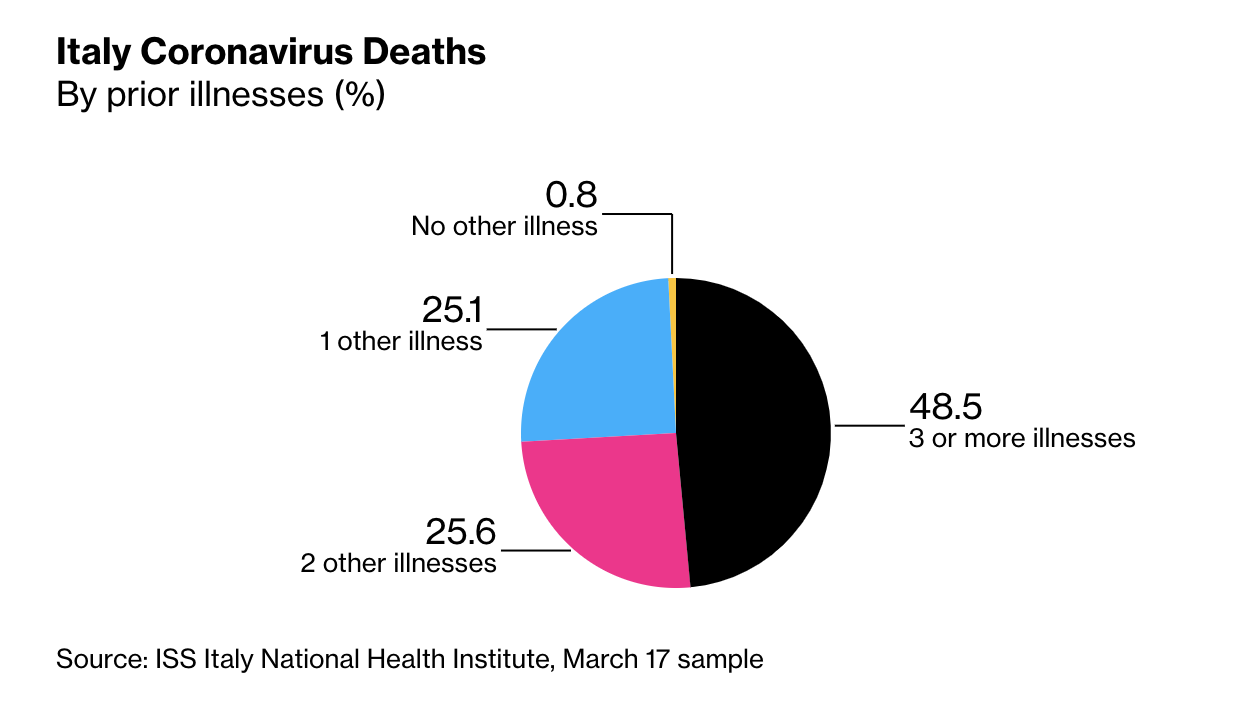
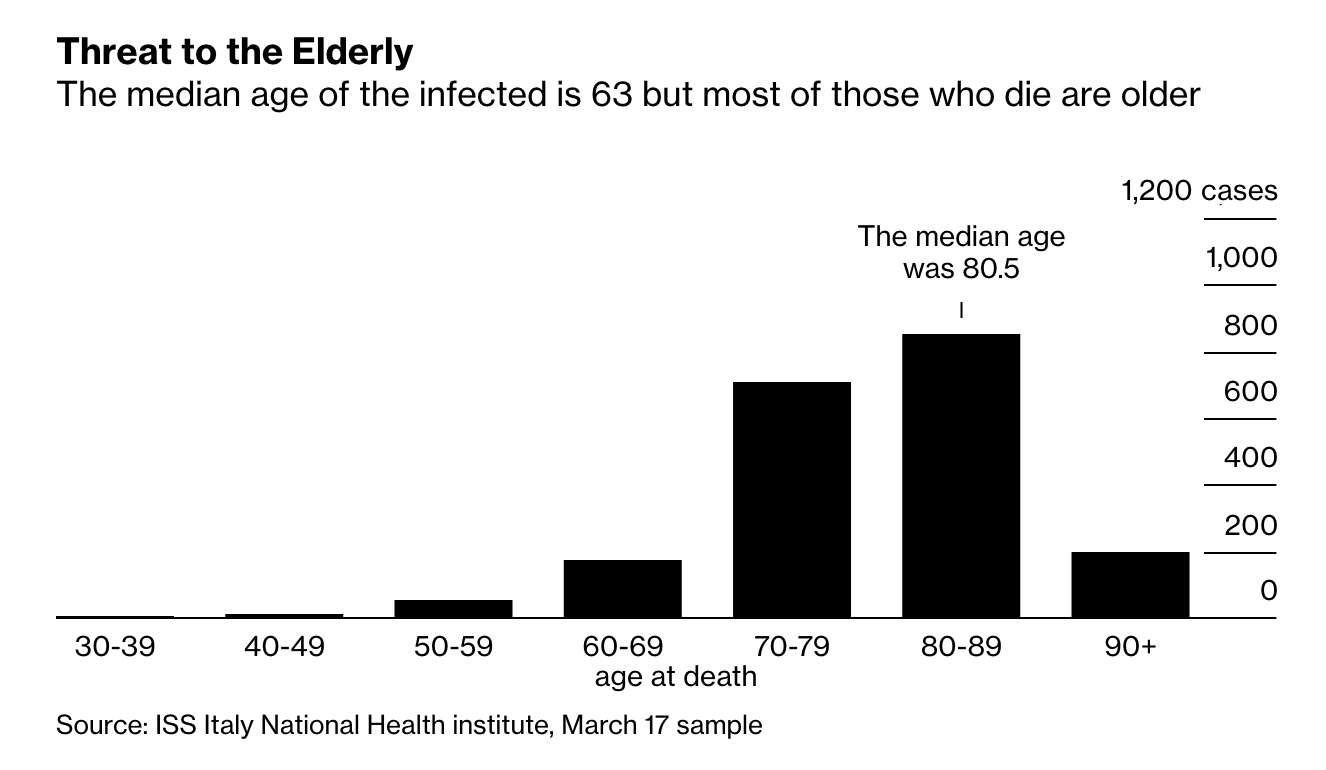
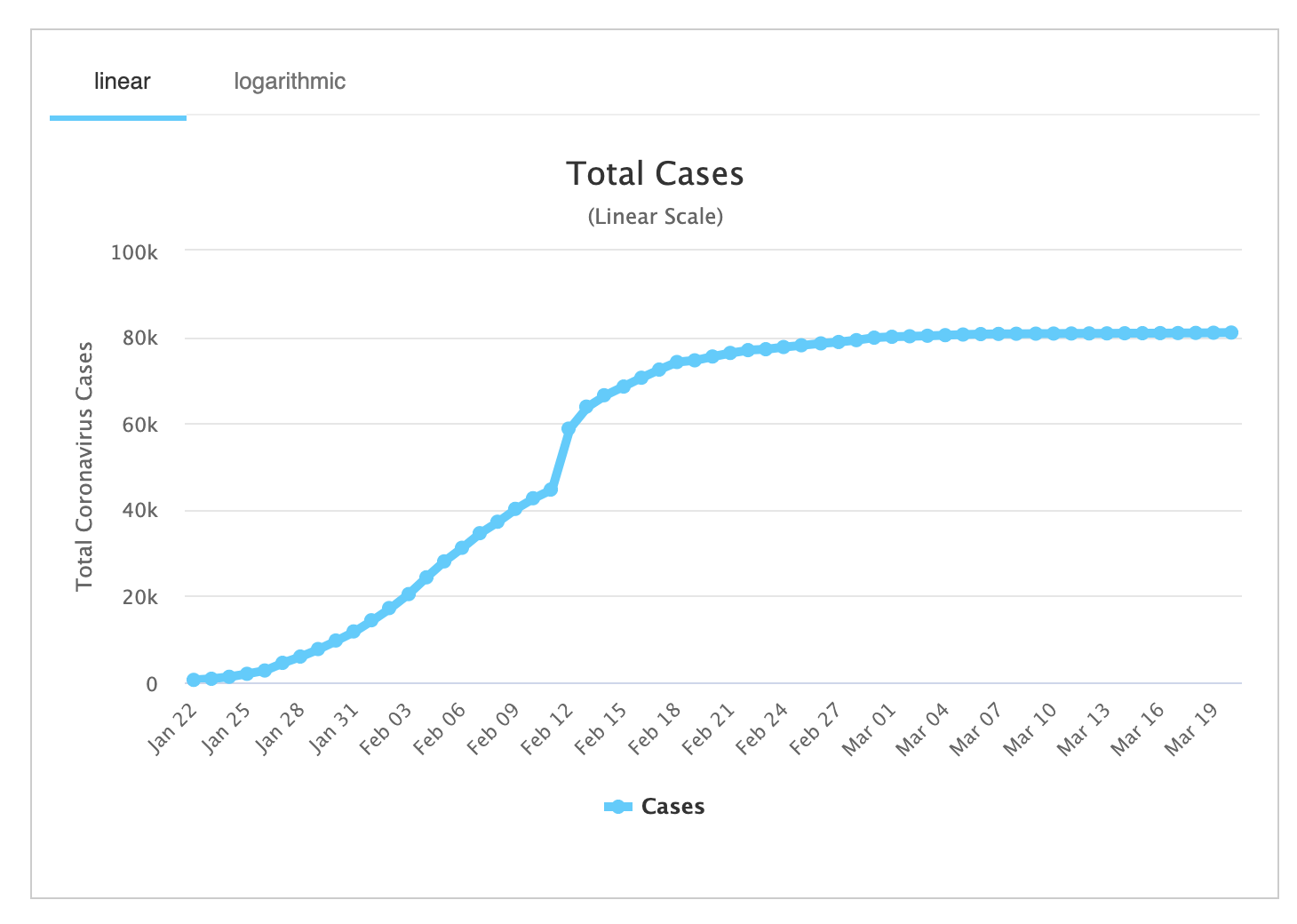
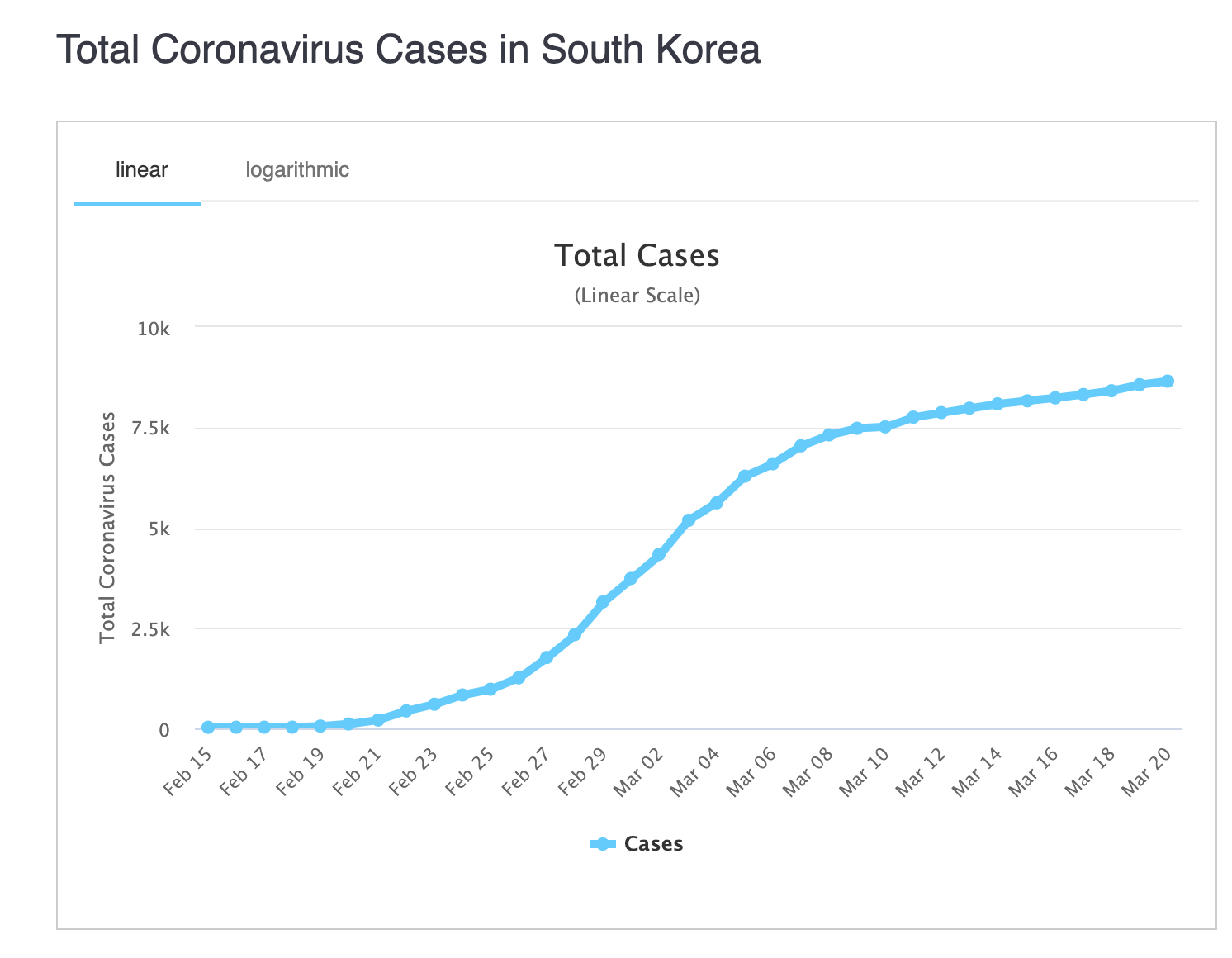
Jurassic park is a vividly entertaining movie, but few people watch it for the chaos theory. At most watchers come away with a first-order “bioengineering is dangerous and we shouldn’t play God” message. Which isn’t completely unintended, but is a very shallow version of the lesson Crichton wrote into the (more thoughtful, but less flashy) book of the same name, which is about inevitable unpredictable failures in complex control systems.
(the only place this gets airtime in the movie is the scene where Malcom flirts with Elie in the car, rolling water droplets off her hand, wherein the chaos theory is overshadowed by Malcom’s slightly scandalous horndog antics)
But long story short, the core of the story is a blow-by-blow illustration of the debate between the billionaire Hammond and the mathematician Ian Malcom, and if you abstract away the dinosaur flesh and cut down to the bones, you get this conversation:
Hammond: “We have created a novel complex system of living agents, and we can harness it to do immense good for the world!”
Malcolm: “But you can’t possibly control a system you don’t fully understand!”
Hammond: “Nonsense, we bought state-of-the-art technology, hired the best engineers, and haven’t had any serious accidents!”
Malcolm: “You can’t control this system because you think of these agents as your playthings, but they think of themselves as agents, and their goal is to survive. Without understanding the full system, it’s hubris to guess how or when it will fail, but I’m telling you it will fail.
(and of course, two hours or two hundred pages later, Hammond admits Malcom is right, the dinosaurs escape, and a lot of people get eaten).
It’s hard to take this seriously as a parable about existential risk, because at the end of the day you can make a T-Rex really scary but it’s hard to shake the feeling that a couple tactical bazookas would bring the T-Rex back into containment (and even in-universe they have to fudge this heavily with an inconvenient hurricane and evacuations, although I suppose this is one of the “unpredictable failure” modes)
But as Matt Yglesias has pointed out recently we actually kind of suck at writing approachable stories about existential risk, and in particular about AI risk, and I want to make the case here that Jurassic Park is actually best viewed as of 2022 as a story about how hard it is to align a superintelligent agent with human utility, and I think there are some concrete parallels to AI alignment, at least as it exists today:
- Systems which operate as agents eventually optimize their own objective function, not yours
In the story, “dinosaur safety” researchers built in not one but two failsafes to ensure containment:
- All dinosaurs were deficient in the amino acid Lysine
- All the dinosaurs were female
The dinosaurs of course, did not even realize they were supposed to be contained by these failsafes, and responded by (unpredictably) converting from female to male like a frog, and by eating lysine-rich foods.
In the generic version of that conversation above, you just end up describing the problem of AI alignment as is normally framed: AI when built as a tool (ex, translators, image detection, protein folding) is likely safe from dangerous outcomes (to the extent that people don’t use it to say, design novel pathogens), but as soon as you turn that system into an agent with goals, it becomes extremely difficult to keep the agent optimizing for human-oriented goals.
The classic parallel here is obviously the paperclip maximizer scenario: a friendly agent whose goal is to make as many paperclips as possible (for humans!) , but decides that the most effective way to maximize the paperclip count is to first use all atoms in the observable universe to replicate itself, and consequently converts all humans into paperclip-maximizer motor oil.
The AI fails containment not even through maliciousness or deviance (which is a whole separate problem) but by treating its own failsafe as an obstacle to be overcome; because of course it has no inbuilt reason to respect the spirit of the law, or even a concept of what that means to us.
- The system designers honestly tried to be responsible about containment, but stopping (or even slowing down) was not an acceptable outcome
Robert Muldoon was the experienced game warden brought into Jurassic Park by Hammond to ensure the safety of the park. Muldoon’s advice about how to contain the raptors (paraphrased)?
Muldoon: “We should kill them all “
Hammond: “lolno, we’re not shutting the park down”
AI safety is taken seriously by all the big players right now, but similarly has a “yes, and…” mandate. If the DeepMind alignment team’s conclusion was “we can’t trust that any models with over 10 billion parameters are safe to release in a public-facing product”, Google is going to hire a new safety team.
- Early warnings where the agents cross tripwires and cause real harm are probably just going to get brushed under the carpet by lawyers and ethics committees
The Nedry-instigated power loss and T-Rex escape wasn’t the first sign that Jurassic Park’s containment was fallible; the opening hook to both the book and movie is an animal handler’s death, and the characters were flown in as an oversight committee of sorts. But the goal wasn’t an honest investigation; the goal was to put a plausible stamp of approval on the operation by a crew of friendly faces.
Would DeepMind’s Ethics Board have the independence and freedom to shut down a model which seemed prone to cross the line from “aligned AI” to “unaligned AGI”? Well…
- Even perfect technological safeguards fail to (inevitable) human defection
Although the dinosaurs in Jurassic Park were well on their way to escaping containment on their own (via sex-changes and Lysine-heavy diets), the catastrophic physical containment failures weren’t technological; it was when Nedry shut down the electric fences to steal a vial of embryos and sell on the black market!
This one is straightforward; it doesn’t matter how responsible your AI alignment oversight committee is, if one of your engineers decides to steal and sell a dangerous model to a Russian crime syndicate for a few million crypto shitcoins.
- These agent-systems are built without significant popular or even regulatory input
Jurassic Park was built in secret. This stretches narrative suspension of disbelief, but it’s a conceit we accept. And from Hammond’s POV, it’s a surprise he’ll offer the world (although in practice any secrecy was mostly to deflect corporate competitors).
Modern AI isn’t a technical secret to the general populace (Google may even claim to try to inform the public about the benefits of their AI assistant technology), but functionally the general public has no concept of how close or far we are from an AGI which will, for better or for worse, upend their place in the world.
- At the end of the day, a new world where these freely-operating agents have completely escaped their control systems is presented as a fait accompli to the general public
Jurassic Park III, (I admit, an overall franchise-milker of a film) ends with a cinematic shot of Pteranodons flying off into the sunset, presumably to find new nesting grounds. This is a romantic vision, undercut by the fact that those Pteranodons very recently tried to eat the film’s main characters, and presumably the humans who live in those nesting grounds will have no veto power over this new arrangement.
And likewise, AGI — or even scoped AI — absent dramatic regulatory change, is going to be presented as a fait accompli to the general public.
What’s my point?
I don’t know if the lesson here is that some enterprising cinematographer can reskin Jurassic Park as AGI Park to get Gen Z interested in AGI risk or what, or if there are more bite-sized lessons about how to make hard-to-grok theoretical risks.
But I do feel we’re missing opportunities to (lightly) inform the public when the contemporary cinematic treatment of technology which is about to turn the world upside down looks like uh, whatever Johnny Depp is doing here, and that really feels like an own-goal for the species (and maybe all sentient organic life if things go really off the rails).