Or: I Thought I was a Programmer but now I’m worried I’m a High Modernist.
Seeing like a State by James C. Scott is a rallying cry against imperialist high modernism. Imperialist high modernism, in the language of the book, is the thesis that:
- Big projects are better,
- organized big is the only good big,
- formal scientific organization is the only good system, and
- it is the duty of elites leading the state to make these projects happen — by force if needed
The thesis sounds vague, but it’s really just big. Scott walks through historical examples to flesh out his thesis:
- scientific forestry in emerging-scientific Europe
- land reforms / standardization in Europe and beyond
- the communist revolution in Russia
- agricultural reforms in the USSR and Tanzania
- modernist city planning in Paris, Brazil, and India
The conclusion, gruesomely paraphrased, is that “top-down, state-mandated reforms are almost never a win for the average subject/victim of those plans ”, for two reasons:
- Top-down “reforms” are usually aimed not at optimizing overall resource production, but at optimizing resource extraction by the state.
Example: State-imposed agricultural reforms rarely actually produced more food than peasant agriculture, but they invariably produced more easily countable and taxable food
- Top-down order, when it is aimed at improving lives, often misfires by ignoring hyper-local expertise in favor of expansive, dry-labbed formulae and (importantly) academic aesthetics
Example: Rectangular-gridded, mono-cropped, giant farms work in certain Northern European climates, but failed miserably when imposed in tropical climates
Example: Modernist city planning optimized for straight lines, organized districts, and giant apartment complexes to maximize factory production, but at the cost of cities people could actually live in.
However.
Scott, while discussing how Imperial High Modernism has wrought oppression and starvation upon the pre-modern and developing worlds, neglected (in a forgivable oversight), to discuss how first-world Software Engineers have also suffered at the hands of imperial high modernism.
Which is a shame, because the themes in this book align with the most vicious battles fought by corporate software engineering teams. Let this be the missing chapter.
The Imperial High Modernist Cathedral vs The Bazaar
Imperial high modernist urban design optimizes for top-down order and symmetry. High modernist planners had great trust in the aesthetics of design, believing earnestly that optimal function flows from beautiful form.
Or, simpler: “A well-designed city looks beautiful on a blueprint. If it’s ugly from a birds-eye view, it’s a bad city.”
The hallmarks of high modernist urban planning were clean lines, clean distinctions between functions, and giant identical (repeating) structures. Spheres of life were cleanly divided — industry goes here, commerce goes here, houses go here. If this reminds you of autism-spectrum children sorting M&Ms by color before eating them, you get the idea.
Le Corbusier is the face of high modernist architecture, and SlaS focuses on his contributions (so to speak) to the field. While Le Corbusier actualized very few real-world planned cities, he drew a lot of pictures, so we can see his visions of a perfect city:

True to form, the cities were beautiful from the air, or perhaps from spectacularly high vantage points — the cities were designed for blueprints, and state legibility. Wide, open roads, straight lines, and everything in an expected place. Shopping malls in one district, not mixed alongside residences. Vast apartment blocks, with vast open plazas between.
Long story short, these cookie-cutter designs were great for urban planners, and convenient for governments. But they were awful for people.
- The reshuffling of populations from living neighborhoods into apartment blocks destroyed social structures
- Small neighborhood enterprises — corner stores and cafes — had no place in these grand designs. The “future” was to be grand enterprises, in grand shopping districts.
- Individuals had no ownership of the city they lived in. There were no neighborhood committees, no informal social bonds.
Fundamentally, the “city from on high” imposed an order upon how people were supposed to live their lives, not even bothering to first learn how the “masses” were already living; he swept clean the structures, habits and other social lube that made the “old” city tick.
In the end, the high modernist cities failed, and modern city planning makes an earnest effort to work with the filthy masses, accepting as natural a baseline of disorder and chaos, to help build a city people want to live in.
If this conclusion makes you twitch, you may be a Software Engineer. Because the same aesthetic preferences which ground Le Corbusier’s gears also are the foundation of “good” software architecture; namely:
- Good code is pretty code
- Good architecture diagrams visually appear organized
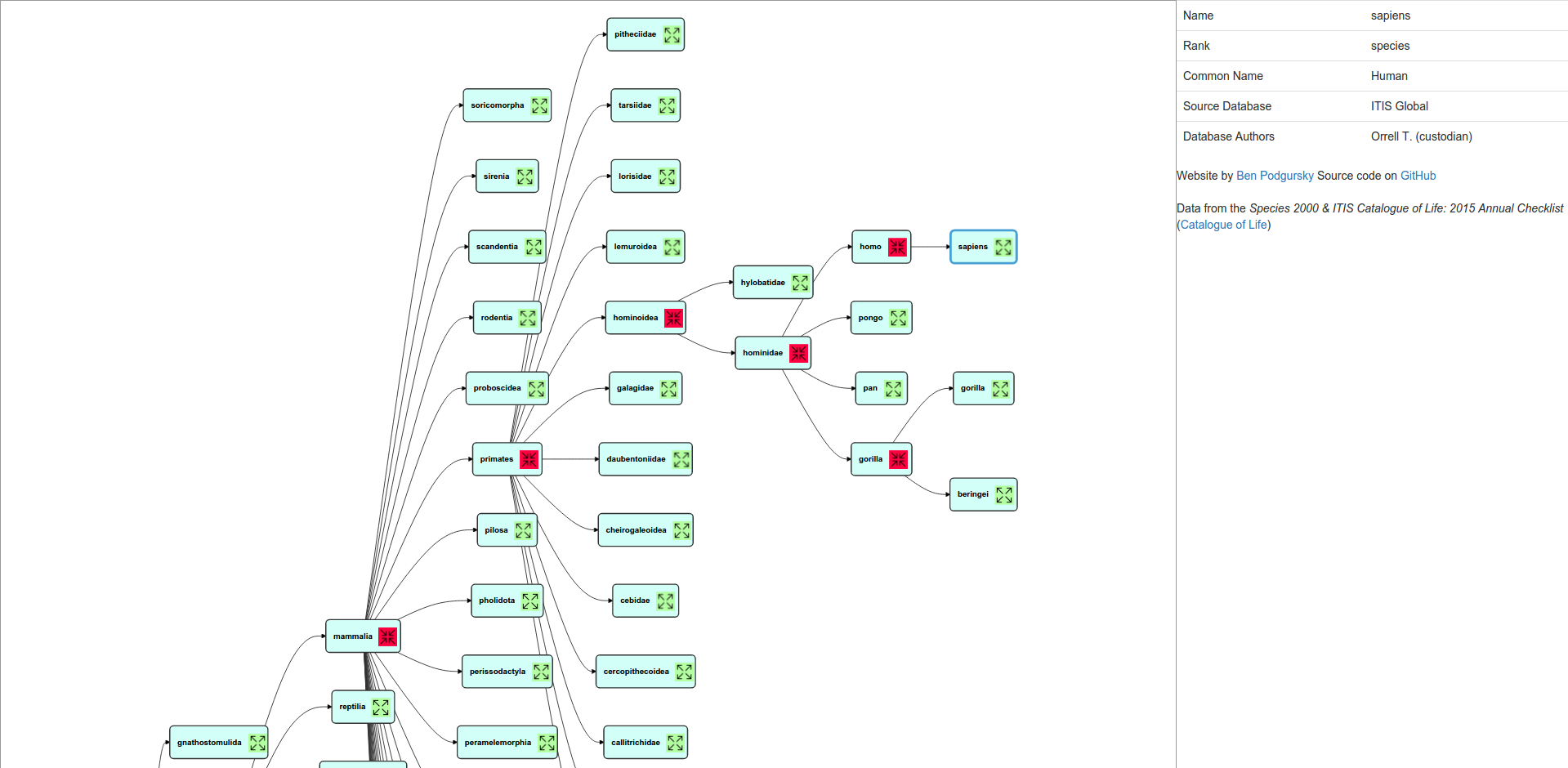
Software devs don’t draft cityscapes, but they do draw Lucidchart wireframes. And a “good” service architecture for a web service would look something like this:
We could try to objectively measure the “good” parts of the architecture:
- Each service has only a couple clearly defined inputs and outputs
- Data flow is (primarily) unidirectional
- Each service appears to do “one logical thing”
But software engineers don’t use a checklist to generate first impressions. Often before even reading the lines, the impression of a good design is,
Yeah, that looks like a decent clean, organized, architecture
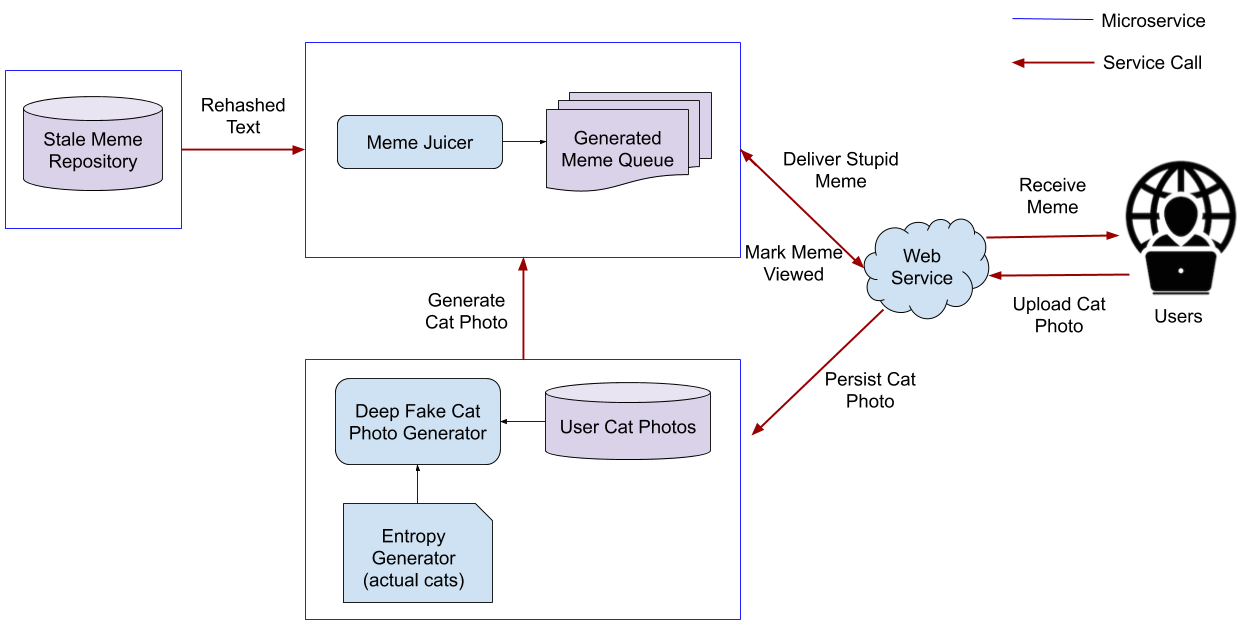
In contrast, a “messy” architecture… looks like a mess:
We could likewise break down why it’s a mess:
- Services don’t have clearly defined roles
- The architecture isn’t layered (the user interacts with backend services?)
- There are a lot more service calls
- Data flow is not unidirectional
But most software architects wouldn’t wade through the details on first glance. The first reaction is:
Why are there f******* lines everywhere??? What do these microservices even do? How does a user even… I don’t care, burn it.
In practice, most good engineers are ruthless high modernist fascists. Unlike the proto-statist but good-hearted urban planners of the early 1900s (“workers are dumb meat and need to be corralled like cattle, but I want them to be happy cows!”), we wrench the means of production from our code with blood and iron. Inasmuch as the subjects are electrons, this isn’t a failing of the system — it’s the system delivering.
Where this aesthetic breaks down is when these engineers have to coordinate with other human beings — beings who don’t always share the same vision of a system’s platonic ideals. To a perfectionist architect, outside contributions risk tainting the geometric precision with which a system was crafted.
Eric S Raymond famously summarized the two models for building collaborative software in his essay (and later, book): The Cathedral and the Bazaar
Unlike in urban planning, the software Cathedral came first. Every man dies alone, and every programmer codes solo. Corporate, commercial cathedrals were run by a lone (or small team) of ruthless God Emperors, carefully vetting contributions for coherence to a grander plan. The essay summaries the distinctions better than I can rehash, so I’ll quote in length.
The Cathedral model represents mind-made-matter diktat from above:
I believed that the most important software (operating systems and really large tools like Emacs) needed to be built like cathedrals, carefully crafted by individual wizards or small bands of mages working in splendid isolation, with no beta to be released before its time.
The grand exception to this pattern was an upstart open-source Operating System you may have heard of — Linux. Linux took a different approach to design, welcoming with open arms external contributions and all the chaos and dissent they brought:
Linus Torvalds’s style of development – release early and often, delegate everything you can, be open to the point of promiscuity – came as a surprise. No quiet, reverent cathedral-building here – rather, the Linux community seemed to resemble a great babbling bazaar of differing agendas and approaches (aptly symbolized by the Linux archive sites, who’d take submissions from anyone) out of which a coherent and stable system could seemingly emerge only by a succession of miracles.
Eric predicted that the challenges of working within the chaos of the Bazaar — the struggle of herding argumentative usenet-connected cats in a common direction — would be vastly outweighed by the individual skills, experience, and contributions of those cats:
I think the future of open-source software will increasingly belong to people who know how to play Linus’ game, people who leave behind the cathedral and embrace the bazaar. This is not to say that individual vision and brilliance will no longer matter; rather, I think that the cutting edge of open-source software will belong to people who start from individual vision and brilliance, then amplify it through the effective construction of voluntary communities of interest.
Eric was right — Linux dominated, and the Bazaar won. In the open-source world, it won so conclusively that we pretty much just speak the language of the bazaar:
- “Community contributions” are the defining measure of health for an Open Source project. No contributions implies a dead project.
- “Pull Requests” are how outsiders contribute to OSS projects. Public-editable project wikis are totally standard documentation. Debate (usually) happens on public mailing lists, public Slacks, public Discord servers. Radical transparency is the default.
I won’t take this too far — most successful open-source projects remain a labor of love by a core cadre of believers. But very few successful OSS projects reject outside efforts to flesh out the core vision, be it through documentation, code, or self-machochistic user testing.
The ultimate victory of the Bazaar over the Cathedral mirrors the abandonment of high modernist urban planning. But here it was a silent victory; the difference between cities and software, is that dying software quietly fades away, while dying cities end up on the evening news and on UNICEF donation mailers. The OSS Bazaar won, but the Cathedral faded away without a bang.
Take that, Le Corbusier!
High Modernist Corporate IT vs Developer Metis
At risk of appropriating the suffering of Soviet peasants, there’s another domain where the impositions of high modernism parallel closely with the world of software — in the mechanics of software development.
First, a definition: Metis is a critical but fuzzy concept in SlaS, so I’ll attempt to define it here. Metis is the on-the-ground, hard-to-codify, adaptive knowledge workers use to “get stuff done”. In context of farming, it’s:
“I have 30 variants of rice, but I’ll plant the ones suited to a particular amount of rainfall in a particular year in this particular soil, otherwise the rice will die and everyone will starve to death”
Or in the context of a factory, it’s,
“Sure, that machine works, but when it’s raining and the humidity is high, turning it on will short-circuit, arc through your brain, and turn the operator into pulpy organic fertilizer.”
and so forth.
In the context of programming, metis is the tips and tricks that turn a mediocre new graduate into a great (dare I say, 10x) developer. Using ZSH to get git color annotation. Knowing that, “yeah Lambda is generally cool and great best practice, but since the service is connected to a VPC fat layers, the bursty traffic is going to lead to horrible cold-start times, customers abandoning you, the company going bankrupt, Sales execs forced to live on the streets catching rats and eating them raw.” Etc.
Trusting developer metis means trusting developers to know which tools and technologies to use. Not viewing developers as sources of execution independent of the expertise and tools which turned them into good developers.
Corporate IT — especially at large companies— has an infamous fetish for standardization. Prototypical “standardizations” could mean funneling every dev in an organization onto:
- the same hardware, running the same OS (“2015 Macbook Airs for everyone”)
- the same IDE (“This is a Visual Studio shop”)
- an org-wide standard development methodology (“All changes via GitHub PRs, all teams use 2-week scrum sprints”)
- org-wide tool choices (“every team will use Terraform V 0.11.0, on AWS”)
If top-down dev tool standardization reminds you of the Holodomor, the Soviet sorta-genocide side-effect of dekulakizatizing Ukraine, then we’re on the same page.
To be fair, these standardizations are, in the better cases, more defensible than the Soviet agricultural reforms in SlaS. The decisions were (almost always) made by real developers elevated to the role of architect. And not just developers, but really good devs. This is an improvement over the Soviet Union, where Stalin promoted his dog’s favorite groomer to be your district agricultural officer and he knows as much about farming as the average farmer knows about vegan dog shampoo.
But even good standards are sticky, and sticky standards leave a dev team trapped in amber. Recruiting into a hyper-standardized org asymptotically approaches “take and hire the best, and boil them down to high-IQ, Ivy+ League developer paste; apply liberally to under-staffed new initiatives”
When tech startups win against these incumbents, it’s by staying nimble in changing times — changing markets, changing technologies, changing consumer preferences.
To phrase “startups vs the enterprise” in the language of Seeing Like a State: nimble teams — especially nimble engineering teams — can take advantage of metis developer talent to quickly reposition under changing circumstances, while high modernist companies (let’s pick on IBM), like a Soviet collectivist farm, choose to excel at producing standardized money-printing mainframe servers — but only until the weather changes, and the market shifts to the cloud.
Overall
The main thing I struggled with while reading Seeing like a State is that it’s a book about history. The oppression and policy failures are real, but real in a world distant in both space and time — I could connect more more concretely to a discussion of crypto-currency, contemporary public education, or the FDA. Framing software engineering in the language of high modernism helped me ground this book in the world I live in.
Takeaways for my own life? Besides the concrete (don’t collectivize Russian peasant farms, avoid monoculture agriculture at all costs) it will be to view aesthetic simplicity with a skeptical eye. Aesthetic beauty is a great heuristic which guides us towards scalable designs — until it doesn’t.
And when it doesn’t, a bunch of Russian peasants starve to death.