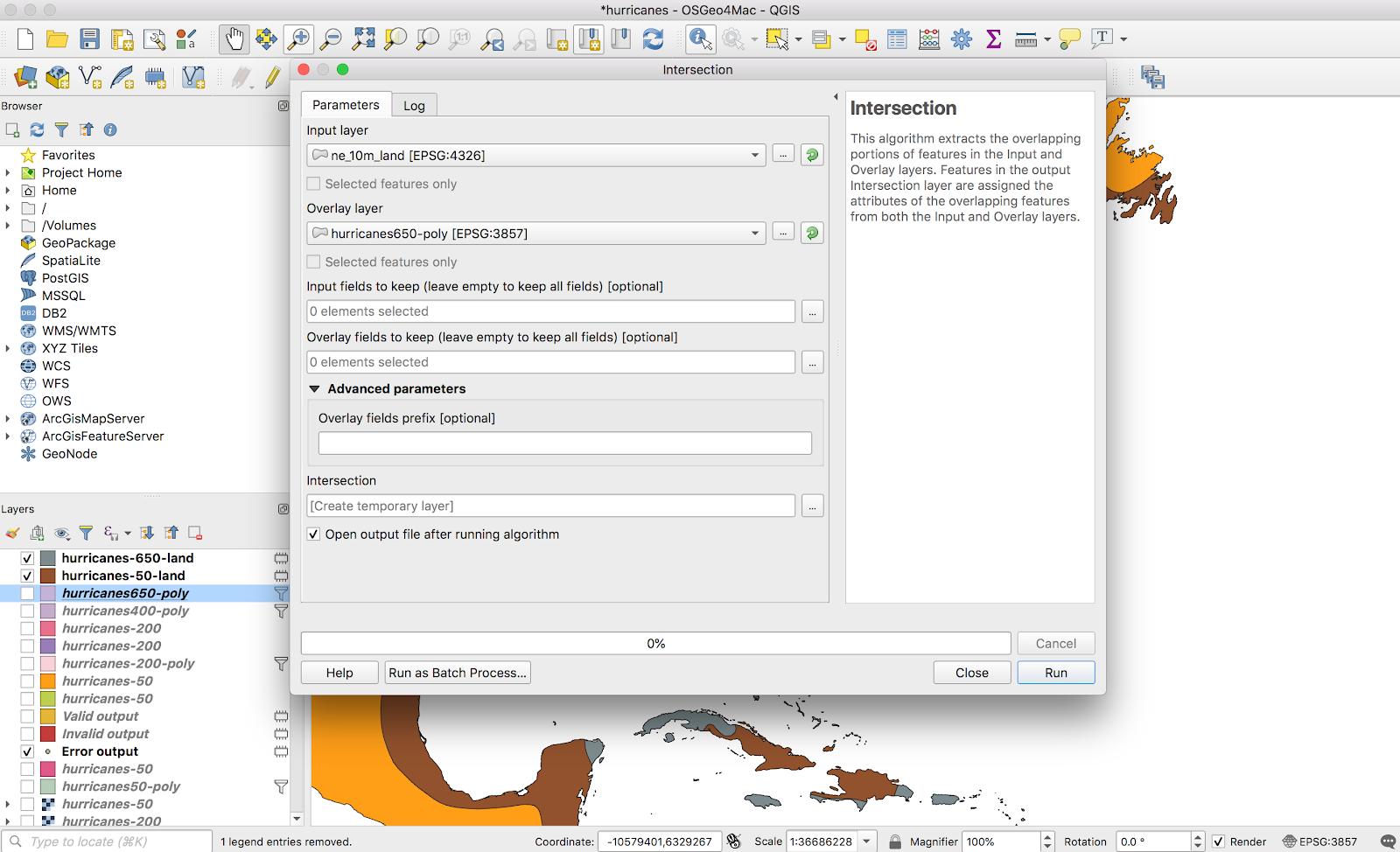
It turns out, intersecting vectors in QGIS is pretty easy. I found a simple shapefile of all land areas on earth here (it wasn’t even a big download — less than 10MB). Once this data was imported, I could use the Vector → Geoprocessing tools → Intersect tool to generate an intersection layer:
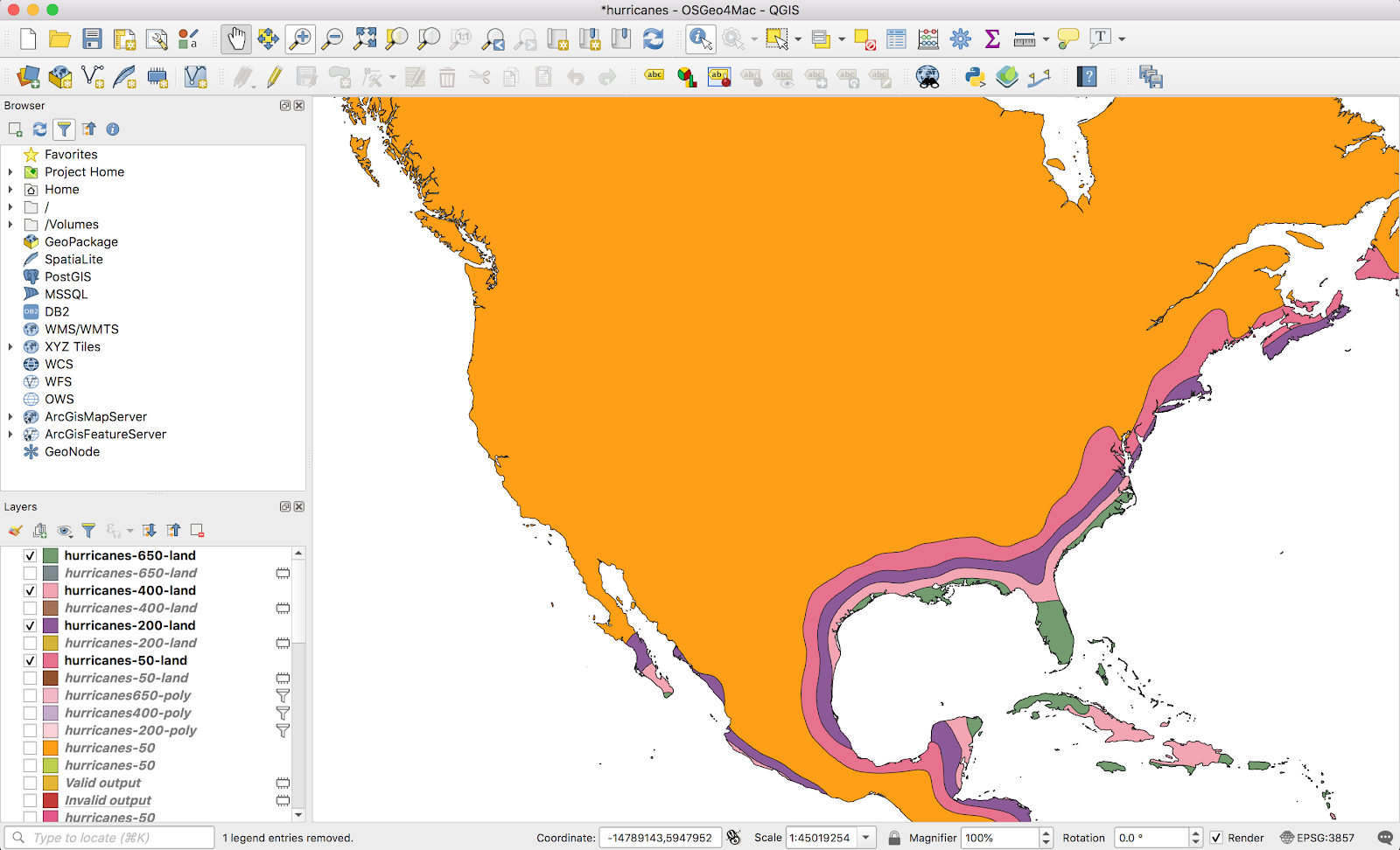
This did exactly what I wanted. I repeated this for all four layers and ended up with a gradient only over land areas, exactly what I wanted. I didn’t bother styling the layers, since I’ll just handle that in Mapbox later.
Just as a sanity check, I swapped back in the openmaptiles background to make sure the coastlines lined up correctly (they did, except a few hundred meters here and there on the coastline).
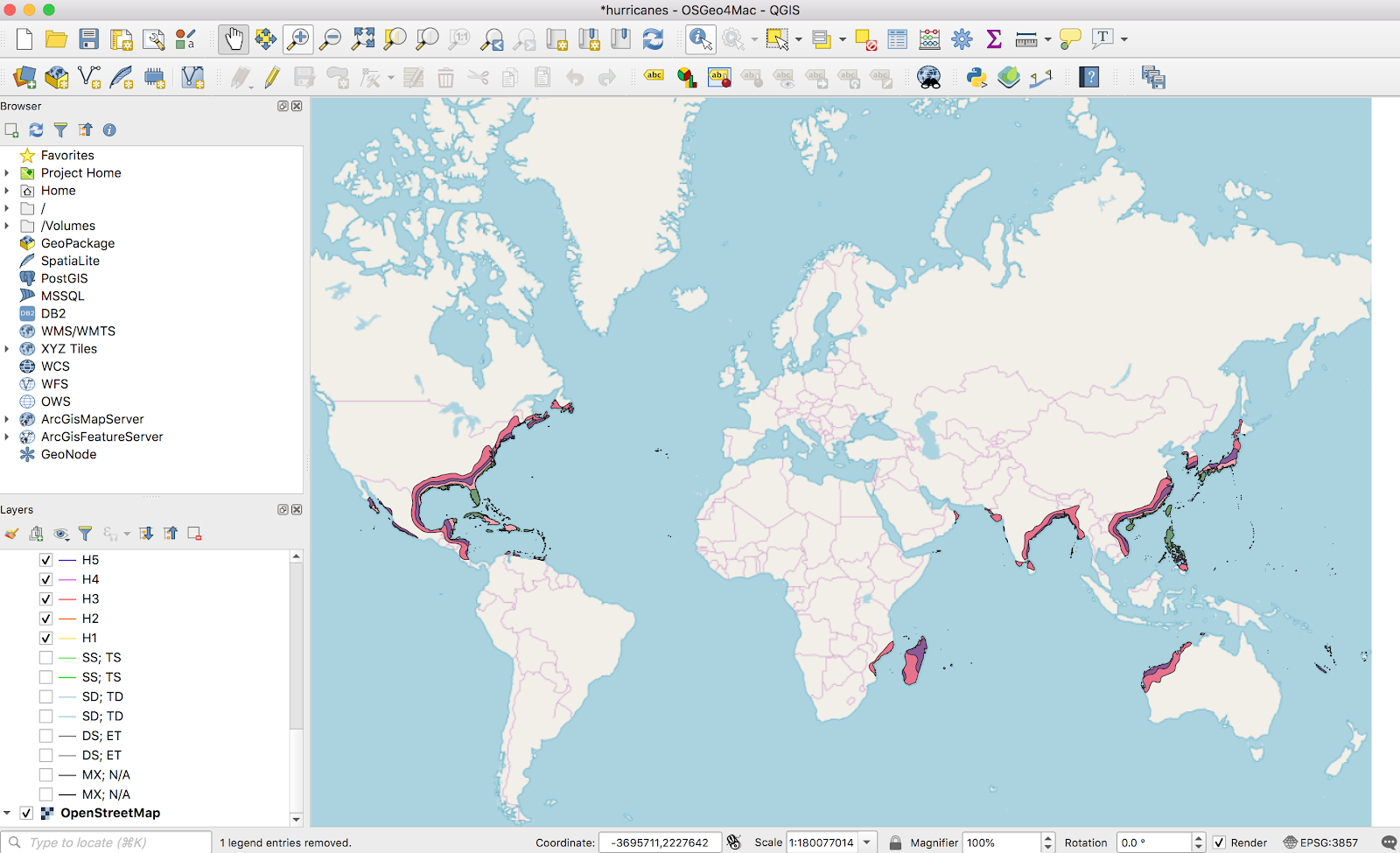
A nice bonus from this NOAA data: this time the data covered the whole globe. All the other datasets I’ve found for other natural disaster risks are US-specific (and usually only the continental US):
I won’t go through the details on loading this into Mapbox; everything from here mirrored what I did last time. You can see the result as a layer on bunker.land:
Once again I was pleasantly surprised at how easy it was to get (relatively) nice looking graphics from QGIS with minimal experience.
At this point I’ve added data for most the layers I was interested in displaying (although I’m open to suggestions). I’ll likely get back to the actual web-dev side of this project and clean up a few loose ends over the next couple weekends.
I’ve spent the last couple weekends putting together bunker.land, which I posted about a couple weeks ago (the tl,dr is, “mapping out the riskiest places in the US to live”).
My focus has been on targets during a nuclear war, but I thought it would be fun to expand the project to include natural disaster likelihoods. I didn’t have too much trouble finding datasets for elevation (to model sea level rise), earthquakes, and wildfires. Tornado risk seemed like a good next step.
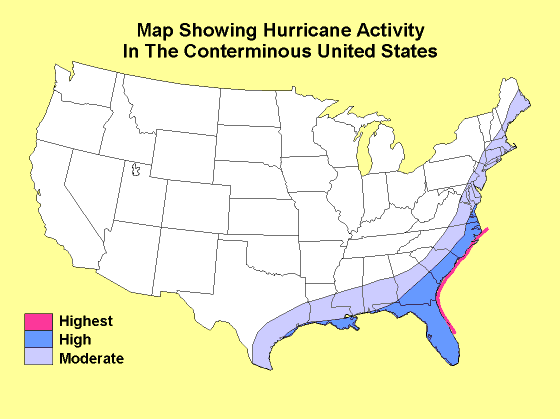
I wanted a map that looked something like this (source):
(aside: I grew up in the middle of Missouri, which according to this map, is literally the armpit of tornado alley. And yet in the 15 years I lived there, I never saw even one tornado, and I am pretty salty about this. Now I know why. More on this later.)
However, I needed the tornado hazard data formatted as GIS shapefiles or rasters so I could render it via Mapbox GL JS, the library I use to display webmaps. Sadly, I had a lot of trouble finding a GIS-formatted risk map for tornadoes The closest thing I found was a set of tornado starting points from 1950-2017. This is a comprehensive dataset, but when I pulled it into QGIS and mapped it out, the raw data was a bit… noisy:
Since I couldn’t find a map that worked out of the box, I had no choice but to learn something new. Luckily, I found a guide for making heatmaps in QGIS, which gave me a really good starting point. Less fortunately, the guide is for an old version of QGIS, and as a result I hit a number of obstacles I had to Google around.
I’m pretty happy with the result, and spent a fair amount of time learning how to use QGIS, so I figured I’d write up how I filtered this data into vector datasets and got it into Mapbox, where I display it as a layer on bunker.land.
Making a heatmap
Starting from the very beginning, we’ll want a new QGIS project. So we have some visual context when playing around with these shapes, I added an OpenStreetMap base layer. The tornado dataset we want to work with is available as shapefiles, and we can add that to QGIS via Layer → Add Layer → Add Vector Layer:
Our lives will be easier layer on if this data is all reprojected into EPSG:3857 – WGS 84 before we do any editing. We can just do that first. Right click on the layer → Export → Save Features As:
Set the CRS to WGS 84, save, and we can work with the new reprojected layer from now on.
So our first problem is that this dataset is huge and noisy. While I don’t recommend ignoring any tornadoes, I would not personally get off my couch for anything less than an F2 tornado, so that’s what I’m going to filter for. Since this data is a shapefile, I can filter on the fields of the objects; right click on the new layer → Filter.
We’ll just filter on the “mag” column, looking for F2+ tornadoes:
This is a bit less cluttered, but still not super actionable. From here, our goals are:
turn these points into a heatmap
extract discrete layers from the heatmap
save the extracted layers as shapefiles
Luckily for us, QGIS has a nifty heatmap tool which lets us turn our points into a heatmap raster. Click on Processing → Toolbox → Interpolation → Heatmap:
Iterating on the settings here took a while; I had to experiment before I found settings that looked good. I went with a 150km radius on the heatmap points, 4000 rows, and 10009 columns (once you select the number of rows, the columns auto-populate). I played around with the colors on the resulting heatmap for a bit and ended up with this:
Intensity bands
While this is an improvement, it’s still kind of a hot mess (pun intended). Heatmaps based on spotty data like this probably over-exaggerate the hotspots (there’s likely reporting bias, and we don’t want to overweight individual data points). I’d prefer to get discrete intensity bands. To get those, we can use the raster calculator: Raster → Raster Calculator:
Since our heatmap values are no longer really connected to any actual unit, choosing units was a bit of guesswork. Frankly, I just chose numbers that lined up with the risk areas I saw on other maps; the lowest gradient, 10, gives us this:
This is the kind of gradient band I’m interested in. Unfortunately, this is still a raster image. We really want shapefiles — we can do more interesting things with them on Mapbox and in the browser, and the data is dramatically smaller. Luckily, QGIS has tool to turn raster images into shapefiles: “polygonalize”. We can go Raster → Conversion → Raster to Vector:
We can select whatever we’ve named our filtered raster. This gives us the previous image broken into two chunks:
We want to filter out the part that falls below our heatmap threshold. Right click the layer → Properties → Filter:
Filter for where the feature value is equal to 1. Now we’re down to the shapes we care about:
Of course we can play around with the layer styling to get it to look like whatever we want:
To capture the gradients we care about, we can repeat this process at a few thresholds to capture distinct bands. These don’t correspond to any particular intensity, they are just intended to demarcate more and less intense risk areas.
Fast-forwarding the repetitive bits, I’ve repeated these steps with four raster calculator thresholds (with this dataset, I ended up using thresholds of 10, 25, 40, and 65). By setting a different color on each layer I’ve produced and decreasing opacity to 50%, I got this:
This captures what I want; distinct gradient bands without overly-weighting hotspots. If your goal is just to generate a static raster image, you can stop here and export this image directly.
Mapbox
My goal however is to import these layers into Mapbox so I can attach them to an existing interactive web map. Mapbox is a platform for hosting customized maps and embedding them in apps or webapps; I use Mapbox, plus the corresponding Mapbox GL JS library, to host maps for bunker.land. To get this data into Mapbox, we want to upload the data as a Tileset and use the data within a Style as feature layers.
I learned the hard way that there is a good way to do this, and a bad way to do this. The simple way is to export each of the 4 bands as a GeoJSON file, upload it to Mapbox, and add it as a layer. This is a mistake. Mapbox has a limit of 15 data “Sources” per Style, so saving each layer as a separate GeoJSON file and uploading them separately quickly caps out how many layers we can have per Style.
Luckily, Mapbox has released a nice tool called tippecanoe which lets us combine GeoJSON files into a single mbtiles file (it can do a ton of other things too; this is just what I’ve used it for). An mbtiles file can have as many layers as we want, as long as it is under 25 GB.
First we want to extract each layer as a GeoJSON file; right click the layer → Export → Save Features As.
Choose GeoJSON and repeat for each layer. This gives us four geojson files:
$ ls -lh *.geojson
-rw-r--r-- 1 bpodgursky 640K Aug 1 22:46 tornado10.geojson
-rw-r--r-- 1 bpodgursky 590K Aug 1 22:45 tornado25.geojson
-rw-r--r-- 1 bpodgursky 579K Aug 1 22:45 tornado40.geojson
-rw-r--r-- 1 bpodgursky 367K Aug 1 22:44 tornado65.geojson
We can use tippecanoe to combine these into a single, small, mbtiles file:
$ tippecanoe -zg -o tornado.mbtiles — extend-zooms-if-still-dropping *.geojson
$ ls -lh tornado2.mbtiles
-rw-r--r-- 1 bpodgursky 128K Aug 1 22:54 tornado.mbtiles
This gives us a single tornado.mbtiles file.
In practice I added these layers to an existing map for bunker.land; for simplicity, here I’m going to set up a new empty Style. After setting up a Mapbox account, navigate to Studio → Styles → New Style. I use a blank background, but you can also choose an OpenStreetMap background.
We can add these layers directly to the Style. Navigate through Add layer → Select data → Upload to upload the mbtiles file we just generated. These features are small and should upload pretty quickly. Once that’s available (you may need to refresh), we see that there are four layers in the new source:
We’ll create four new layers from this source. We’ll just use the Mapbox studio to recreate the styling we want, and set the opacity so the overlay is visible but doesn’t obscure anything:
All I needed to do now was get this into a website.
Embedding on bunker.land
Mapbox GL JS has great examples about how to get a Style in a map, so I won’t dig into the code too much; the important part is just loading a map from this style:
mapboxgl.accessToken = YOUR_TOKEN;
var map = new mapboxgl.Map({
container: 'map', // the div we want to attach the map to
style: 'mapbox://styles/bpodgursky/cjxw0v4fr7hd81cp6s0230lcw', // the ID of our style
center: [-98, 40], // starting position [lng, lat] -- this is about the middle of the US
zoom: 4 // starting zoom level
});
We can see the final result here, overlaid against OpenMapTiles on bunker.land:
Since our layer is just a simple vector tile layer, it’s easy to detect these features on-click for a particular point, along with any other enabled layers:
Wrapping up
It’s now pretty clear why I missed all the tornadoes as a kid — Tornado Alley (kind of) skips right over central Missouri, where I grew up! My only explanation for this is, “weather is complicated”.
On the technical side, I was surprised how easy it was to generate a decent-looking map; Mapbox and QGIS made it stupidly easy to turn raw data into a clean visualization (and I’ve only been using QGIS for a couple weeks, so I’m sure I missed a few nice shortcuts.)
Now that I know how to turn ugly data into nice heatmaps or gradient data, I’ll probably work on adding hurricanes and flooding over the next couple weeks. Stay tuned.
jbool_expressions is a small OSS library I maintain. To make it easy to use, artifacts are published to Maven Central. I have never been happy with my process for releasing to Maven Central; the releases were done manually (no CI) on my laptop and felt fragile.
I wanted to streamline this process to meet a few requirements:
All deployments should happen from a CI system; nothing depends on laptop state (I don’t want to lose my encryption key when I get a new laptop)
Every commit to master should automatically publish a SNAPSHOT artifact to Sonatype (no manual snapshot release process)
Cutting a proper release to Maven Central, when needed, should be straightforward and hard to mess up
Performing releases should not generate commit clutter. Namely, no more of this:
Luckily for me, we recently set up a very similar process for our OSS projects at LiveRamp. I don’t want to claim I figured this all out myself — others at LiveRamp (namely, Josh Kwan) were heavily involved in setting up the encryption parts for the LiveRamp OSS projects which I used as a model.
There’s a lot of information out there about Maven deploys, but I had trouble finding a simple guide which ties it all together in a painless way, so I decided to write it up here.
tl,dr: through some TravisCI and Maven magic, jbool_expressions now publishes SNAPSHOT artifacts to Sonatype on each master commit, and I can now deploy a release to Maven Central with these commands:
$ git tag 1.23
$ git push origin 1.23
To update and publish the next SNAPSHOT version, I can just change and push the version:
$ mvn versions:set -DnewVersion=1.24-SNAPSHOT
$ git commit -am "Update to version 1.24-SNAPSHOT"
$ git push origin master
At no point is anything auto-committed by Maven; the only commits in the Git history are ones I did manually. Obviously I could script these last few steps, but I like that these are all primitive commands, with no magic scripts which could go stale or break halfway through.
The thousand-foot view of the CI build I set up for jbool_expressions looks like this:
jbool_expressions uses TravisCI to run tests and deploys on every commit to master
Snapshots deploy to Sonatype; releases deploy to Maven Central (via a Sonatype staging repository)
Tagged commits publish with a version corresponding to the git tag, by using the versions-maven-plugin mid-build.
The rest of this post walks through the setup necessary to get this all working, and points out the important files (if you’d rather just look around, you can just check out the repository itself)
Set up a Sonatype account
Sonatype generously provides OSS projects free artifact hosting and mirroring to Maven Central. To set up an account with Sonatype OSS hosting, follow the guide here. After creating the JIRA account for issues.sonatype.org, hold onto the credentials — we’ll use to use those later to publish artifacts.
Creating a “New Project” ticket and getting it approved isn’t an instant process; the approval is manual, because Maven Central requires artifact coordinates to reflect actual domain control. Since I wanted to publish my artifacts under the com.bpodgursky coordinates, I needed to prove ownership of bpodgursky.com.
Once a project is approved, we have permission to deploy artifacts two important places:
Most of the interesting publishing configuration happens in the “publish” profile here. The three maven plugins — maven-javadoc-plugin, maven-source-plugin, and maven-gpg-plugin — are all standard and generate artifacts necessary for a central deploy (the gpg plugin requires some configuration we’ll do later). The last one — nexus-staging-maven-plugin — is a replacement for the maven-deploy-plugin, and tells Maven to deploy artifacts through Sonatype.
Fairly straightforward — we want to publish release artifacts to Maven central, but SNAPSHOT artifacts to Sonatype (Maven central doesn’t accept SNAPSHOTs)
The Maven server configurations let us tell Maven how to log into Sonatype so we can deploy artifacts. Later I’ll explain how we get these variables into the build.
.travis.yml completely defines how and when TravisCI builds a project. I’ll walk through what we do in this one.
language: java
jdk:
- openjdk10
The header of .travis.yml configures a straightforward Java 10 build. Note, we can (and do) still build at a Java 8 language level, we just don’t want to use a deprecated JDK.
install: "/bin/true"
script:
- "./test"
Maven installs the dependencies it needs during building, so we can just disable the “install” phase entirely. The test script can be inlined if you prefer; it runs a very simple suite:
mvn clean install -q -B
(by running through the “install” phase instead of just “test”, we also catch the “integration-test” and “verify”Maven phases, which are nice things to run in a PR, if they exist).
The next four encrypted secrets were all added via travis. For more details on how TravisCI handles encrypted secrets, see this article. Here, these hold four variables we’ll use in the deploy script:
The first two variables are the Sonatype credentials we created earlier; these are used to authenticate to Sonatype to publish snapshots and release artifacts to central. The last two are for the GPG key we’ll be using to sign the artifacts we publish to Maven central. Setting up GPG keys and using them to sign artifacts is outside the scope of this post; Sonatype has documented how to set up your GPG key here, and how to use it to sign your Maven artifacts here.
Next we need to set up our GPG key. To sign our artifacts in a Travis build, we need the GPG key available. Again, set this up by having Travis encrypt the entire file:
travis encrypt-file .travis/gpg.asc --add
In this case, gpg.asc is the gpg key you want to use to sign artifacts. This will create .travis/gpg.asc.enc — commit this file, but do not commit gpg.asc.
Travis will have added a block to .travis.yml that looks something like this:
Here we actually set up the artifact to deploy (the whole point of this exercise). We tell Travis to deploy the artifact under two circumstances: first, for any commit to master; second, if there were tags pushed. We’ll use the distinction between the two later.
The deploy script handles the actual deployment. After a bit of input validation, we get to the important parts:
gpg --fast-import .travis/gpg.asc
This imports the gpg key we decrypted earlier — we need to use this to sign artifacts.
if [ ! -z "$TRAVIS_TAG" ]
then
echo "on a tag -> set pom.xml <version> to $TRAVIS_TAG"
mvn --settings "${TRAVIS_BUILD_DIR}/.travis/mvn-settings.xml" org.codehaus.mojo:versions-maven-plugin:2.1:set -DnewVersion=$TRAVIS_TAG 1>/dev/null 2>/dev/null
else
echo "not on a tag -> keep snapshot version in pom.xml"
fi
This is the important part for eliminating commit clutter. Whenever a tag is pushed — aka, whenever $TRAVIS_TAG exists — we use the versions-maven-plugin to temporarily set the project’s version to that tag. Specifically,
$ git tag 1.23
$ git push origin 1.23
The committed artifact version in pom.xml doesn’t change. It doesn’t matter what the version is in pom.xml in master — we want to publish this version as 1.23.
Last but not least, the actual deploy. Since we configured our distributionManagement section above with different snapshot and release repositories, we don’t need to think about the version anymore — if it’s still SNAPSHOT (like in the pom), it goes to Sonatype; if we pushed a release tag, it’s headed for central.
That’s it!
Before this setup, I was never really happy with my process for cutting a release and getting artifacts into Maven Central — the auto-generated git commits cluttered the history and it was too easy for a release to fail halfway. With this process, it’s almost impossible for me to mess up a release.
Hopefully this writeup helps a few people skip the trial-and-error part of getting OSS Java artifacts released. Let me know if I missed anything, or there’s a way to make this even simpler.
The news is quite clear: tensions with China are high, Russia is flaunting hypersonic missiles, and even newcomers Iran and North Korea will likely have sophisticated ICBM capabilities within a couple years. While the general sentiment has been “yeah, nuclear war would definitely suck”, there’s been very limited conversation about how a nuclear war would actually play out, and what it would mean for the average American.
One artifact of the Cold War I find fascinating are the nuclear target maps which identified the likely first and second-strike targets in a nuclear war. For those who felt the risk of a nuclear confrontation was high, these maps helped inform better and worse places to live.
Unfortunately, I’ve never seen a good resource that exposed this data using modern mapping tools. I’ve wanted an opportunity to learn about GIS and front-end mapping libraries, so I decided I to build a similar map using modern browser-based map libraries.
I’ll likely follow up with a post about what this involved technically, but tl,dr it involved:
(light) research on which areas of the US are potential high-priority targets
(light) research on the impact radius of a nuclear bomb (primarily via NUKEMAP)
Finding public-domain maps of US infrastructure by type; these were pretty easy to grab from data.gov and the DOT
Calculating the blast radii around potential targets (simple buffers produced with QGIS)
Loading all these layers into Mapbox and exposing them on a simple site via Mapbox GL JS
You can see what I put together at bunker.land, a very simple attempt at mapping out what places in the US would and would not be great places to live during a nuclear exchange.
Although most of the work here went into modeling nuclear targets, there were a few other un/natural disasters I thought would be interesting overlays:
Earthquake risk
Sea level rise (from global warming)
Normal disclaimer: I am not an expert on much of anything, and especially not on nuclear war. The maps here should be taken exactly for what they are — aggregated publicly available datasets with minimal filtering or analysis. Feedback is welcome from actual experts.
Nuclear War
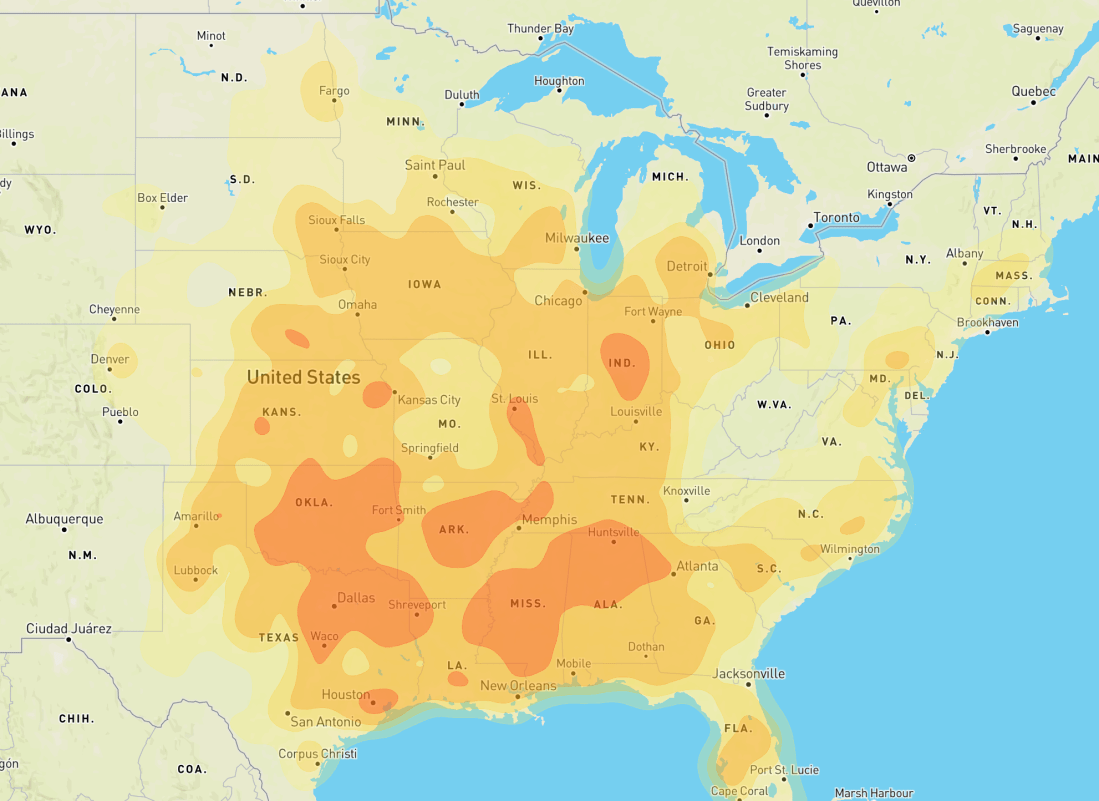
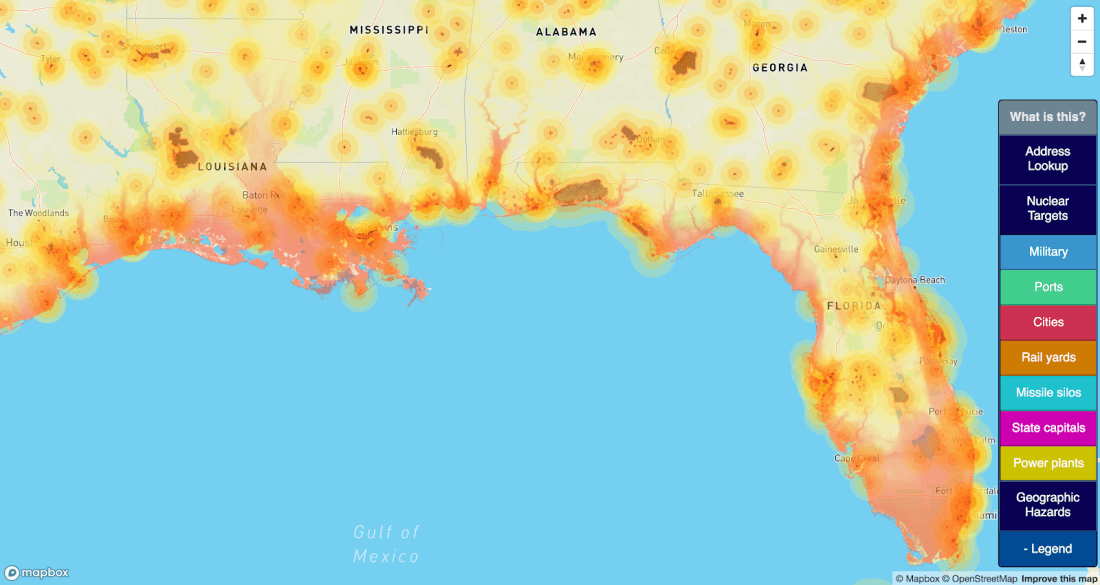
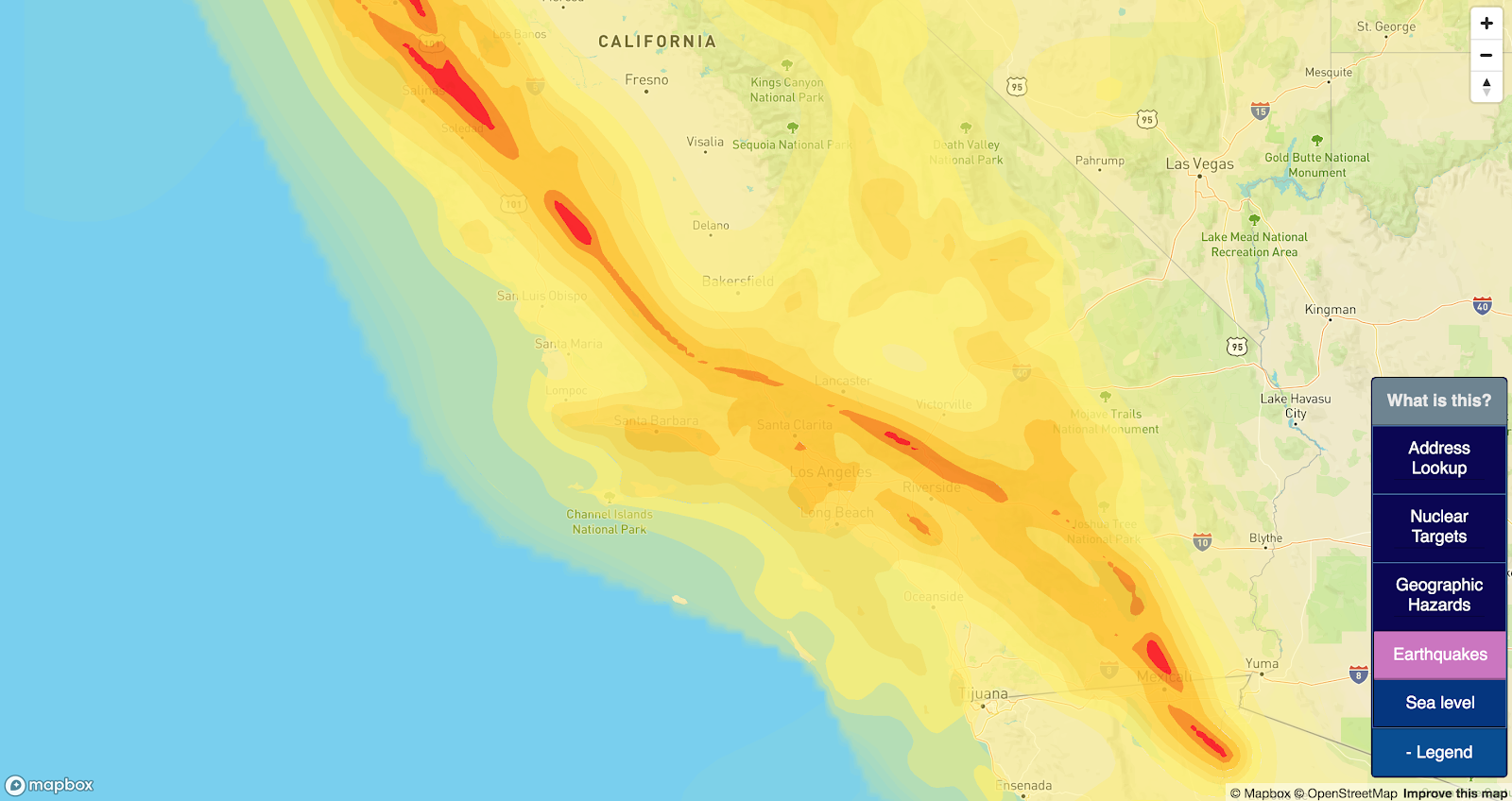
Obviously nuclear war is always bad news, but even in a major war, not everyone is going to be instantly vaporized. There are especially terrible places to live during a nuclear war — namely, next to any important targets. These maps try to identify for any location in the US whether there are any potential nearby bomb targets in a nuclear strike scenario, and the potential damage range from those strikes:
This map plots potential nuclear targets, sourced from public datasets. Right now I include:
Military bases
Ports
Major cities
Rail yards
ICBM missile silos
State capitals
Power plants
This post explains the data sources and filtering farther down.
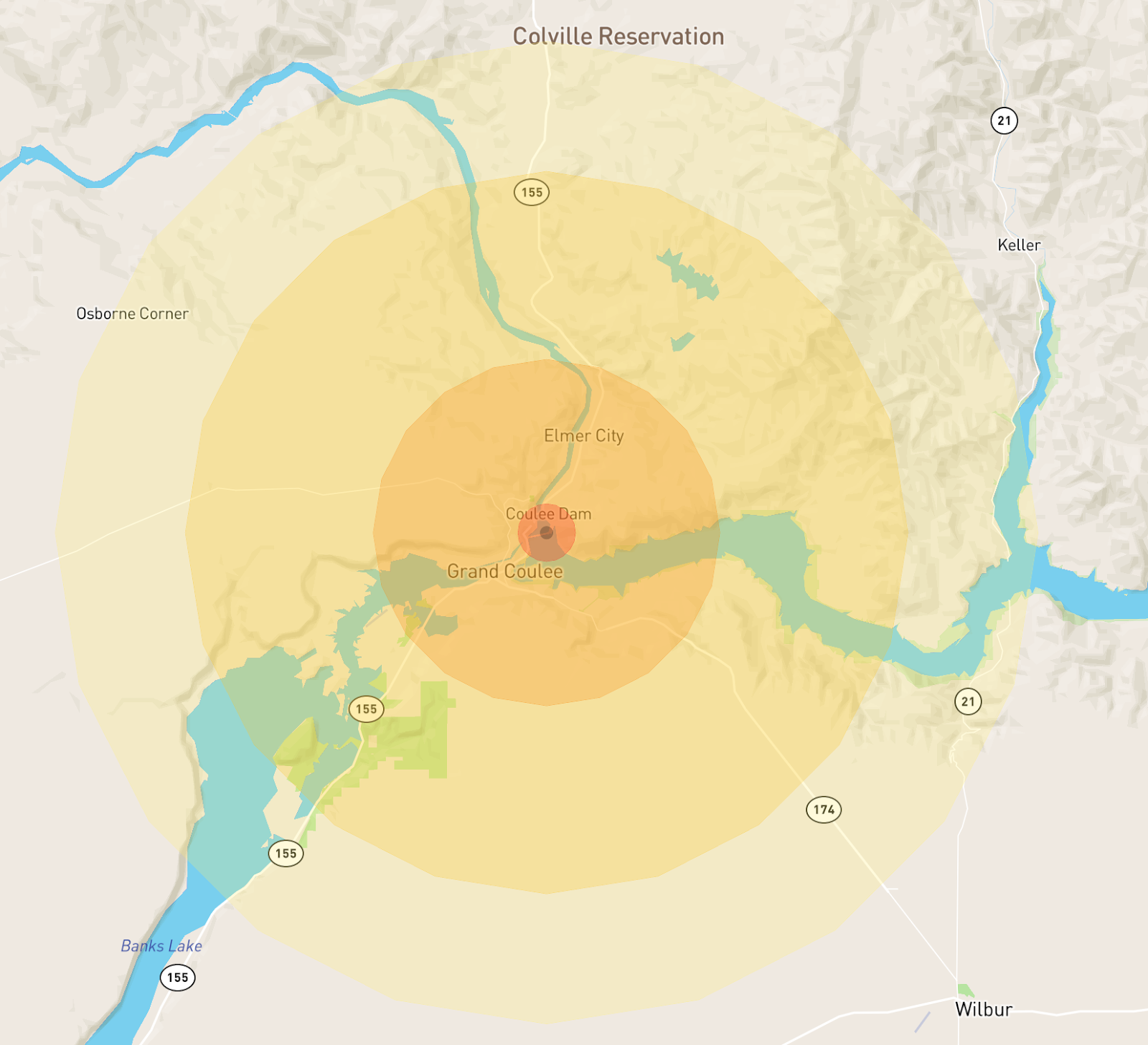
All nuclear blast radii on this map are modeled on a 5 Mt nuclear airburst (a standard Chinese warhead). Damage radii use estimates from Alex Wellerstein’s NUKEMAP; for more info, check out his site. This site renders nuclear blast impacts at 4 levels:
2km: Fireball radius
12km: Air blast radius (5 psi)
25km: Thermal radiation radius
34km: Air blast radius (1 psi)
On the map, the zones look something like this:
Modeling nuclear fallout accurately is a lot harder, and I have not attempted it at all. The fallout zones depend on airburst height and wind conditions, which are both dynamic and complex.
Targets
This a quick description of each of the target layers available on bunker.land. Since I don’t know what I’m doing, unless the selection criteria were very obvious, I erred on the side of presenting raw, un-filtered data. So, many minor military bases, railyards etc are included even if they have no real significance.
Likewise, several categories of likely targets are not included yet, including but not limited to airports, refineries, shipyards, factories, and communication facilities.
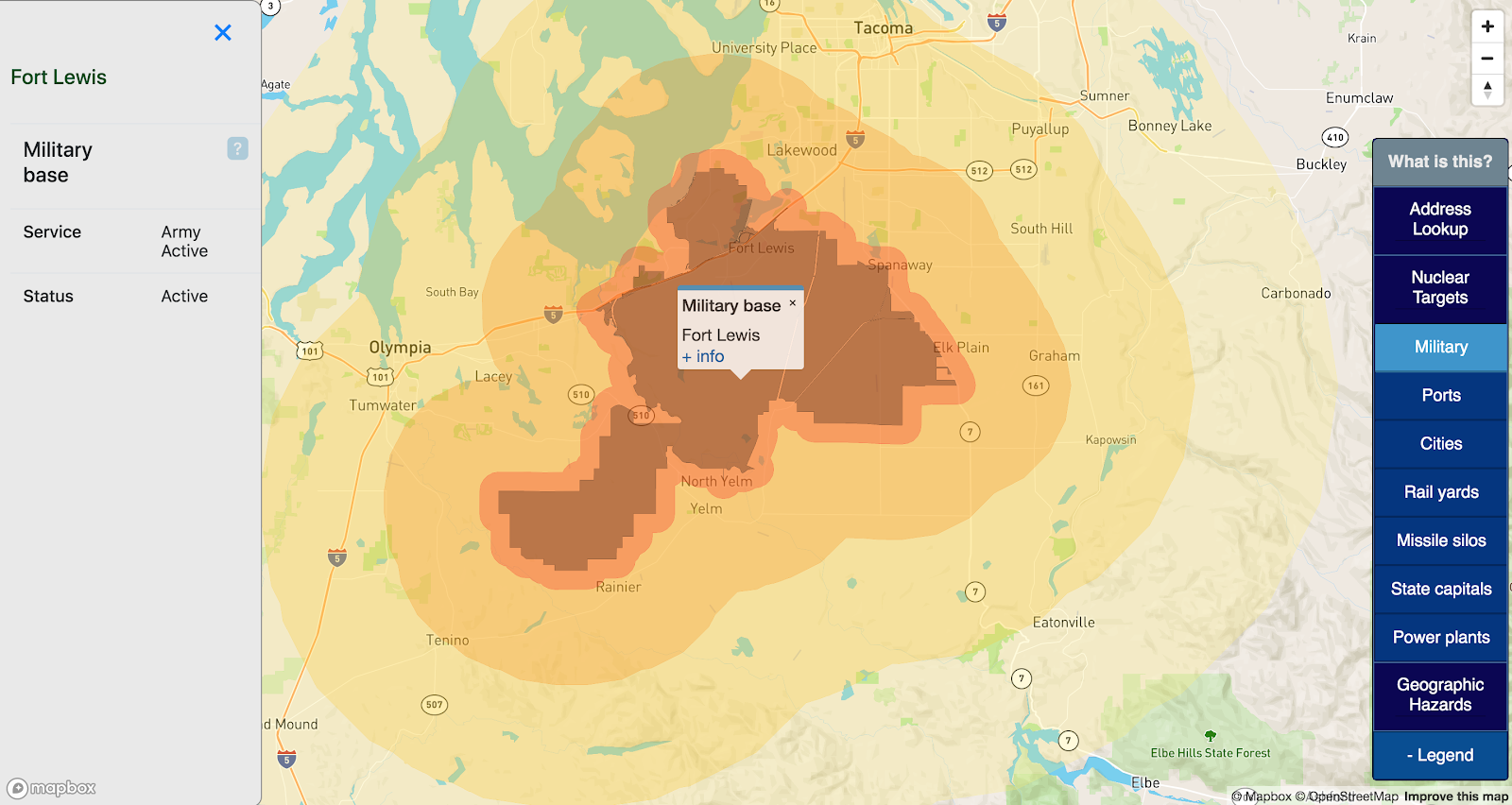
Military bases
Strategic military bases are obvious targets in a nuclear war. This map displays all US military installations on US soil, with data sourced from the Department of Transportation.
This map makes no effort to distinguish between major and minor strategic targets; all installations are rendered as potential targets.
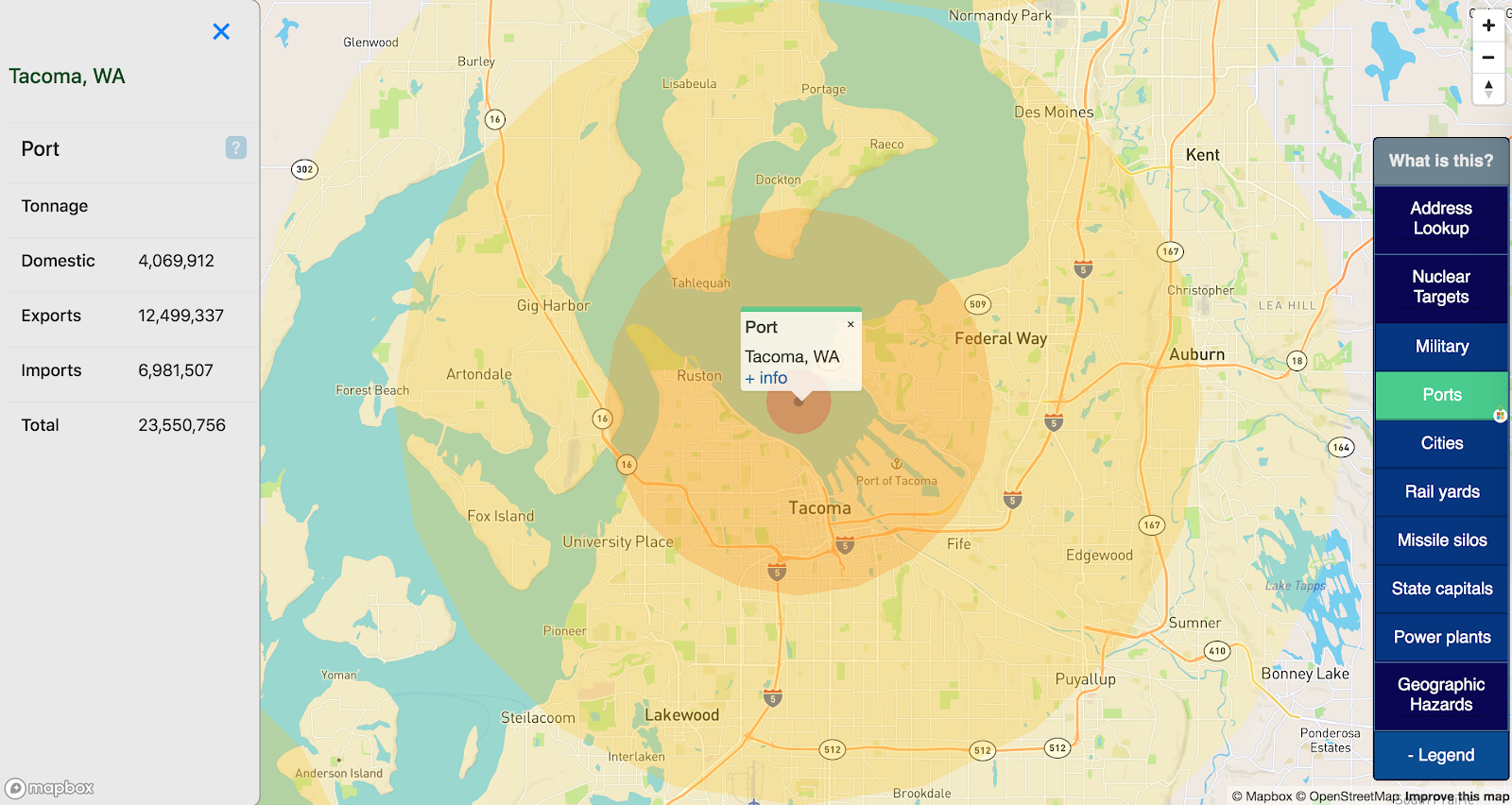
Ports
Major US ports are often cited as potential targets in either terrorist attacks or nuclear war, due to their important economic roles and proximity to economic centers.
This map sources a Department of Transportation list of major US ports. No effort was made to filter ports by importance or risk; all ports in this dataset are rendered as potential targets.
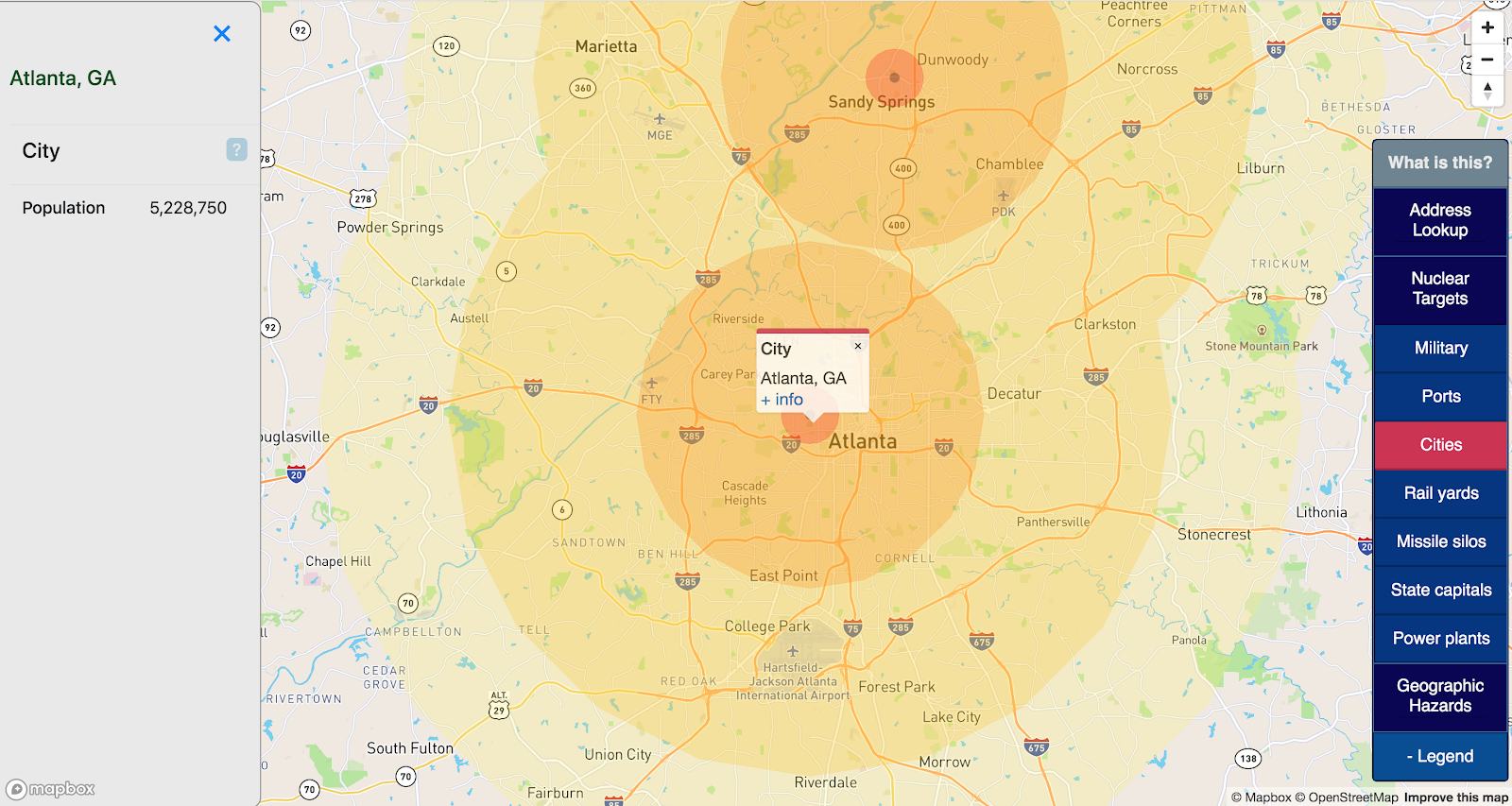
Major cities
Even in a major nuclear war, most cities are not valuable targets; only cities with important military targets or infrastructure are likely to be targeted.
This map displays all cities with a population over 100,000 (sourced here) only as a proxy for infrastructure that other layers do not capture.
No effort is made to filter cities by risk or strategic importance.
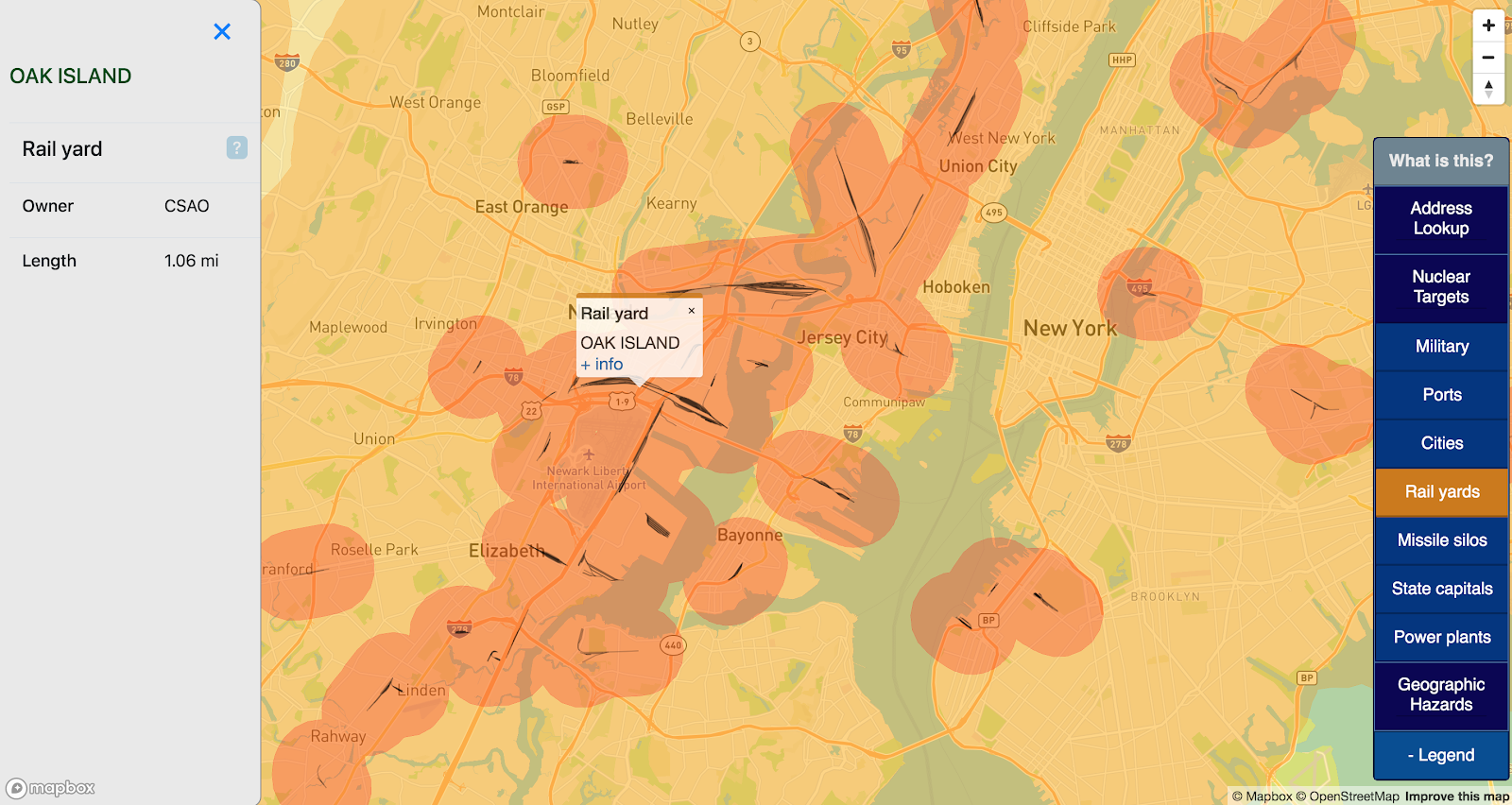
Rail yards
Cold War nuclear targets frequently include transportation hubs such as railyards. This map includes all US rail yards, as sourced from data.gov.
This is a very inclusive map, and most of these rail yards have little to no strategic value. Without a better metric for inclusion though, all US railyards are modeled as potential targets.
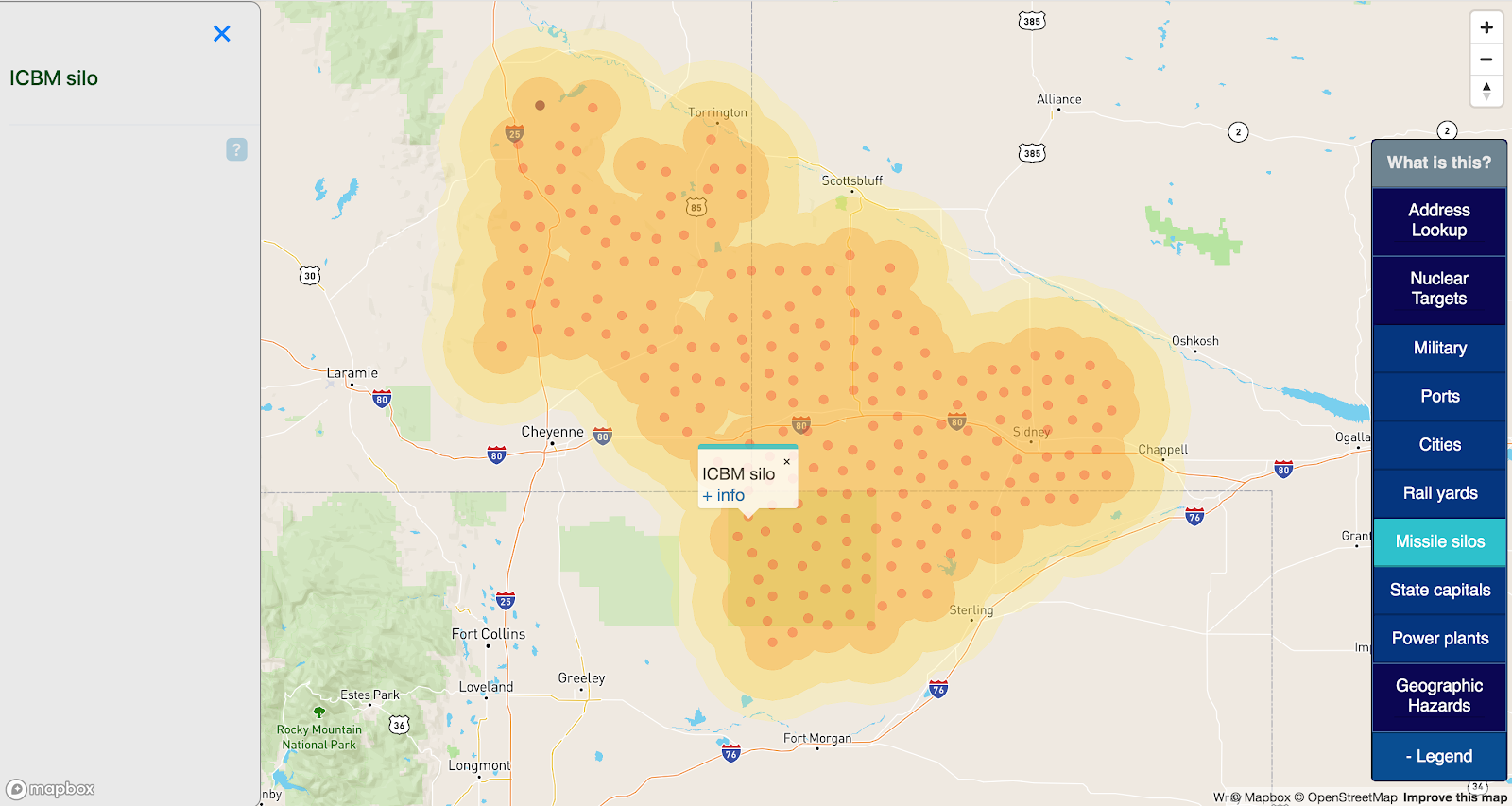
ICBM missile silos
The first priority in a nuclear war is eliminating the enemy’s ability to respond with nuclear weapons. Ground-based nuclear missile silos are very high-value targets.
The United States maintains a ground-based ICBM force of threemissile wings spread across Montana, North Dakota, Wyoming, Nebraska, and Colorado.
These silo locations have been sourced from Wikipedia, and no other effort was made to verify operational status.
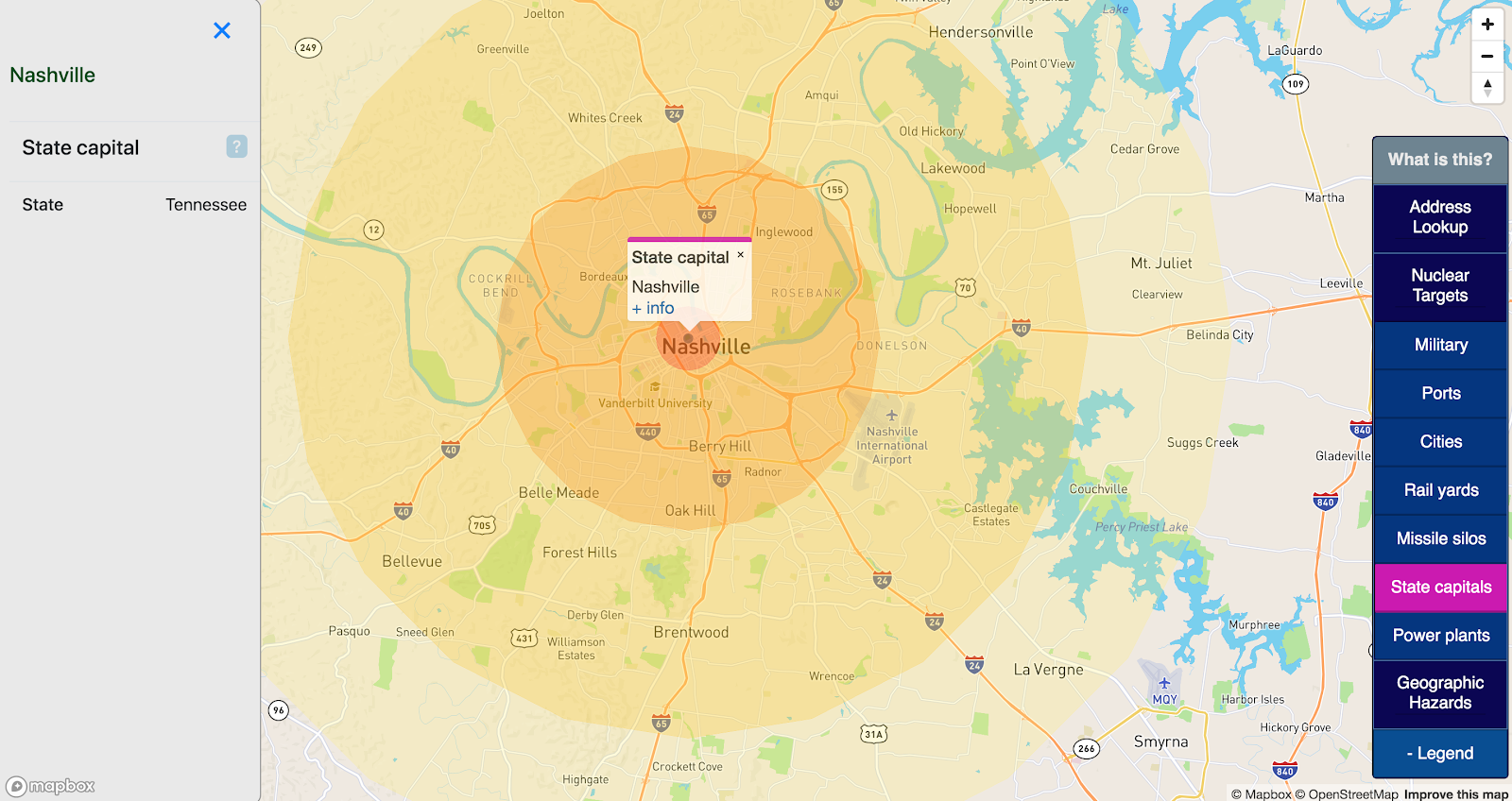
State capitals
It is generally agreed that US state capitals will be considered high-value targets in a full nuclear war. This map includes all 50 US state capitals as targets.
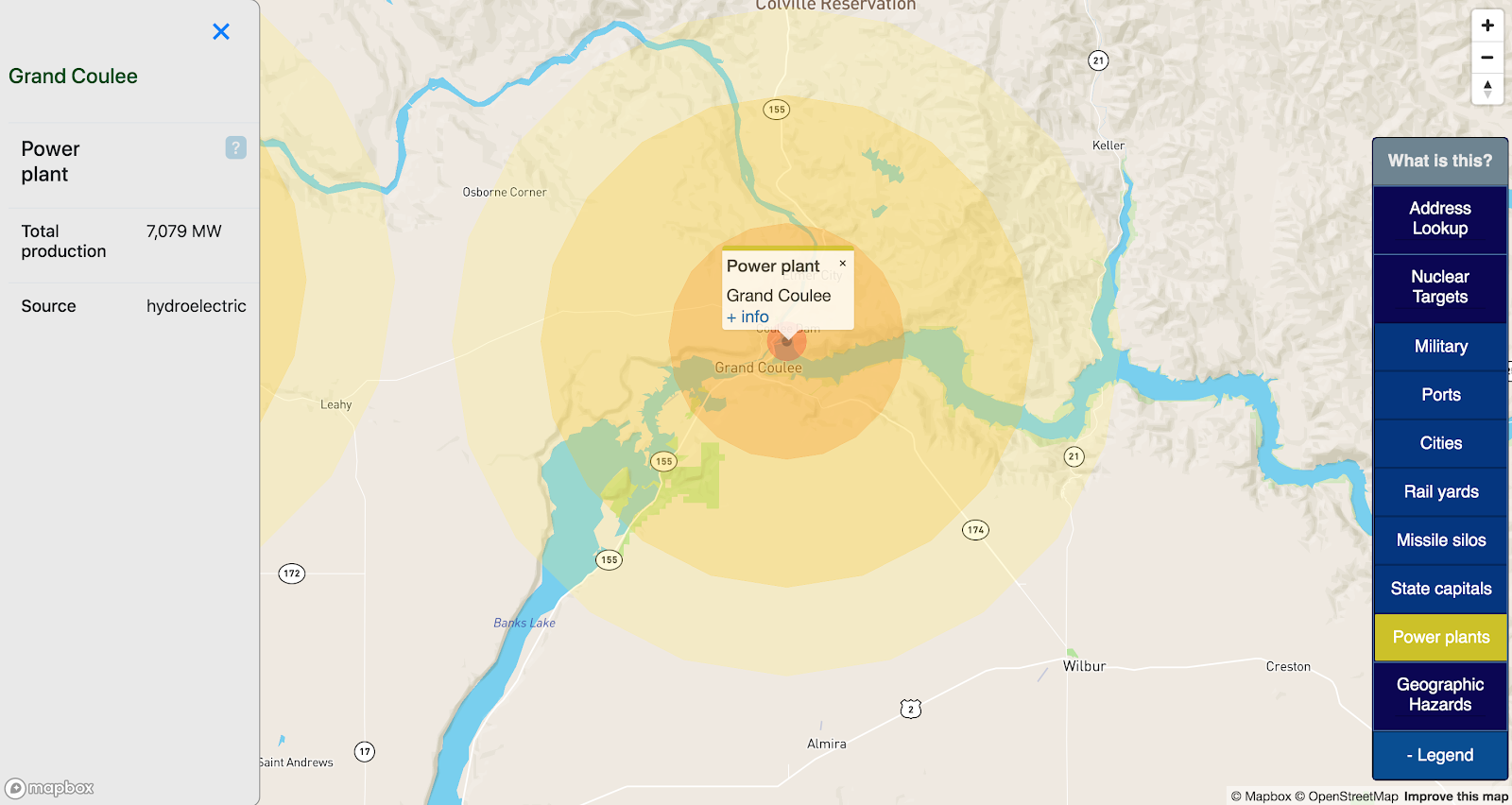
Power plants
In a nuclear war, power production facilities will be targeted for their military and industrial value. This map pulls from Energy Information Administration datasets all facilities with over 1 GW of capacity, across all production types (coal, hydroelectric, nuclear, etc).
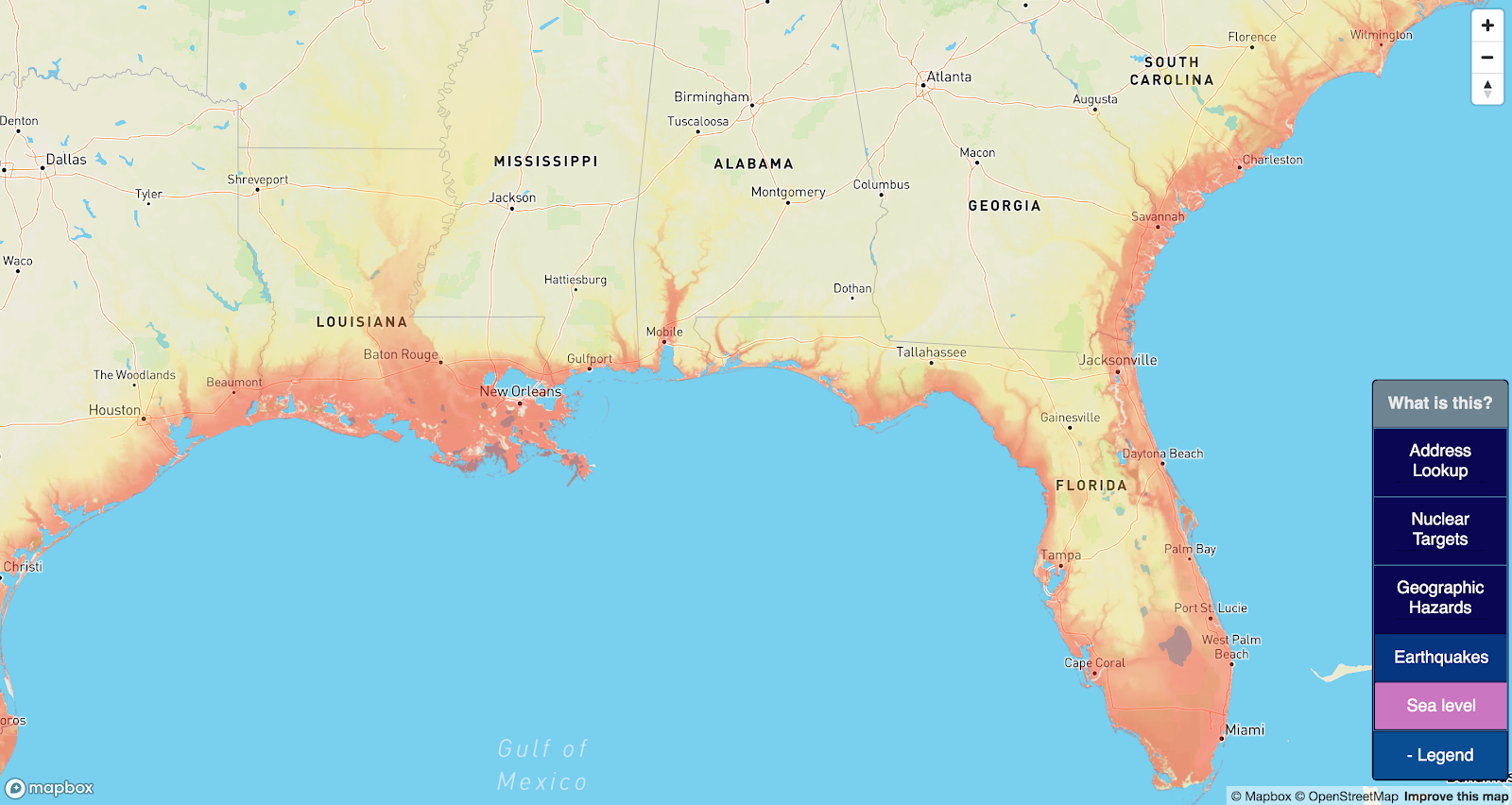
Uncontrolled Sea Level Rise
Unlike nuclear war, sea level rise won’t sneak up and vaporize you while you sleep. But it will make a house a really poor investment .
Most realistic global warming worst-case scenarios model a 5-10 foot sea level rise by 2100, which is, to be clear, Very Bad News, but is unlikely to sink you unless you live in the everglades. This map goes further and asks “How far from the ocean would you want to be if all the ice melted — around 220 feet of it.
Elevation data was sourced here, at 100m resolution.
There are a lot of ways global warming could make a place uninhabitable — for example, making it really hot. But this map currently only captures raw sea level rise.
Earthquakes
Earthquakes are usually bad news. Earthquake prediction is challenging, but it’s generally understood which areas of the country are most prone to earthquakes. This map attempts to display areas with especially high earthquake risks.
Earthquake risks are pulled from the 2014 USGS seismic-hazard maps found here. ‘Intensity’ represents the peak horizontal acceleration with 10% probability of exceedance in 50 years, measured as a percentage of gravity.
Only areas with over 10% g are rendered on location markers. 10% was only chosen because it is a round number.
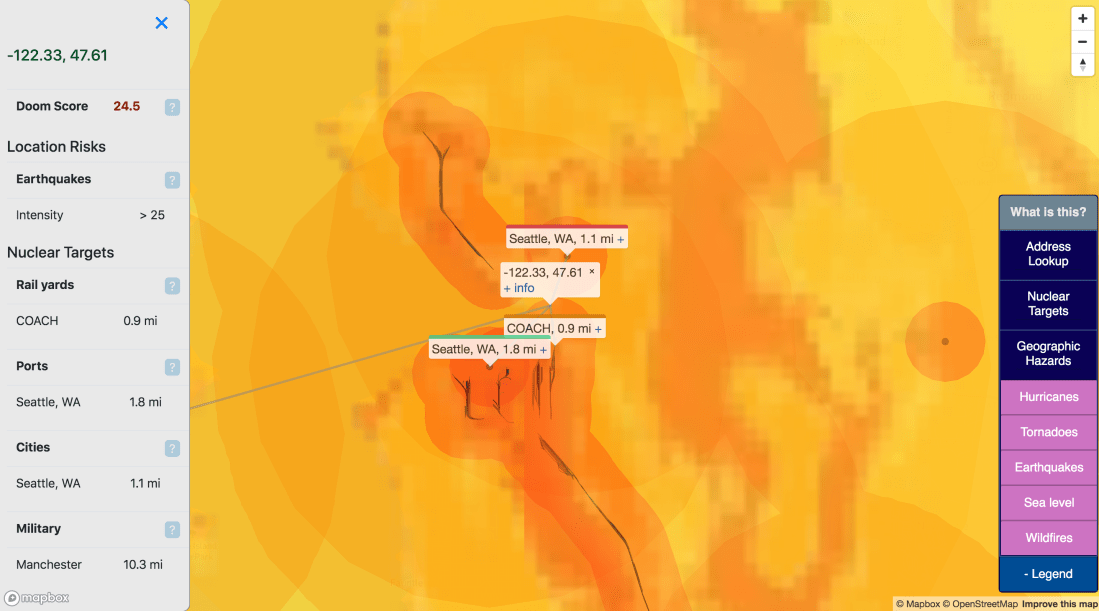
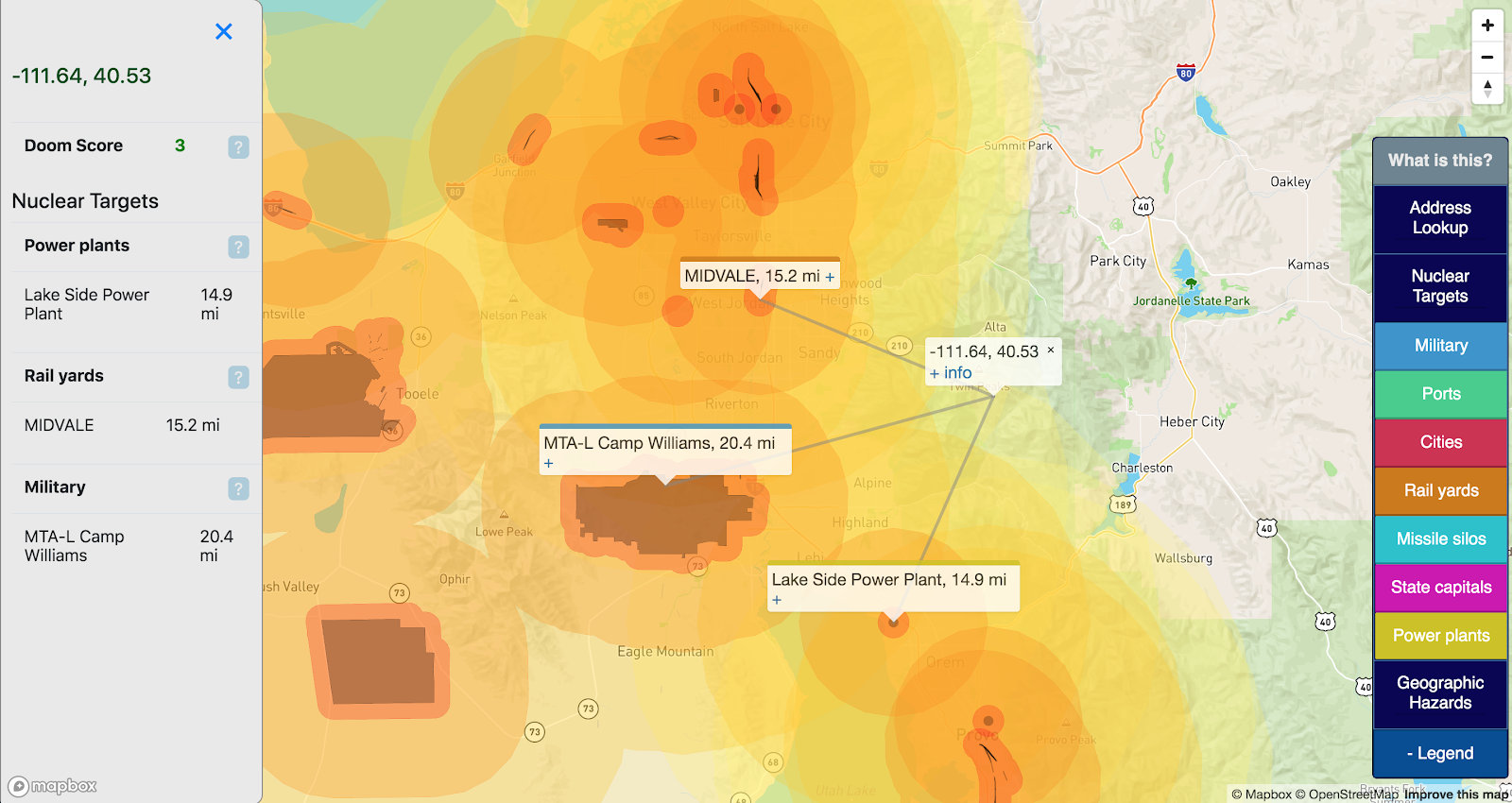
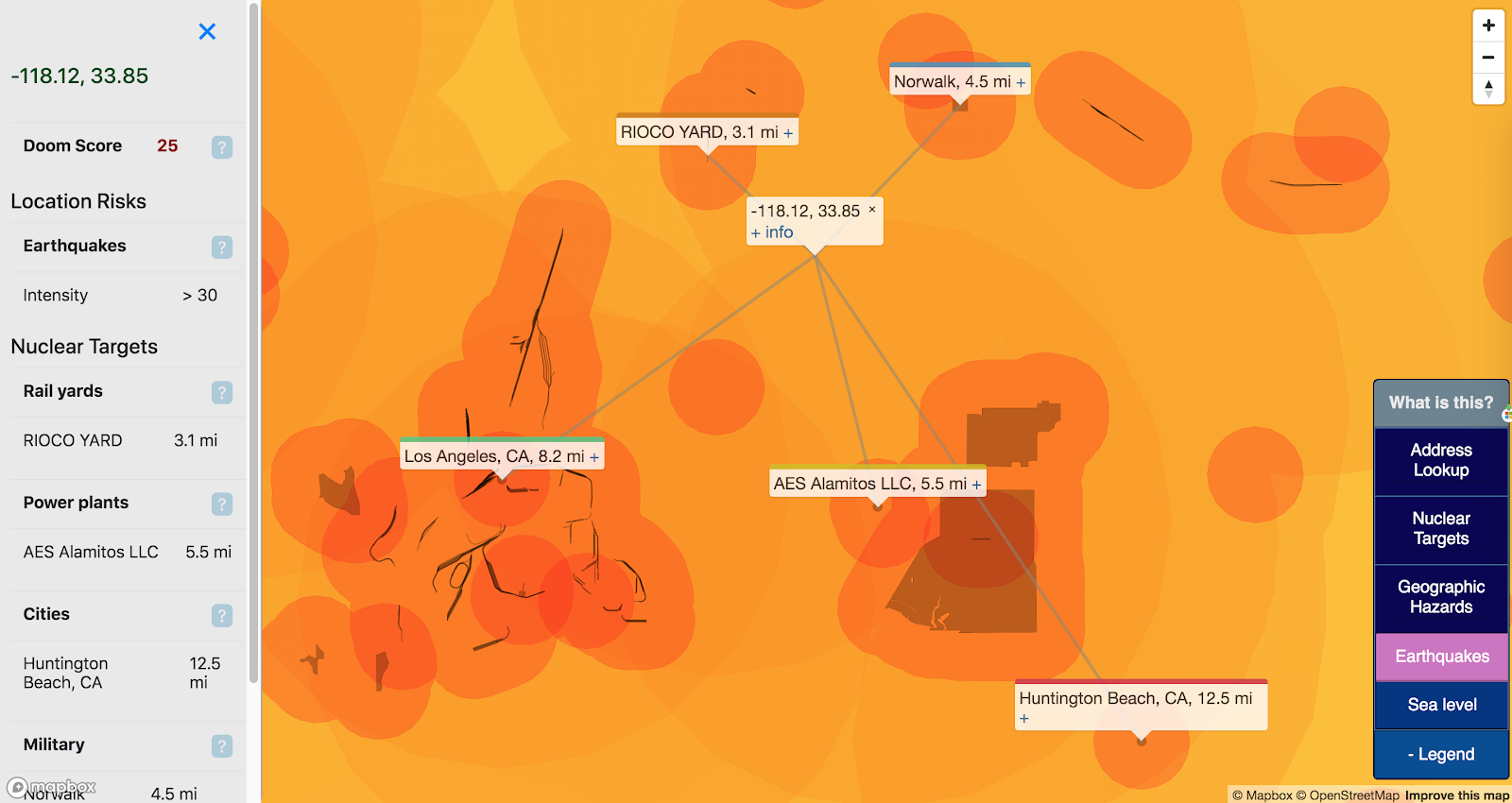
Doom Score
I found that the buffers presented on the map were cool but made it challenging to make a head-to-head numeric comparison between locations. To make this more straightforward, I added a “Doom Score” which aggregates the enabled hazards for a given point:
It’s not a sophisticated score: for each enabled target layer, points are assigned by distance:
0-2km: 10
2-12km: 5
12-25km: 2
25-34km: 1
Earthquake risk is assigned as the %g exceedance as measured above by 10. Eg, 20% chance of exceedance = 2 points. Summed together, these numbers may not represent a ton, but they are fun to compare.
So while Zillow (and similar services) provide useful info about neighborhoods like “Walk Score” and “Transit Score”, bunker.land is the only place you can get a Doom Score.
Follow-ups / Help
I’m not an expert in anything presented on this map. There’s certainly a lot that could be improved:
This is by no means an exhaustive list of the things that can kill you. More hazards will (probably) be added to this map over time. Reach out if you have any specific interests (hurricanes, etc).
Expanded target lists from reliable data-sets (airports, etc)
Contributions appreciated from actual experts about ways to judge which targets are actually important.
I’ll update as I add content to this site (which may or may not happen frequently). Feature requests and bug reports welcome. Best way to leave feedback is to email me directly at bpodgursky@gmail.com.
At Google Next 2019, co-workers Sasha Kipervarg, Patrick Raymond and I presented about how we migrated our company’s on-premise big-data Hadoop environment to GCP, from both a technical and cultural perspective. You can view the presentation and slides on YouTube:
Our Google Next presentation did not give us enough time to go into deep technical details; to give a more in-depth technical view of our migration, I’ve put together a series of blog posts on the LiveRamp engineering blog, with an emphasis on how we migrated our Hadoop environment, the infrastructure my team is responsible for maintaining:
Part 1 where I discuss our Hadoop environment, why we decided to migrate LiveRamp to the cloud, and how we chose GCP.
Part 2 where I discuss the design we chose for our Hadoop environment on GCP.
Part 3 where I discuss the migration process and system architecture which let teams incrementally migrate applications to the cloud.
Part 4 written by coworker Porter Westling, where he discusses how we worked around our data center egress bandwidth restrictions.
Part 5 where I discuss LiveRamp’s use of the cloud going forward, and the cultural changes enabled by migrating to the cloud from an on-premise environment.
LiveRamp’s migration into GCP has been my (and my team’s) primary objective for over a year, and we’ve learned (sometimes painfully) a ton on the way. Hopefully these articles help others who are planning big-data cloud migrations skip a few painful lessons.
Yesterday was Earth Day, so Facebook was naturally full of people bragging about how they walked to the store instead of driving, in order to save the Earth. I feel obligated to point out that this very plausibly isn’t true. I’m not the first person to run these numbers, but I was curious and wanted to investigate for myself. My (rather rough) calculations are all here.
As a baseline, we want to calculate the kWh cost of driving a car 1 mile. I’m using a baseline of 33.41 kWh / gallon of gasoline:
Car
MPG
kWh/ 1 mile
Prius
58
.58
F-150
19
1.76
If you’re bragging on Facebook about your environmental impact, you’re probably driving a Prius, so we’ll roll with that. Feel free to substitute your own car.
To get the calories burned per mile walking, I used numbers I found here. The numbers here vary pretty widely with body weight and walking speed, but I’ll use 180 pounds at 3.0 mph for 95 calories per hour.
To get the energy costs per pound of food produced, I used the numbers I found here. Click through for their sources. kWh / 1 mile is calculated as
kWh/1 mile = 180/(calories/lb) * ( kWh/lb)
Just to be clear: this isn’t the calories in food. This is the energy usage required to produce and transport the food to your mouth, which is essentially all fossil fuels. Numbers vary widely per food source, as expected.
Food
Calories / Lb
kWh / Lb
kWh / 1 mile
Corn
390
0.43
0.10
Milk
291
0.75
0.24
Apples
216
1.67
0.73
Eggs
650
4
0.58
Chicken
573
4.4
0.73
Cheese
1824
6.75
0.35
Pork
480
12.6
2.49
Beef
1176
31.5
2.54
So what’s the conclusion? It’s mixed.
If you drive a Prius, you’re OK walking, as long as you replace the burned calories with Doritos (cheese + corn) and (corn syrup’d) Coca-Cola
If you drive a Prius, and you replace the burned calories with a chicken and apple salad (I couldn’t find numbers for lettuce, but they are undoubtedly even worse), you are destroying the planet
If you drive an F-150, you’re probably going to replace your burned calories with a steak, so you’re actually saving the environment by driving.
These numbers are of course rough, and do not include:
The energy cost of producing a car. This becomes very complicated very quickly, becaus you likely would have done less damage by just buying a used car instead of a new Prius
This assumes you actually eat all the food you ordered, and didn’t leave carrots rotting in the back of your fridge (your fridge, by the way, uses energy). Americans are notoriously terrible at doing this.
This calculates only energy usage — it does not attempt to quantify the environmental impact of turning Brazilian rainforests into organic Kale farms, to grow your fourth-meal salad.
This assumes a single rider per car-mile. If you are carpooling on your drive to KFC, you can cut all the car energy usage numbers by half (or more, for families)
Anyway, I’m sure there are many other reasons these numbers are rough, I just wanted to point out that the conventional wisdom is pretty awful on environmental topics.
Over the past few months I’ve been working on a WebGL visualization of earth’s solar neighborhood — that is, a 3D map of all stars within 75 light years of Earth, rendering stars and (exo)planets as accurately as possible. In the process I’ve had to learn a lot about WebGL (specifically three.js, the WebGL library I’ve used). This post goes into more detail about how I ended up doing procedural star rendering using three.js.
The first iteration of this project rendered stars as large balls, with colors roughly mapped to star temperature. The balls did technically tell you where a star was, but it’s not a particularly compelling visual:
Pretty much any interesting WebGL or OpenGL animation uses vertex and fragment shaders to render complex details on surfaces. In some cases this just means mapping a fixed image onto a shape, but shaders can also be generated randomly, to represent flames, explosions, waves etc. three.js makes it easy to attach custom vertex and fragment shaders to your meshes, so I decided to take a shot at semi-realistic (or at least, cool-looking) star rendering with my own shaders.
Some googling brought me to a very helpful guide on the Seeds of Andromeda dev blog which outlined how to procedurally render stars using OpenGL. This post outlines how I translated a portion of this guide to three.js, along with a few tweaks.
The full code for the fragment and vertex shaders are on GitHub. I have images here, but the visuals are most interesting on the actual tool (http://uncharted.bpodgursky.com/) since they are larger and animated.
Usual disclaimer — I don’t know anything about astronomy, and I’m new to WebGL, so don’t assume that anything here is “correct” or implemented “cleanly”. Feedback and suggestions welcome.
My goal was to render something along the lines of this false-color image of the sun:
In the final shader I implemented:
the star’s temperature is mapped to an RGB color
noise functions try to emulate the real texture
a base noise function to generate granules
a targeted negative noise function to generate sunspots
a broader noise function to generate hotter areas
a separate corona is added to show the star at long distances
Temperature mapping The color of a star is determined by its temperature, following the black body radiation, color spectrum:
(sourced from wikipedia)
Since we want to render stars at the correct temperature, it makes sense to access this gradient in the shader where we are choosing colors for pixels. Unfortunately, WebGL limits the size of uniforms to a couple hundred on most hardware, making it tough to pack this data into the shader.
In theory WebGL implements vertex texture mapping, which would let the shader fetch the RGB coordinates from a loaded texture, but I wasn’t sure how to do this in WebGL. So instead I broke the black-body radiation color vector into a large, horrifying, stepwise function:
bool rbucket1 = i < 60.0; // 0, 255 in 60 bool rbucket2 = i >= 60.0 && i < 236.0; // 255,255
…
float r =
float(rbucket1) * (0.0 + i * 4.25) +
float(rbucket2) * (255.0) +
float(rbucket3) * (255.0 + (i - 236.0) * -2.442) +
float(rbucket4) * (128.0 + (i - 288.0) * -0.764) +
float(rbucket5) * (60.0 + (i - 377.0) * -0.4477)+
float(rbucket6) * 0.0;
Pretty disgusting. But it works! The full function is in the shader here
Plugging in the Sun’s temperature (5,778) gives us an exciting shade of off-white:
While beautiful, we can do better.
Base noise function (granules)
Going forward I diverge a bit from the SoA guide. While the SoA guide chooses a temperature and then varies the intensity of the texture based on a noise function, I instead fix high and low surface temperatures for the star, and use the noise function to vary between them. The high and low temperatures are passed into the shader as uniforms:
All the noise functions below shift the pixel temperature, which is then mapped to an RGB color.
Convection currents on the surface of the sun generate noisy “granules” of hotter and cooler areas. To represent these granules an available WebGL implementation of 3D simplex noise. The base noise for a pixel is just the simplex noise at the vertex coordinates, plus some magic numbers (simply tuned to whatever looked “realistic”):
The number of octaves in the simplex noise determines the “depth” of the noise, as zoom increases. The tradeoff of course is that each octave increases the work the GPU computes each frame, so more octaves == fewer frames per second. Here is the sun rendered at 2 octaves:
4 octaves (which I ended up using):
and 8 octaves (too intense to render real-time with acceptable performance):
Sunspots
Sunspots are areas on the surface of a star with a reduced surface temperature due to magnetic field flux. My implementation of sunspots is pretty simple; I take the same noise function we used for the granules, but with a decreased frequency, higher amplitude and initial offset. By only taking the positive values (the max function), the sunspots show up as discrete features rather than continuous noise. The final value (“ss”) is then subtracted from the initial noise.
float frequency = 0.04;
float t1 = snoise(vTexCoord3D * frequency)*2.7 - 1.9;
float ss = max(0.0, t1);
This adds only a single snoise call per pixel, and looks reasonably good:
Additional temperature variation
To add a bit more noise, the noise function is used one last time, this time to add temperature in broader areas, for a bit more noise:
float brightNoise= snoise(vTexCoord3D * .02)*1.4- .9;
float brightSpot = max(0.0, brightNoise);
float total = noiseBase - ss + brightSpot;
All together, this is what the final shader looks like:
Corona
Stars are very small, on a stellar scale. The main goal of this project is to be able to visually hop around the Earth’s solar neighborhood, so we need to be able to see stars at a long distance (like we can in real life).
The easiest solution is to just have a very large fixed sprite attached at the star’s location. This solution has some issues though:
being inside a large semi-opaque sprite (ex, when zoomed up towards a star) occludes vision of everything else
scaled sprites in Three.js do not play well with raycasting (the raycaster misses the sprite, making it impossible to select stars by mousing over them)
a fixed sprite will not vary its color by star temperature
I ended up implementing a shader which implemented a corona shader with
RGB color based on the star’s temperature (same implementation as above)
color near the focus trending towards pure white
size was proportional to camera distance (up to a max distance)
a bit of lens flare (this didn’t work very well)
Full code here. Lots of magic constants for aesthetics, like before.
Close to the target star, the corona is mostly occluded by the detail mesh:
At a distance the corona remains visible:
On a cooler (temperature) star:
The corona mesh serves two purposes
calculating intersections during raycasting (to enable targeting stars via mouseover and clicking)
star visibility
Using a custom shader to implement both of these use-cases let me cut the number of rendered three.js meshes in half; this is great, because rendering half as many objects means each frame renders twice as quickly.
Conclusions
This shader is a pretty good first step, but I’d like to make a few improvements and additions when I have a chance:
Solar flares (and other 3D surface activity)
More accurate sunspot rendering (the size and frequency aren’t based on any real science)
Fix coronas to more accurately represent a star’s real visual magnitude — the most obvious ones here are the largest ones, not necessarily the brightest ones
My goal is to follow up this post a couple others about parts of this project I think turned out well, starting with the orbit controls (the logic for panning the camera around a fixed point while orbiting).









































{kind=link}