Comparing our cycles: PGT-A, then Orchid PGT-WGS
A few months ago I looked back at the PGT-A my wife and I received for our first IVF cycle in 2019, and found that low-quality PGT-A results resulted in our clinic discarding possibly viable embryos — 2 embryos with chaotic results, and 1 extremely low-level mosaicism (here’s a “chaotic” example, you can read more here).

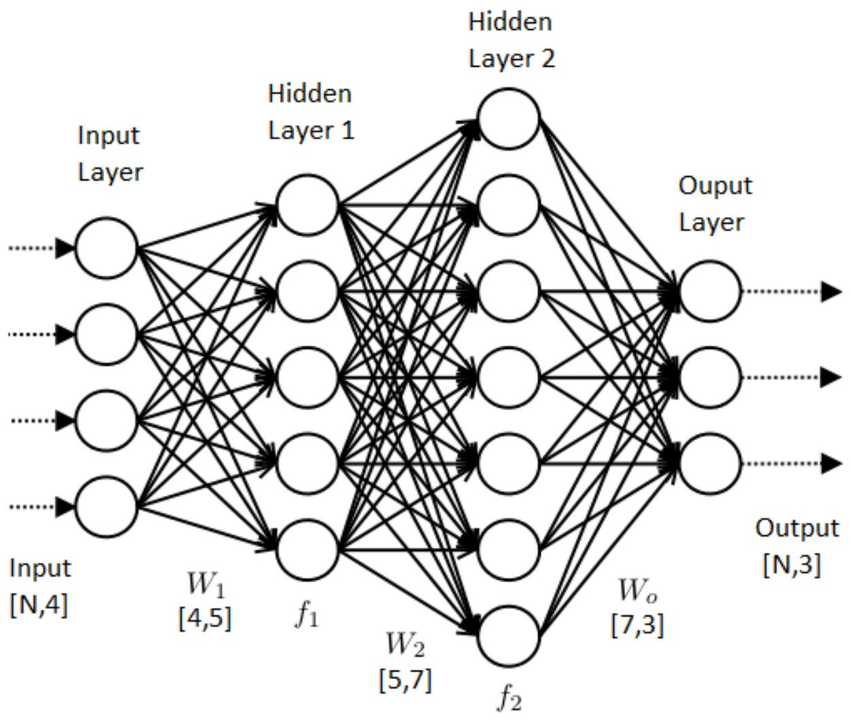
This year we decided to try for a third child (in the meantime we had unexpectedly, but happily, conceived a daughter unassisted). Given our challenges conceiving naturally and our advancing ages (we’re both 35), we decided to do another embryo creation cycle, to have embryos available for the future. We wanted to use Orchid’s Whole-Genome Preimplantation Genetic Sequencing (PGT-WGS) this time*, instead of the more common Preimplantation Genetic Testing for Aneuploidy (PGT-A).
Now that we’ve been through two IVF cycles — one guided by PGT-A, and one using PGT-WGS — I wanted to walk through what each cycle looked like for us, and highlight the places where PGT-WGS gave us more, or higher-quality, information than our 2019 PGT-A cycle:
- The improved aneuploidy screening from PGT-WGS gave us confidence that our euploid embryos were euploid, and our aneuploid embryos were aneuploid — unlike during our first cycle.
- PGT-WGS detected an embryo with whole-genome Uniparental Isodisomy (UPD), which was not only non-viable, potentially resulting in a molar pregnancy, but would have presented a health risk to my wife.
- Monogenic screening on the ~1,200 genes on the Hereditary Cancer, Birth Defect, and Neurodevelopmental Disorder panels gave us a level of confidence that we had reduced the risk of severe genetic disease.
- When selecting an embryo to transfer, genetic risk let us prioritize an embryo which had a lower risk for inflammatory bowel disease.
(I’m including minimally-redacted versions of the embryo data, aneuploidy plots, and PGT results from our cycles in this post. Please reach out if there’s additional information you’d like to see).
Retrieval cycle
Many IVF centers have strict policies on embryo transfers — for example, refusing to transfer any embryo with a monogenic finding. It’s important to pick a clinic and a physician comfortable with the information provided by PGT-WGS, who will work with you, as a patient, when deciding which embryo to transfer.
We chose a nearby Kindbody location for our embryo retrieval and transfer — the friends who recommended Kindbody had explicitly mentioned the patient-centric experience. Our local Kindbody location already worked with Orchid, and our physician was very familiar with the additional information available in a PGT-WGS report, so including Orchid in our cycle plan was easy.
We retrieved 13 eggs; 11 of those eggs were mature and successfully fertilized. 9 of those embryos developed enough to be biopsied; Kindbody performed a standard embryo biopsy and shipped the biopsies to Orchid for PGT-WGS testing.
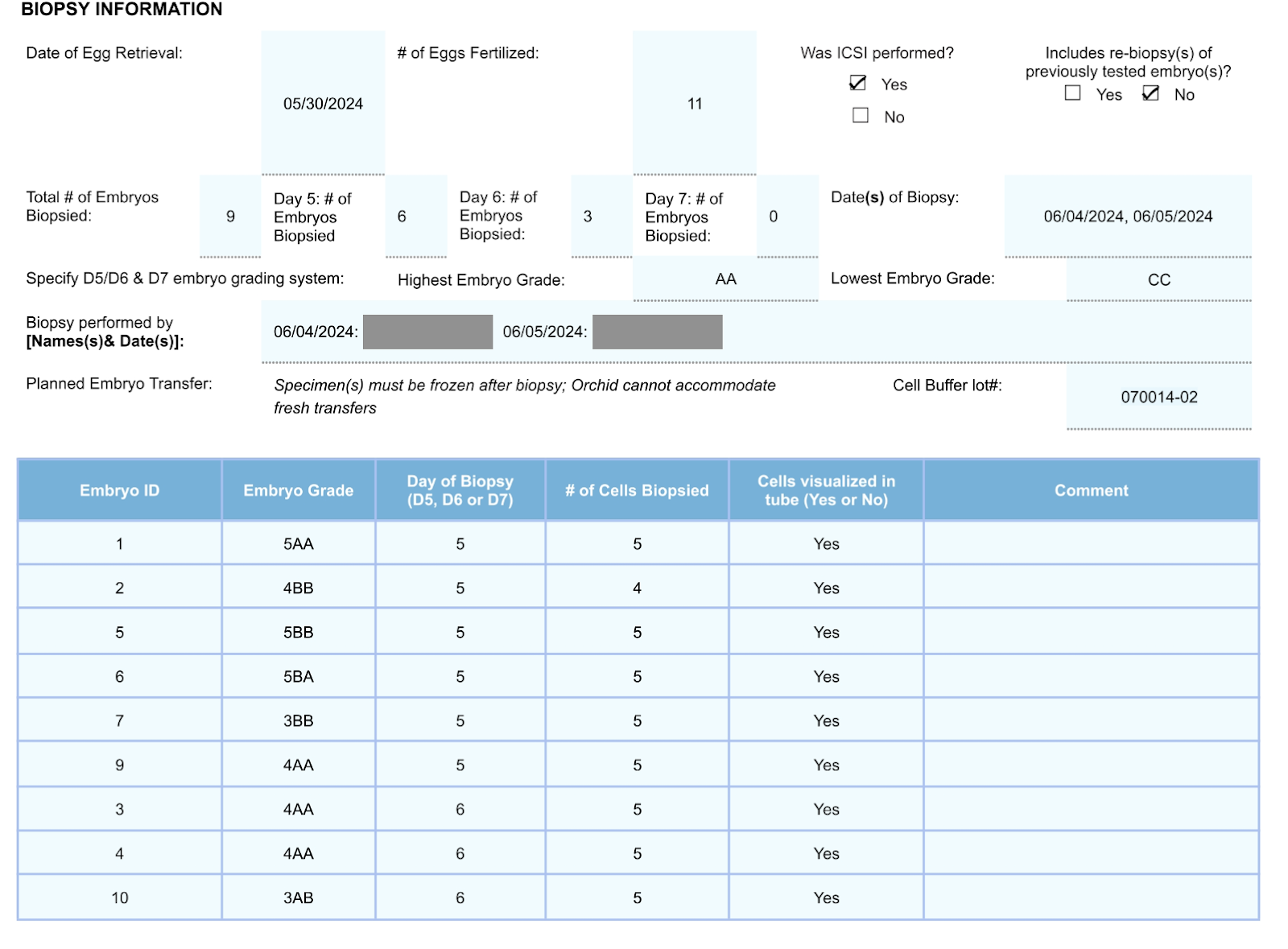
We were happy with these results so far. If found to be chromosomally normal after PGT, the 4 “Excellent” embryos would have a 65% to 80% chance of resulting in a pregnancy. Even the two “Average” embryos would have over 50% odds of pregnancy.
A few weeks later, we got our PGT-WGS results, and 4 of the embryos were euploid, in line with expectations for our ages (in our age bracket, about 46% of embryos will be euploid).
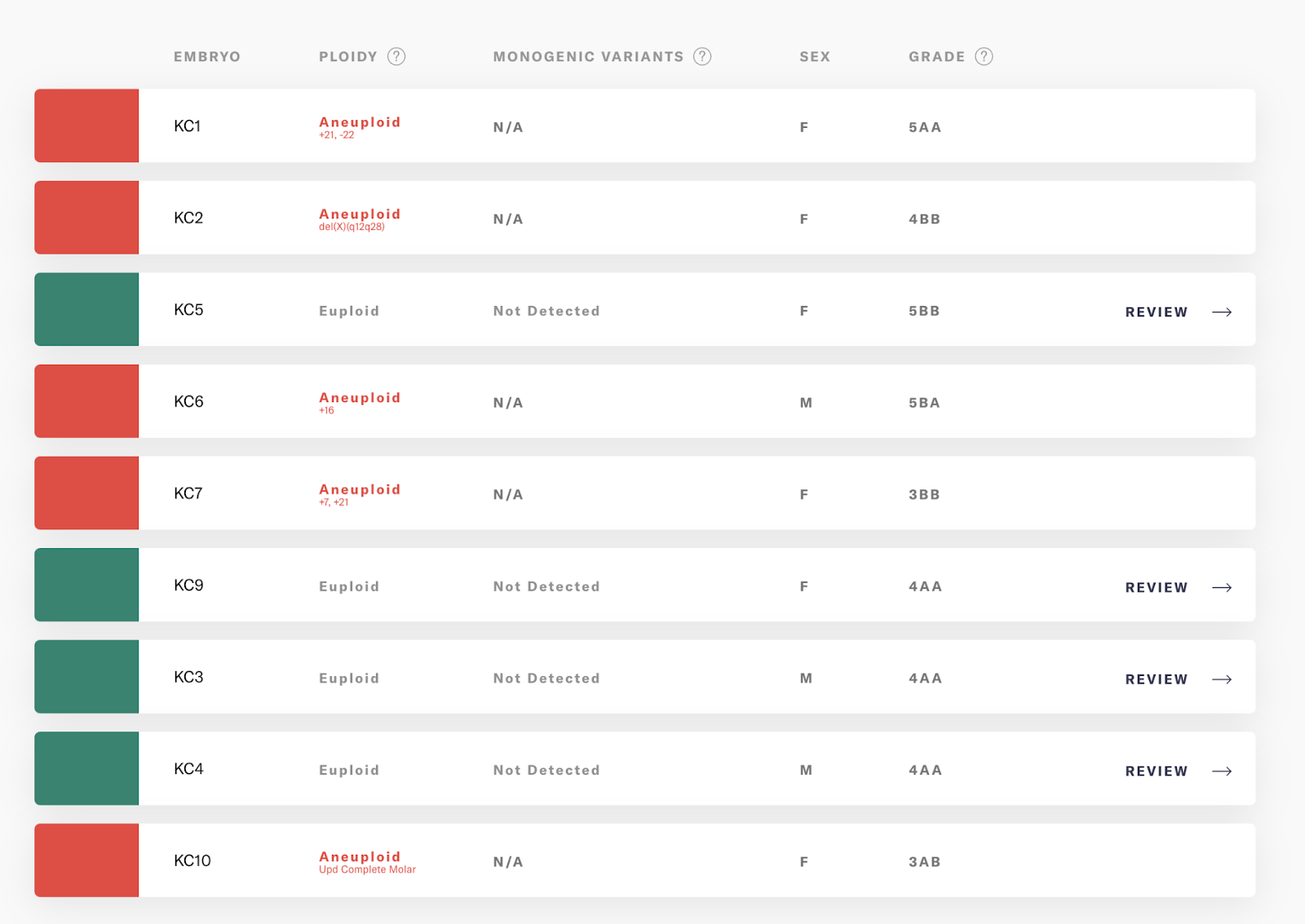
Better PGT-A through PGT-WGS
I’ll break down these results, and how they compare to our previous PGT-A test.
4 of our embryos were euploid — 2 male, 2 female. 5 were aneuploid — 4 with large chromosome duplications or deletions, and one case of whole-genome UPD. I’ll talk more about that one below.
Keeping more embryos
After losing potentially viable embryos to noisy PGT-A in our first cycle, better aneuploidy screening was our driving motivation for using PGT-WGS — we wanted to be confident that the aneuploidy results were real.
As a reminder, the IVF clinic in our first PGT-A cycle had discarded 3 embryos with “aneuploid” results not strongly supported by the raw data — two embryos had been reported as “Chaotic” (likely noise from a poor-quality biopsy rather than true aneuploidy) and one as “Aneuploid” (when re-analyzed, a low-level mosaic)
The embryos called aneuploid in our PGT-WGS cycle, on the other hand, showed very clear gains and losses of chromosomes. As it happened, one embryo from each cycle had a Trisomy 21. Below, you can visually compare a “Chaotic” embryo from the first cycle (top), a Trisomy 21 embryo from PGT-A first cycle (middle), and a Trisomy 21 embryo from our PGT-WGS cycle (bottom):
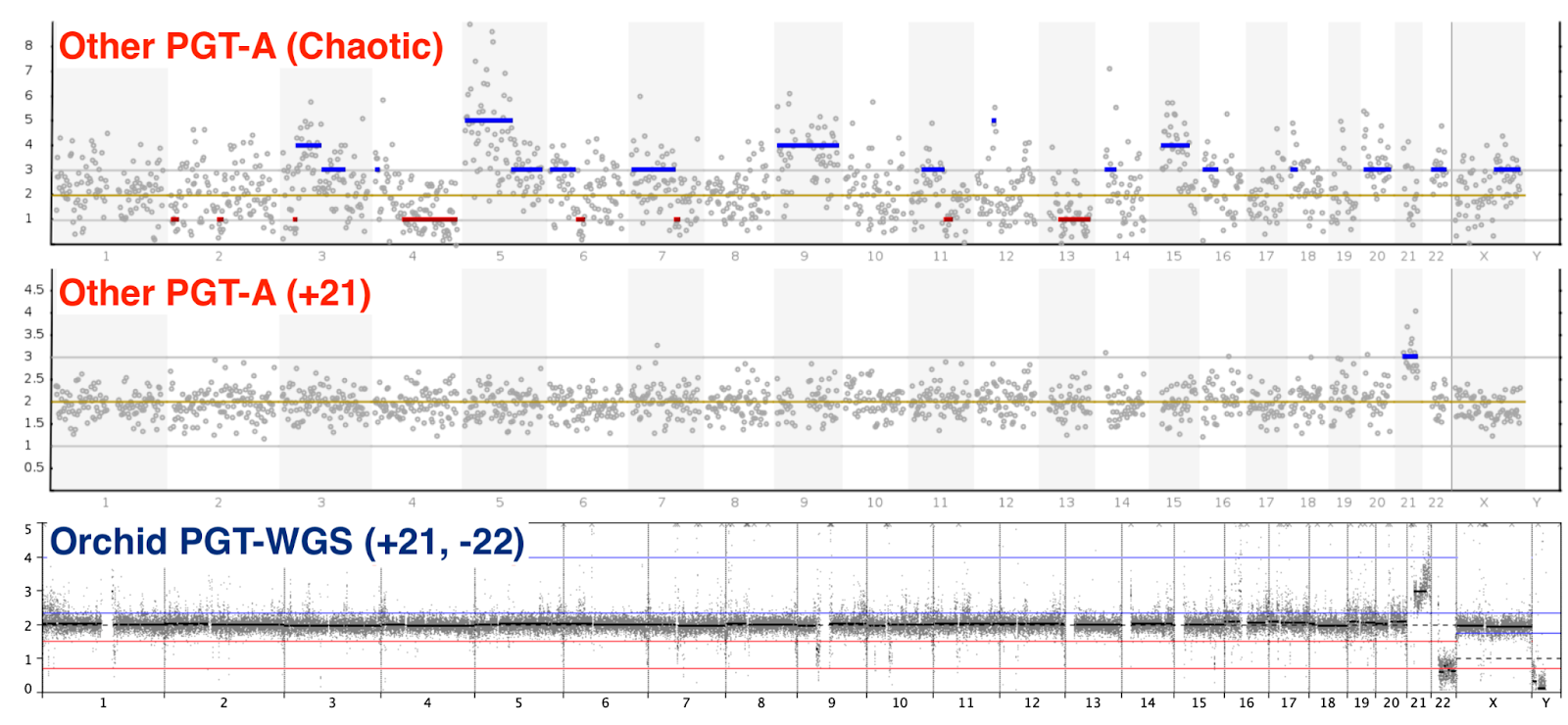
(A quick guide to interpreting these plots: PGT-A measures the number of copies of each section of your genome. Chromosomally normal humans have 2 copies of chromosomes 1-22 (one from the father, one from the mother). Male embryos have a single X chromosome and a single Y chromosome, while female embryos have 2 X chromosomes and 0 Y.
On the PGT-A plot, this means that chromosomes 1-22 should have points centered on the “2” line of the CN plot. Males will have a signal of “1” for the X chromosome and “1” for the Y chromosome, while females will have an X at “2” and little to no signal for the Y chromosome. Small variations above and below are due to difficulty in sequencing DNA from the 3-5 cells in an embryo biopsy.)
After requesting the raw data, we could visually see the higher resolution and more consistent genome coverage in the PGT-WGS results, and felt more confident we were discarding only embryos with true aneuploidy.
Detecting smaller aneuploidy
Of course, it was just as important that the embryos we did select for transfer were healthy. We wanted to use PGT-WGS to screen for clinically significant gains or losses of chromosomes that wouldn’t be caught by standard PGT-A.
PGT-WGS can detect chromosomal abnormalities smaller than standard PGT-A. Standard PGT-A will report segmental chromosome gains and losses down to about 10 million base pairs, while Orchid PGT-WGS detects gains and losses down to 400,000 base pairs in specific regions linked to disease (not all small chromosomal insertions or deletions cause problems in a child). These regions are included in Orchid’s Microduplications and deletions screening panel.

This screening is possible due to the higher resolution and more consistent coverage achievable by PGT-WGS. We can look at the raw data from the embryo we transferred during our PGT-A cycle (top), and a simplified PGT-A visualization from the embryo we transferred during our recent PGT-WGS cycle (bottom).

To be clear, there weren’t any issues to catch in the top embryo — our now-3-year old son is perfectly healthy — but the extra screening lets us sleep a bit better, knowing we did our best to prevent microduplications and deletions which could result in autism, developmental delays, or failure to thrive in our child.
Preventing a molar pregnancy
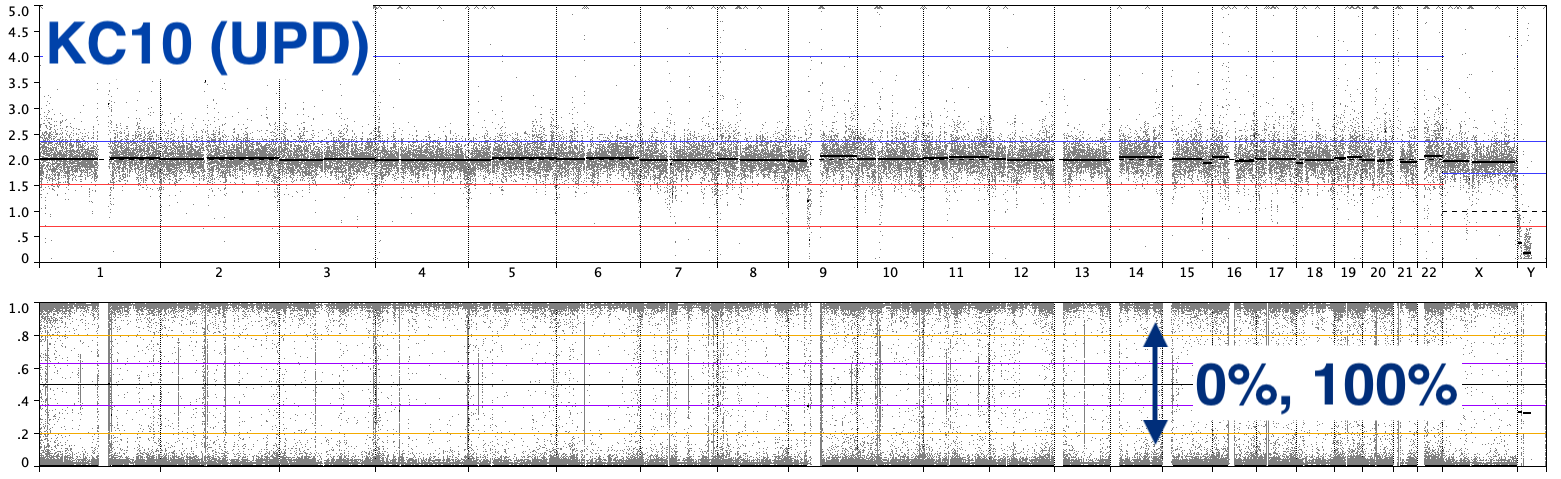
Last, but potentially most importantly — an embryo was found to have genome-wide Uniparental isodisomy (UPD). Embryos with full UPD which successfully implant result in a molar pregnancy — a growth of irregular cells rather than a developed fetus.
A molar pregnancy is not viable. Most will miscarry early in pregnancy, but the ones that don’t miscarry will need to be terminated, often surgically. In rare cases, the molar cells may become cancerous if not fully removed. Even in the best case, a transfer which resulted in a molar pregnancy would have significantly delayed our family planning, a big setback at our age (we’re already 35), as women are asked to avoid pregnancy for 6 to 12 months after the termination of a molar pregnancy.
While PGT labs provide screening for women with a history of molar pregnancies, standard PGT-A would not detect UPD in a couple like us without a history of molar pregnancy. PGT-WGS, by performing whole-genome sequencing, can detect conditions which appear to be a euploid embryo during the PGT-A screening in many labs, such as Uniparental isodisomy and triploidy.
(To go a bit deeper. If you only look at chromosome counts, KC10, an embryo with UPD looks very similar to KC9, a euploid female — each embryo has two copies of each chromosome, the top plot in each figure.
However, we can overlay the variant-level information available via PGT-WGS to distinguish the two. Most variants in a viable euploid embryo will be inherited only from a single parent and show up at 50% frequency (ie, heterozygous). However, since KC10 has two copies of the same chromosome, you only see variants at 100% frequency (ie, homozygous)).

Past PGT-A — Screening for disease
Monogenic variants
PGT-WGS allows us to screen for single-gene disorders that PGT-A will not detect. Orchid’s PGT-WGS screening offers screening on about 1,200 genes linked to serious disease on four screening panels — Neurodevelopmental disorders, Birth defects, Hereditary cancer, and ACMG secondary findings.
None of our embryos had monogenic findings:
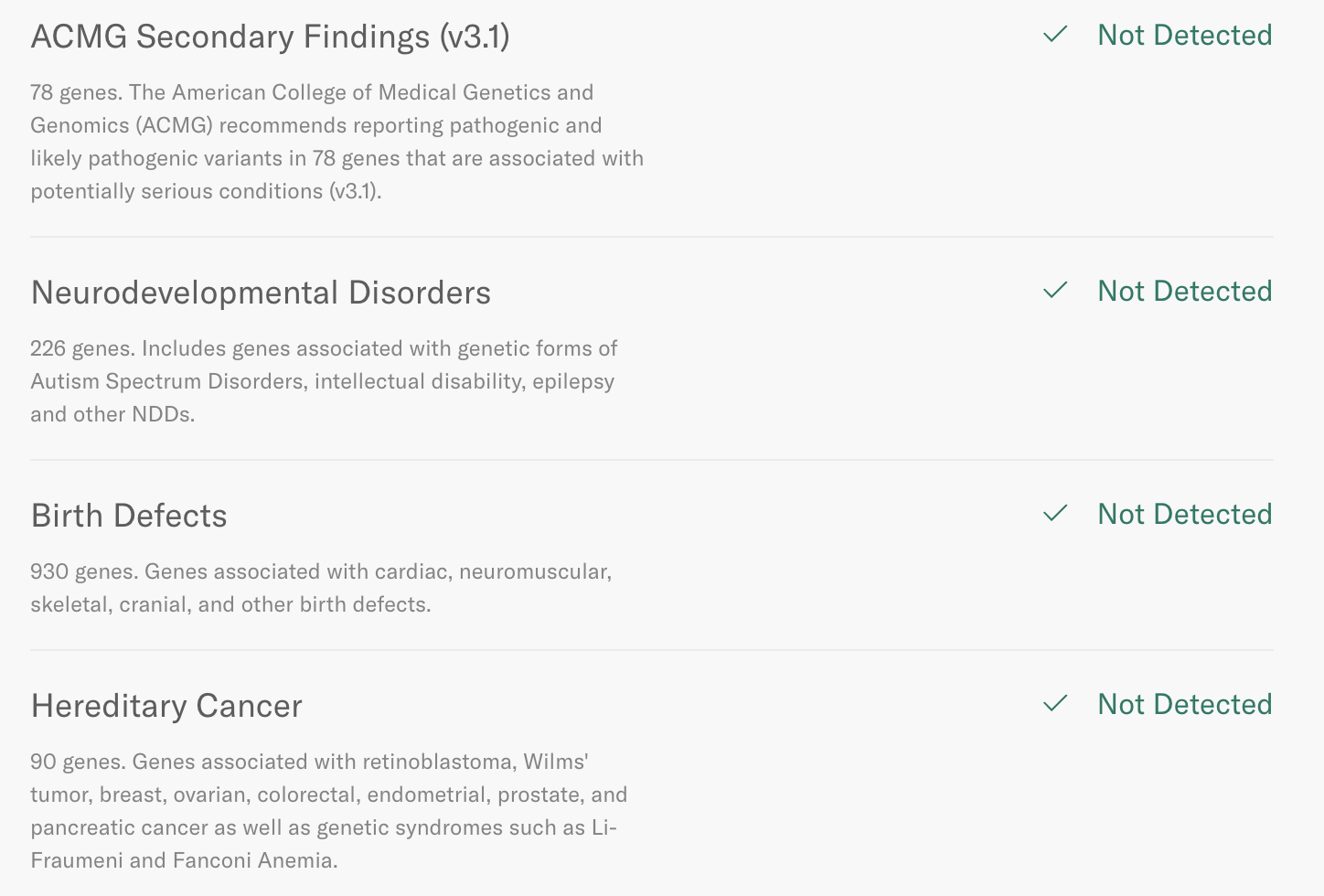
This was a relief, but not a shock — about 3-4% of embryos have monogenic findings, so it was likely that PGT-WGS wouldn’t find any variants linked to inherited disease on our 4 euploid embryos.
Genetic risk scores
While the whole-genome sequencing data captured during PGT-WGS is primarily used to detect pathogenic variants during the monogenic screening I just described, it also allows us to compute the genetic risk for each embryo, measuring their predisposition to 11 chronic diseases (many of which are adult-onset). This testing is optional, if parents feel comfortable with the extra information available.
The risk of each disease is presented as compared to the population average, and will look something like the below (these are the risks for KC4):
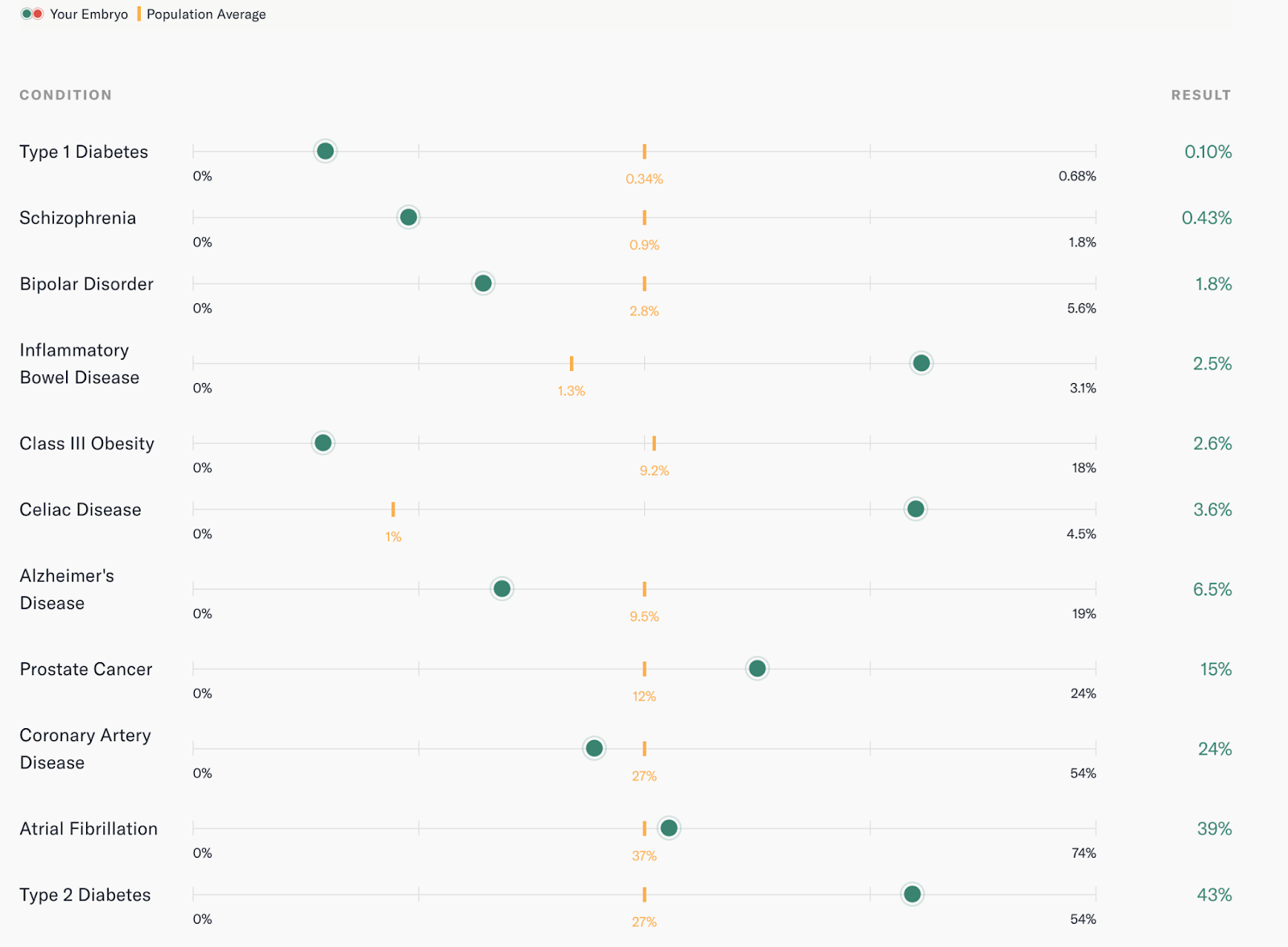
Comparing the risk of disease to the population average is critical when putting these risks into context. An embryo with a monogenic finding has an extremely high chance of inheriting a disease, and a couple with a monogenic finding may choose not to transfer such an embryo.
By contrast, an embryo with a high genetic risk score (also known as a polygenic risk score) may still have a relatively small absolute risk for a disease (the rightmost column). Genetic risk scores are a useful tool for prioritizing an embryo to transfer, in the absence of other information (especially when coupled with a family history of disease). While my wife and I would have been happy to transfer any of our viable embryos, these scores gave us a way to minimize the risks of specific diseases (more on this later).
Transfer guided by PGT-A
In our PGT-A cycle, the decision about which embryo to transfer was pretty simple. In fact, for most couples, the consultation is pro-forma — your IVF physician will pick the embryo they want to transfer. For us, that was the highest quality euploid embryo, KC-6 (“good”):
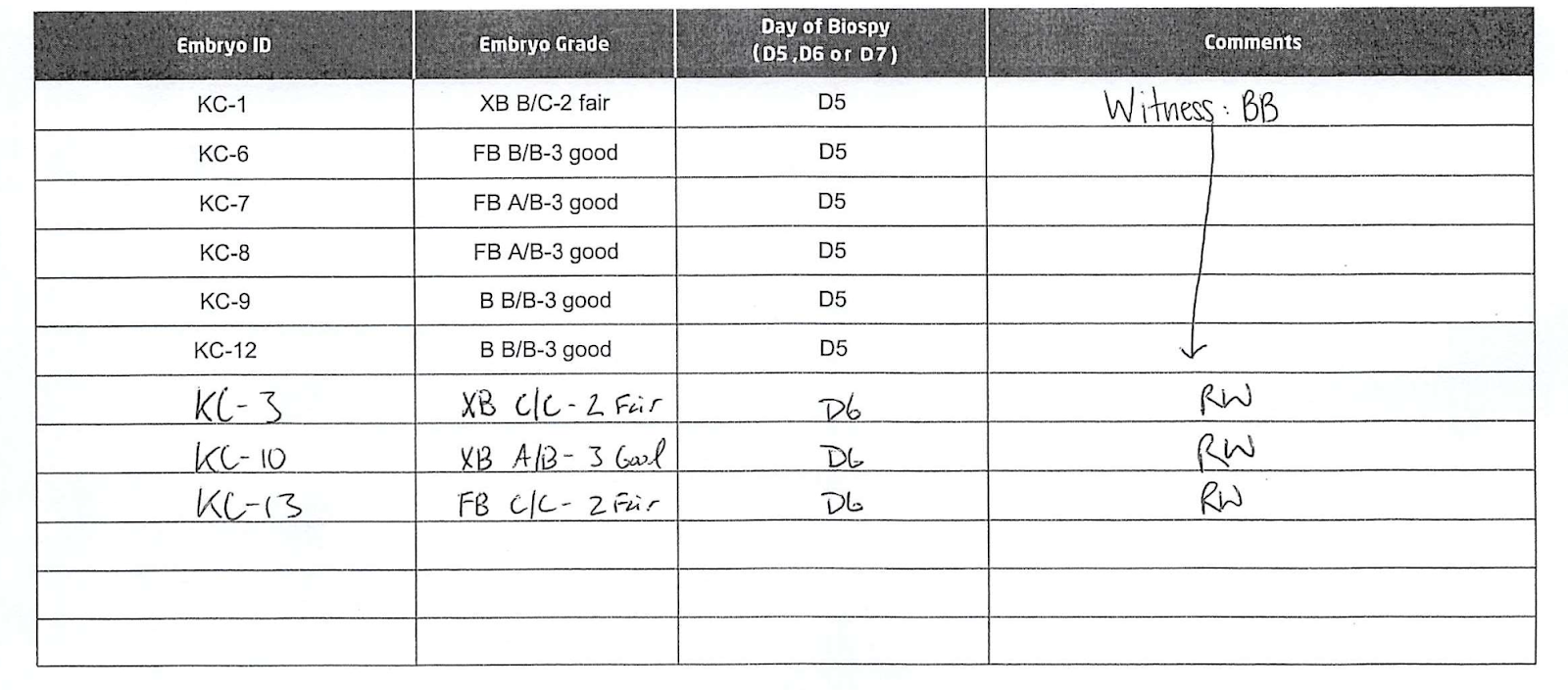
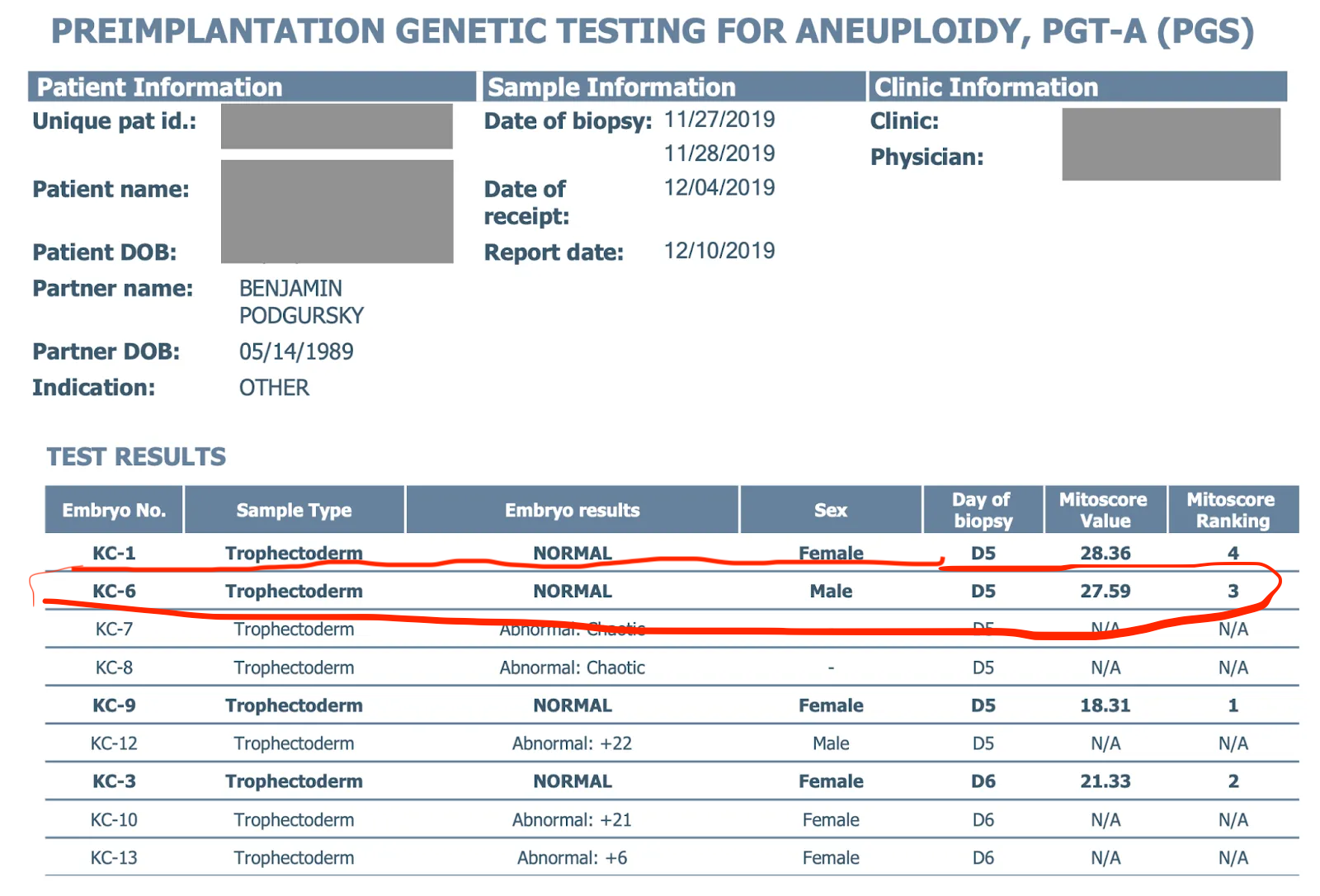
Our fertility clinic suggested the highest-grade euploid embryo, KC-6, which we transferred successfully, and resulted in our first child, a healthy boy.
Transfer informed by PGT-WGS
In our PGT-WGS cycle, my wife and I had more information to work with.
If there wasn’t a downside, we’d always liked the idea of alternating boy/girl/boy/girl. Since we’d most recently had a daughter, we decided to look at KC-3 and KC-4, the two male embryos. Both embryos were grade 4AA — one of the highest embryo grades — so we had no reason to think that one would have a higher chance of successful transfer than the other. And since neither embryo had monogenic findings to consider, we looked at the genetic risk scores for the two embryos.
There are a few ways to visualize genetic risk scores, but in my opinion it’s easiest to interpret genetic risk when the risk is mapped to an estimate of the absolute disease risk, which is how Orchid presents it. We were able to compare the absolute disease risk for KC3 and KC4, the two male embryos, side-by-side:
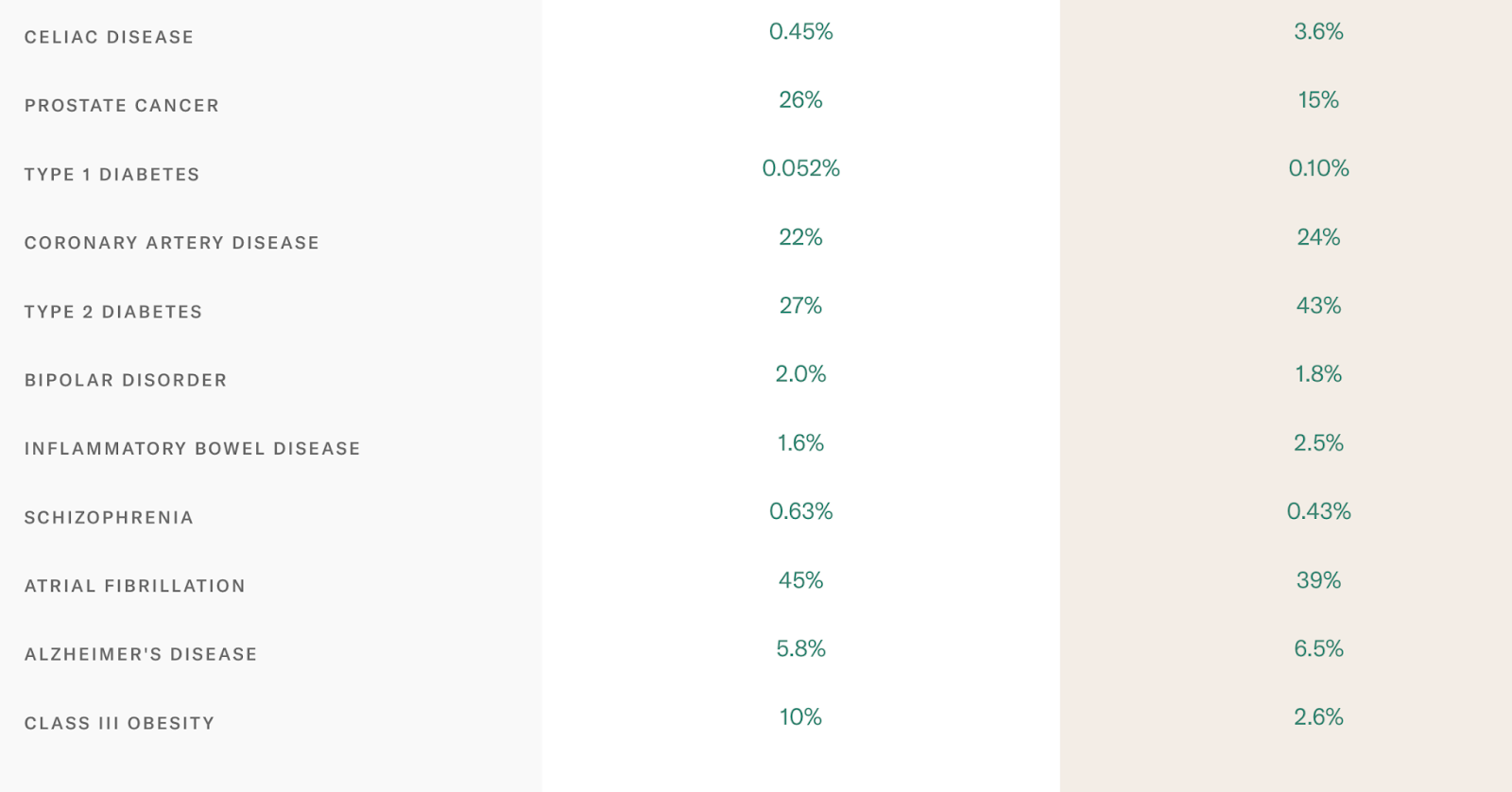
Both sides of our family had a history of serious mental health issues (first-degree relatives with diagnosed Schizophrenia, and severe anxiety). If one embryo had had a meaningfully reduced risk of Schizophrenia or Bipolar disorder, we would have prioritized it for transfer, but in this case, the differences were negligible.
However, several other diseases had meaningful differences. KC3 had a markedly higher risk of prostate cancer, while KC4 was at higher risk for Inflammatory Bowel Disease and Celiac Disease — autoimmune disorders of the digestive system.
My wife and I took a couple days to discuss how we felt about this tradeoff. Prostate cancer is a real disease, but it’s a late-onset disease with an extremely low mortality rate, given appropriate preventative screening — easy to arrange, especially if a child knows they have a predisposition towards the disease. On the other hand, our daughter had struggled with hard-to-diagnose stomach pain and slow weight gain for the first year after she started solid food. While her symptoms had mostly resolved, IBD and Celiac are frequently lifelong afflictions and can’t be easily treated (so far, anyway).
We both agreed we’d prefer to put our finger on the scale and reduce the risk of infant digestive problems by transferring KC3 first. We let Kindbody know about our decision, and scheduled a transfer for a couple weeks later.
Looking forward
We were optimistic about our chance of a successful transfer, given our PGT-WGS screening, a good embryo grade, and a history of successful transfers — but that didn’t make the wait any less anxious. But a few weeks later, we got a positive test, and a clean ultrasound a few weeks after that — the transfer had been successful.

PGT-WGS, and especially genetic risk scores, can’t guarantee a healthy child. But by screening for aneuploidy at higher resolution than standard PGT-A, screening for monogenic findings, and finally prioritizing based on genetic risk, we were happy we had done what we could to reduce the risk of preventable disease. Just as importantly, PGT-WGS helped us reduce the risk of discarding viable embryos and reduce the risk of pregnancy complications for my wife.
To wrap things up, I want to really highlight the points where PGT-WGS gave us information we would not have gotten otherwise:
- PGT-WGS allowed us to avoid transferring an embryo which would, if transferred successfully, have resulted in a molar pregnancy — a significant health risk to my wife, and at minimum a big setback in our family planning goals (6-12 month delay) .
- Whole-genome screening gave us confidence that our euploid embryos were really euploid, and our aneuploid embryos were really aneuploid. After discarding 3 potentially viable embryos in our first cycle due to poor PGT-A, this was important to us.
- Monogenic screening reduced the risk of rare diseases linked to serious health problems.
- Prioritizing embryos based on genetic risk is usually debated in the abstract, rather than in the context a real IVF cycle. Like real families, my wife and I used genetic risk as a prioritization tool, not a filter. It’s very possible we’ll end up transferring all the euploid embryos from this cycle, and have no qualms doing so!
The last thing I want to mention is that the Kindbody patient experience is the best of any IVF center we’ve worked with (long story, but this is the fourth). IVF is a stressful process, and even minor mixups in communication, ambiguity around timelines, or delay filling a prescription can be frustrating. But at Kindbody we had 0 issues getting an immediate response from our support staff when we had problems.
This is already long, so I’ll leave it here. I’m happy to answer any other questions about our experience in either cycle — please feel feel to reach out, either here or by email. We’ve learned a ton through this process and nothing makes me happier than paying it forward.
* I’m writing this up from my and my wife’s experience as patients, but I lead the engineering team at Orchid. I’ve also published a copy of this on guides.orchidhealth.com.














{kind=link}