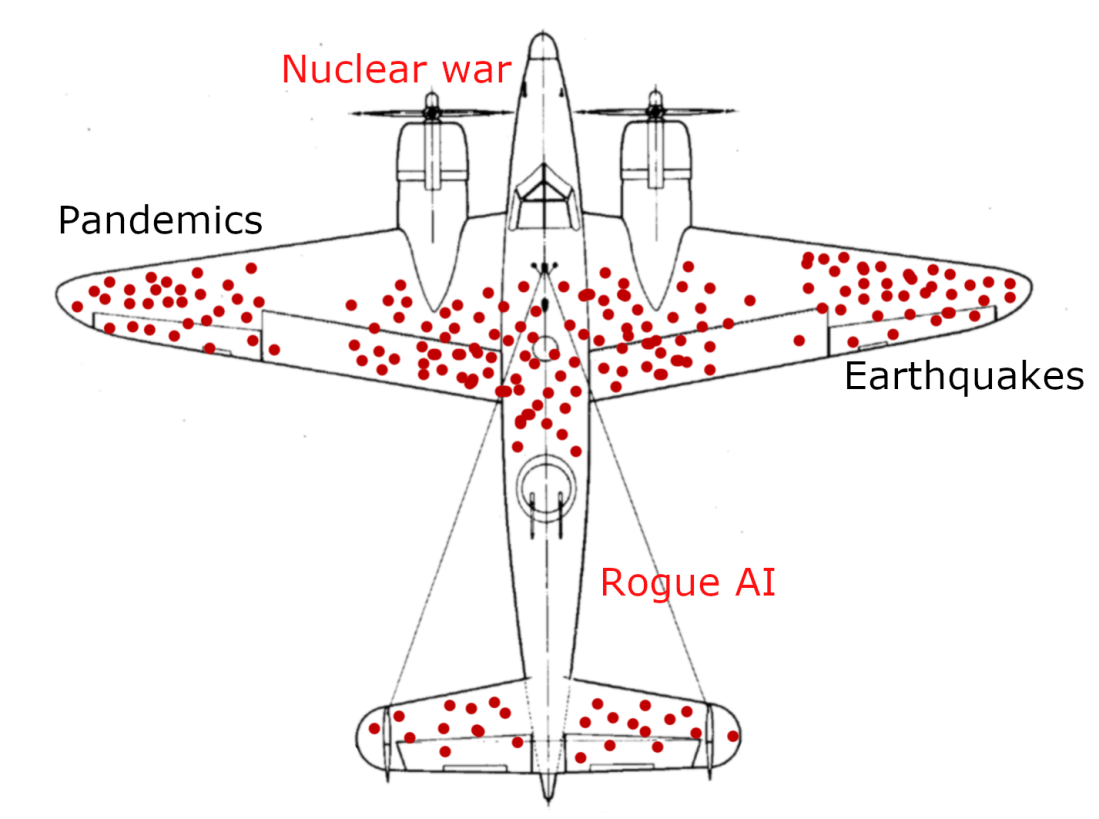
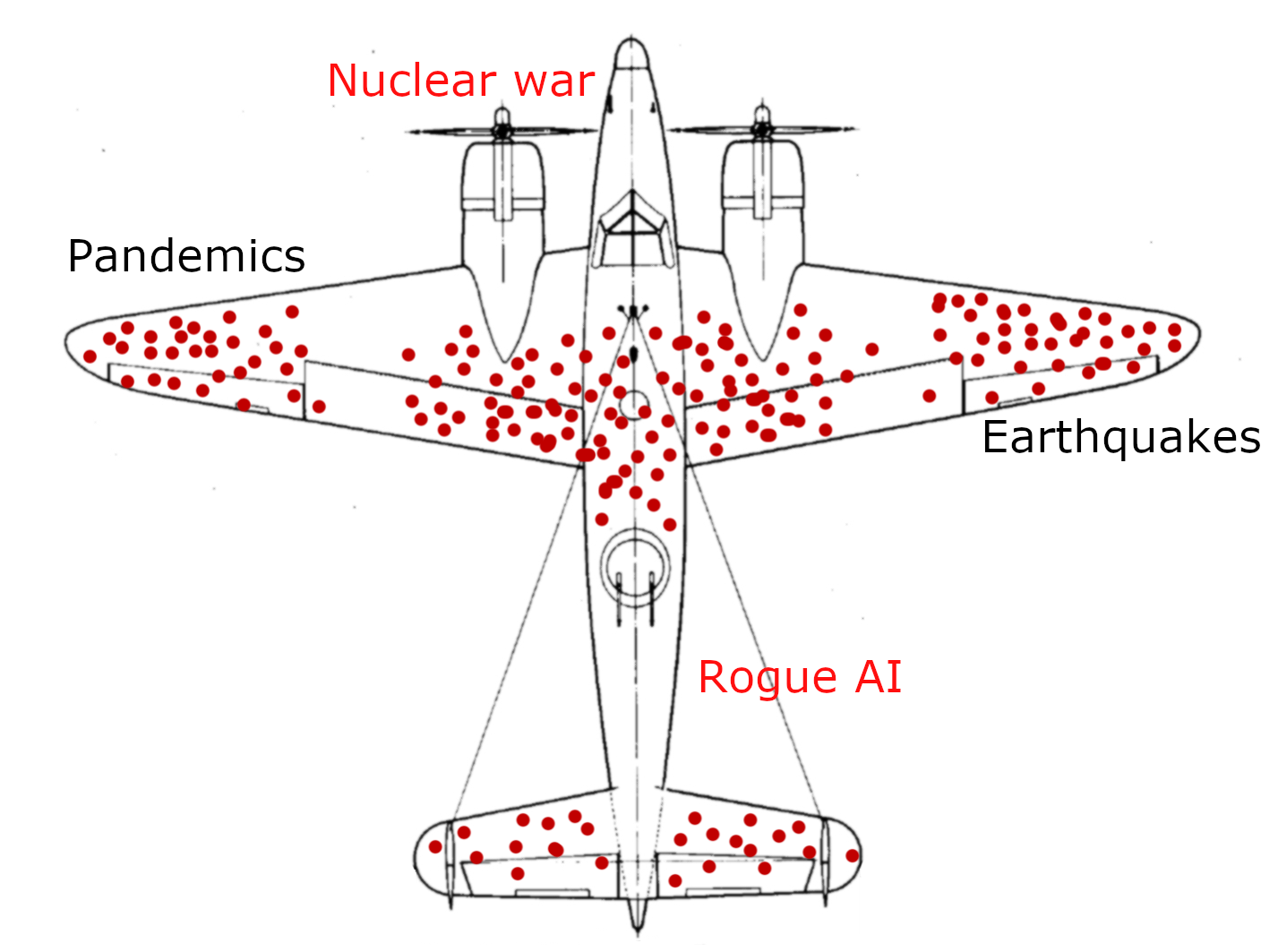
John woke. First wet, then cold.
“Hello John. I’m Paul Mmmdcxxvi”
Paul’s face drifted into focus.
“You froze to death (by the standards of the time) climbing Everest in 2005. You were chipped out of a glacier last week. Thanks to recent medical advances, you defrosted with minimal tissue damage.”
Hrrrngh. “Hrrrrng”
“It is no longer 2005” Paul helpfully added. “But I need to explain a few things, to frame the real date. Take your time. Take a drink.” Paul gestured at a bottle on a nearby table.
John sat upright, drank, and after a few minutes, looked around.
The room was dimly lit, but vast. Behind Paul, extending as far as John could see, stood row upon row of barrels, stacked upwards into complete darkness. Nearby barrels misted slightly. Between rows, up in the air, crawled… something? Somethings?
Behind Paul blinked a single standard LCD monitor — the only clear light.
“How are you feeling, John?” Paul prompted.
“Better.” Surprisingly well, John realized. “So it’s not 2005. When is it?”
“You missed a lot, so I’ll need to start where you left off. I apologize if I’m scattered; please do interrupt” Paul paused, and started:
“Our civilization had two great breakthroughs in the middle of the 21st century.
“The first was moral. The earth struggled with ethics in the early 21st century. We had made great advances in mathematics and physics, but our moral calculus was stagnant by comparison. Good people put together moral frameworks like Utilitarianism, concepts like Quality Years of Life saved, and tools to compute the time-decay discounts for future lives.
“Gradually, a formal field of research emerged — computational ethics. Many of our best minds went to work, and researchers constructed some truly heroic Google Sheet formulas. But at the end of the day, they couldn’t avoid the inherent contradictions.”
“Contradictions?” John objected. “I’m no mathematician, but before I died, I lived a decent life. I still feel bad about stealing Pokemon cards in 5th grade.”
“Not surprising, for a 20th century mind. But you were optimizing for observable, personal moral impact. Computational ethics tried to be scientific about optimizing human morality. For example: how could you justify eating premium Ostrich burgers, while UNICEF struggled to fundraise for famine relief?”
“Well” John admitted, “I assumed my tax dollars mostly took care of that.”
“Naturally. And that’s just the tip of the iceberg. We started with the “easy” optimization, maximizing Quality Years of Life. It worked well at first; we eliminated Polio, hunger, and male-pattern-baldness. But we got stuck. It turned out there was no way to optimize out suicide, but leave BASE jumping as a optional joie de vivre. Or leave potato chips. Or leave the fun game where teenagers shoot fireworks at each other.”
John mindlessly scratched at the old burns where his left ear once grew. “That’s a shame, I had a really fun childhood.”
“But it got even worse. When we ran the numbers, there was no consistent system which condemned murder but condoned voluntary vasectomies. The average vasectomy destroyed billions of QALYs, by eliminating children, children of children, their grandchildren…”
Wait, what? “Well, that’s ridiculous. One is killing a real person, and one is just eliminating a hypothetical future. If you evaluate your moral utility as a delta from what you could have done instead, you’re going to go crazy.”
“That’s what we eventually figured out. Science would have moved much faster if gifted with clear thinkers like you. So we cut all that ‘possible futures’ stuff out, and settled on a simple axiom.”
“Axiom?” Is this some geometry thing? “ I just figure that dying is bad, much worse than the other bad stuff.”
“Exactly. That’s where we landed: ‘People dying is bad’. It’s been our guiding law, in the few thousand centuries since. We’ve rebuilt society accordingly.”
That seems fine. John figured. Wait. The “thousand centuries” thing is concerning. Paul seems like a nice guy, but storytelling isn’t his forte. “Speaking of which, where is everyone? Why is it so cold? And what’s with all the storage tanks? Why’d you defrost me in an Amazon warehouse?
“That gets me to the second great breakthrough: cryo-sleep.
“You were incredibly lucky — most people who fell headfirst and naked into a glacier in 2005 ended up a decomposed mess. But in the 2030s, we perfected supercooled nitrogen bath immersion, and could reliably freeze freshly-dead bodies, with minimal to no risk.”
“Minimal?”
“Cosmetic tissue loss, and nobody’s going to win any Nobel prizes. But the point is, we can stop people from fully dying. Once we figure out how to fix what killed someone, we can defrost them, fix them, and send them back out to enjoy a full life.”
Huh. “That’s really the dream, then. Live fast, die young, and …”
“Well…”
“Well?”
“Eventually, perhaps. But if you die too fast, nobody can put you back together. We could save the gunshot victims, and stop some heart attacks. But you know what they say — all the king’s horses and all the king’s men, can’t really do much, when Humpty’s parachute strings get tangled… so we couldn’t justify letting thrill-seekers skydive.”
Ok, so the future is kind of boring. I can live with that, I guess. “So what do people do for fun now-days, if the risky stuff is off the table?”
“I’m getting there. There was a bigger unsolved problem, a nut we haven’t cracked yet. I’ve personally been working on it for the last forty years.”
“Oh?”
“Old age. Even if you eliminate the dumb deaths like snakes, train crashes, and undeployed parachutes, eventually, people just break down. When a person makes it to the end — around 120 is the best we ever did— we run out of ways to keep them ticking.
“It’s likely fixable. But it’s possible that we won’t ever be able to reverse aging, only forestall it. Thermodynamics is a bitch. So we decided it’s ethically unsound to ever let a person die of old age. Cryo-sleep isn’t forever, but death from old age might be. So we head it off. When someone hits 80, they go into storage, and stay there until we’ve figured out how to stop aging”
That’s neat, but I’m only 30, and I’m also recently defrosted, cold, and hungry. This doesn’t seem super important. “I really appreciate this backstory, but I’d appreciate the cliff notes. Is there anyone else who could swap in?”
“I’m getting there. There isn’t anyone else.”
… fuck?
“We almost figured it out too late — by the late 21st century, the vast majority of our energy infrastructure was dedicated to cryogenics. The more people who kept breathing, the more people who kept getting older. When they hit 80, they filled up scarcer and scarcer cryo tanks.
“We only had a few decades left before we hit Peak Cryo. And if we run out of places to store people, it’ll be a catastrophe — we’ll have to pick and choose who to defrost and recycle. We can’t let that happen!
“Obviously we can’t just give up on fixing ageing. Everyone would end up dead! But it doesn’t make sense to parallelize that research — haven’t you read The Mythical Man-Month? We couldn’t waste effort — every hour counts.”
Ugh, I get it. “So you froze everyone. To stop the clock.”
“Precisely. Some people were unhappy, but most understood the logic — that it was the only possible choice, given our consistent moral foundation.”
Being dead had benefits. “I suppose that’s an insane but rational choice. So how close are we… you… to actually solving ‘old age’?”
“Me? Honestly, I gave it an honest effort for a decade, but found the biology all very confusing. I was just a furniture salesman before this, you know? I’ve spent the last 25 years mostly organizing my predecessor’s notes, in the hopes I could give you a head start.”
John blinked several times, and then several more. “Me?”
“Of course, you. It’s really just dumb luck the excavator-bots dug you up (while freeing up some storage space on the north slope) right before I retired. You’re the youngest person alive —or whatever — by a solid decade, so you’re next in line.
“It’s totally natural to not feel up to the task. But don’t sweat it — it’s not a huge setback if you fail. Once you’ve put in 50 years of the good-old-college-try, you’ll get retired, someone fresh will swap in.”
Uh, yeah, prepare for disappointment. “And if it takes longer than that? What if nobody currently ‘alive’ can solve it?”
“Worst case, we have a system for making new people, of course. It was the first thing we developed. But we won’t start unless it’s a true catastrophe, and run out of existing people. Given storage constraints, it’s irresponsible to go around making more people except as a last resort.”
I read some sci-fi back in college. Surely there’s a less-stupid way out of this. “What about storing people off-world? Maybe on the moon?”
“Dangerous. Here let me — ah, I have the notes” Paul swiveled back to the monitor. “My predecessor spent a few years on this, and couldn’t figure out how to deal with the potential micrometeorite damage. But I’d certainly encourage you to take a shot. Fresh neurons, fresh ideas!”
Well. “And if I say no?”
“I can tell you’re struggling. It’s ok. This is why decisions in the 21st century were so hard. Your people had no real moral axis!
“If you say no, obviously there are backup plans. The automation” Paul gestured up at the tangle of arms and wires menacingly crawling between stacks of barrels — cryo-tanks, John realized — “would simply re-freeze you and put you in the back of the queue. It would be quite unpleasant, but you have my promise you’d survive. Someday we’ll all get defrosted and have a good laugh about it.”
Paul slowly rose, his right arm on a cane, waving his left arm as if to hail a cab. “I don’t like to cut this off so soon. But I’ve already given you far more time than the norm thanks to the unusual circumstances of your defrosting, and I really shouldn’t linger. It’s far too dangerous, at my age.”
The closest mess of wires enveloped and lifted Paul as he shook John’s hand.
“Take your time and mull it over. Just shout, and the help” (gesturing to the nearest arm) “will point you to a shower and a hot meal. The research can wait until you’re ready. One nice benefit of our ethical framework, is that no decision ever has to be rushed.”
The wires disappeared quietly in the dark. Uncomfortably alone, John stared at the monitor blinking in front of him. This is the stupidest possible future. At least Terminator had an awesome robot uprising.
But at the same time, and what have I got to lose? The future is already stupid, and I certainly can’t make it any worse. I deserve a shower and breakfast first. I can take a crack at this for at least a day. I can try anything for a day. It can’t be much worse than being properly dead.
And it’s not like a bit of hard work is going to kill me John admitted, because dying is absolutely not an option anymore.