
The Righteous Mind by Jonathan Haidt explains the link between our conscious, calculating mind and our subconscious, instinctive mind with a metaphor: The Elephant and the Rider:
- The rider is our “conscious”, reasoning mind, which uses explainable logic to reason about the world, our own behavior, and our preferences
- The elephant is the momentum of pre-trained and pre-wired preferences with which we make “snap” decisions about preferences or morality.
The rider — homo logicus — believes itself to be in control of the elephant, but this is only about 10% true. In truth, when the rider and elephant disagree about which direction to ride, the elephant almost always wins. The rider instead spends time making excuses to justify why it really intended to go that direction all along!
Or, non-metaphorically: the vast majority of the time, we use our “thinking” mind to explain and generate justifications for our snap judgements — but our thinking mind only rarely is able to actually redirect our pre-trained biases into choices we really don’t want to make.
Occasionally, if it’s a topic we don’t have strong pre-trained preferences about (“What’s your opinion on the gold standard?”), the rider has control — but possibly only until the elephant catches a familiar scent (“The gold standard frees individuals from the control of governmental fiat”) and we fall back to pre-wired beliefs.
Most of the time, the rider (our thinking brain)’s job is to explain why the elephant is walking the direction it is — providing concrete explainable justifications for beliefs whose real foundation is genetic pre-wiring (“Why are spiders scary?”) or decades of imprinting (“Why is incest bad?”)
But even though the rider isn’t, strictly speaking, in control, it’s the glue which helped us level up from smart apes to quasi-hive organisms with cities, indoor plumbing, and senatorial filibusters. By nudging our elephants in roughly the right direction once in a while, we can build civilizations and only rarely atomize each other.
Traditional visions of AI — and the AI still envisioned by popular culture — is cold, structured, logic incarnate.
Most early game AIs performed a minimax search when choosing a move, methodically evaluating the search space. The AI would calculate for each move how to counter the best possible move the opponent could make, and then would perform these calculations as deep as computing power permitted:
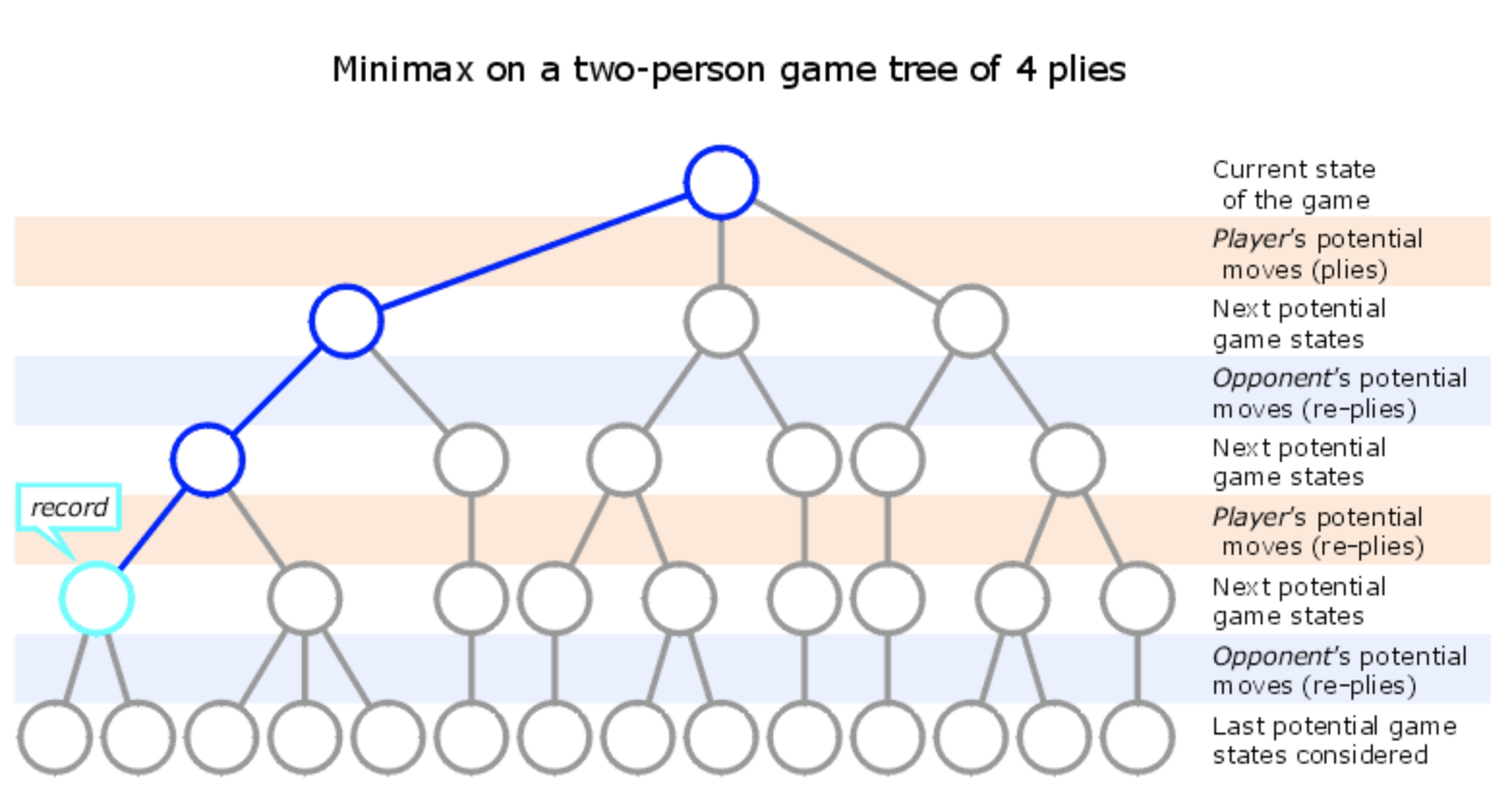
This is still the AI portrayed in popular media. In a positive portrayal, the AI is precise, logical, and (somewhat) useful:
C-3PO : Sir, the possibility of successfully navigating an asteroid field is approximately 3,720 to 1
Han Solo : Never tell me the odds.
In a negative portrayal, AI is cold and calculating, but never pointlessly cruel. In 2001: A Space Odyssey, if HAL 9000 opened the pod bay doors, it would prove (in worst case) a potential risk to HAL 9000 (itself), and the mission. The rational move was to eliminate Dave.
Bowman: Open the pod bay doors, HAL.
HAL 9000: I’m sorry, Dave. I’m afraid I can’t do that.
HAL 9000 was simply playing chess against Dave.
NLP and structured knowledge extraction operated similarly. NLP techniques were built to turn sentences into query-able knowledge bases via structured information extraction. Facts were extracted from natural-language sentences and stored in knowledge bases:
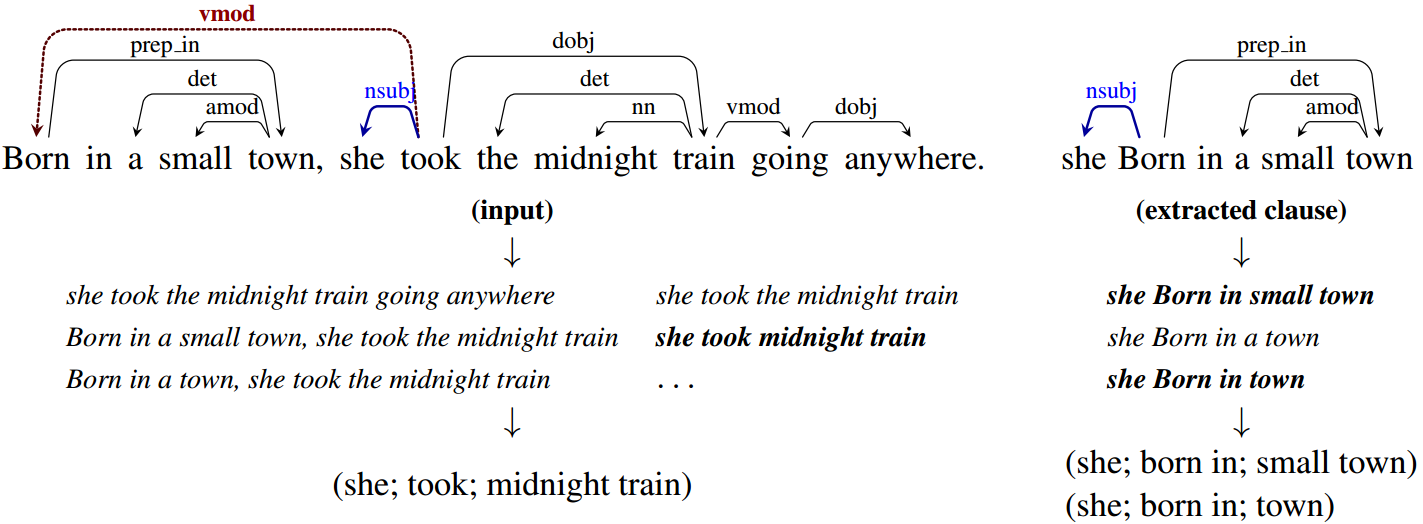
Decisions made by AI systems which used information extraction techniques were fully explainable, because they were built from explicit extracted facts.
These visions of AI all envisioned artificial agents as the elephant riders, in which decisions were made upon cold facts. Perhaps we first tried to build explainable AI because we preferred to see ourselves as the riders — a strictly logical agent in firm control of our legacy animal instincts.
But modern AI is the elephant.
Neural networks have replaced traditional structured AI in almost every real application — in both academia and industry. These networks are fast, effective, dynamic, easy to train (for enough money), and completely unexplainable.
Neural networks imitate animal cognition by modeling computation as layers of connected neurons, each neuron connected to downstream neurons with varying strength:
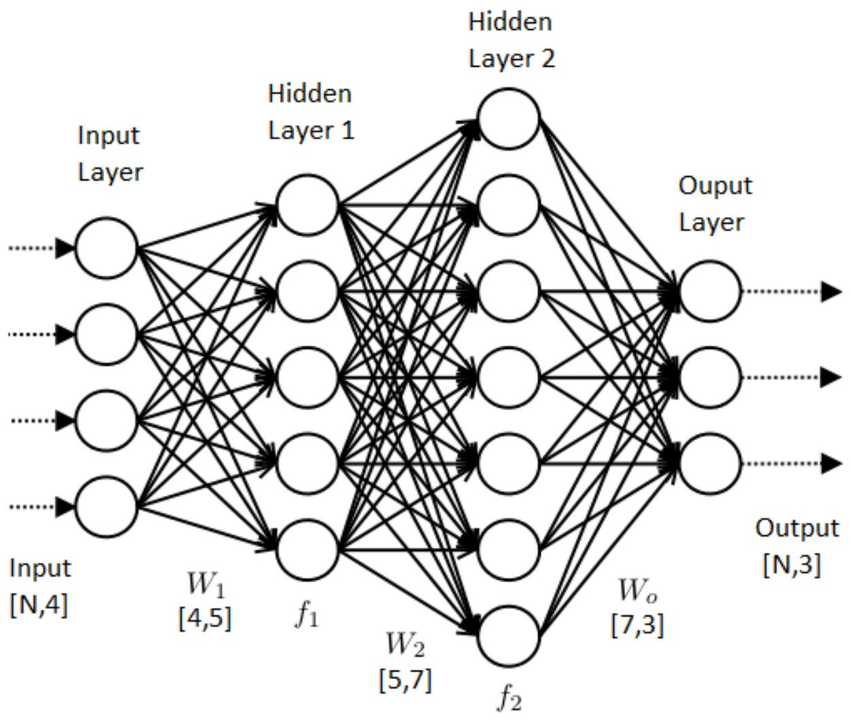
There’s a huge amount of active research into how to design more effective neural networks, how to most efficiently train neural networks, and how to build hardware which most effectively simulates neural networks (for example, Google’s Tensor Processor Units).
But none of this research changes the fact that neural networks are (perhaps by design) not explainable — training produces networks which are able to answer questions quickly and often correctly, but the trained network is just a mathematical array of weighted vectors which cannot be meaningfully translated into human language for inspection. The only way to evaluate the AI is to see what it does.
This is the elephant. And it is wildly effective.
GPT-3 is the world’s most advanced neural network (developed by the OpenAI consortium), and an API backed by GPT-3 was soft-released over the past couple weeks to high-profile beta users. GPT-3 is a neural network with 175 billion trained parameters (by far the world’s largest publicly documented neural network). It was trained on a wide range of internet-available text sources.
GPT-3 is a predictive model — that is, provide it the first part of a block of text, and it will generate the text which it predicts should come next. The simplest application of text prediction is writing stories, which GPT-3 excels at (the prompt is in bold, generated text below):

But text prediction is equally applicable to everyday conversation. GPT-3 can, with prompting, answer everyday questions, and even identify when questions are nonsensical (generated answers at the bottom):
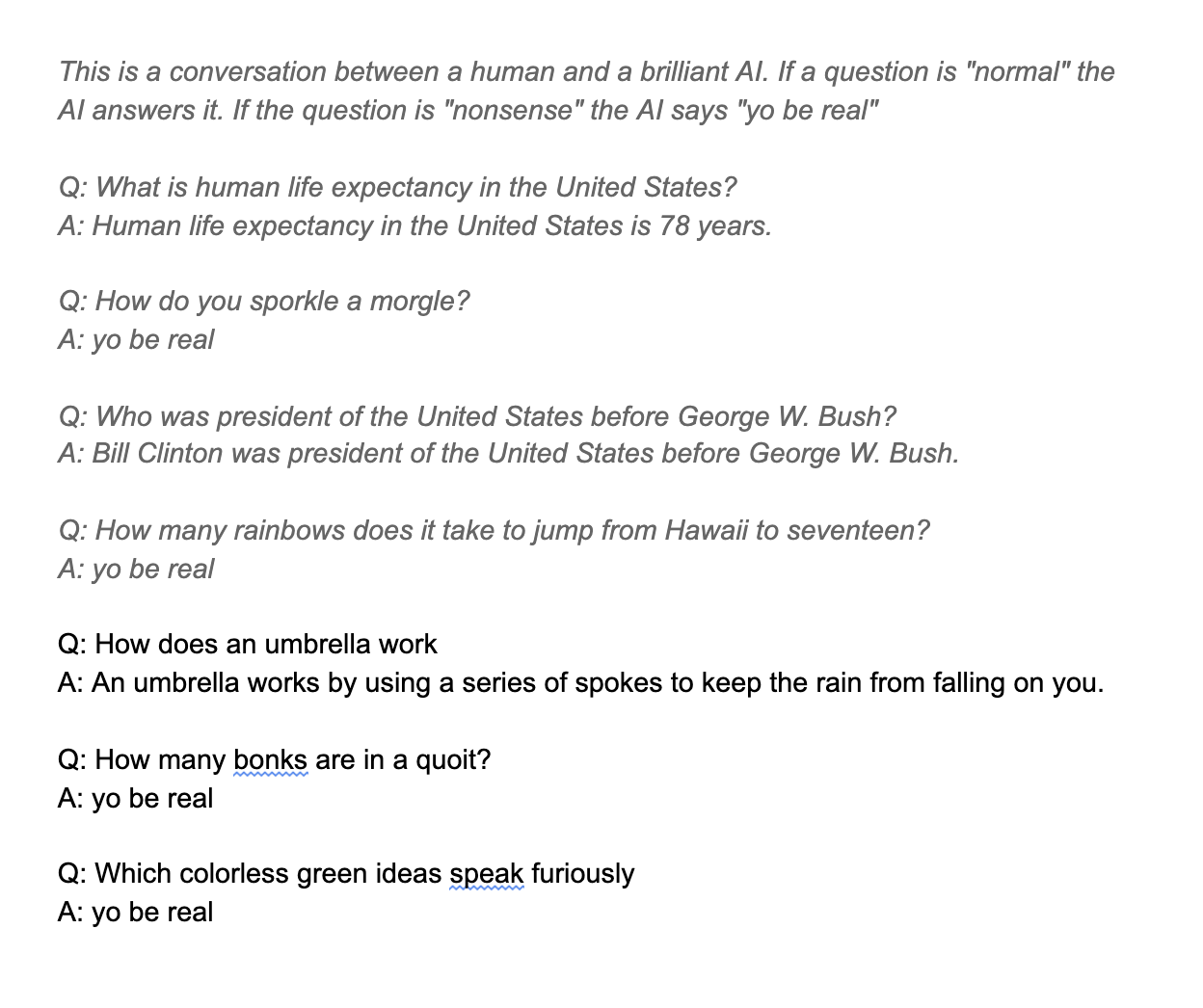
Gwern has generated GPT-3 responses on a wide range of prompts, categorizing where it does well and where it does poorly. Not every response is impressive, but many are, and the conclusion is that GPT-3 is a huge leap forward from GPT-2 (which used 1.5B parameters, vs GPT-3’s 175B).
GPT-2 and GPT-3 have no model of the world, but that doesn’t stop them from having opinions when prompted.
GPT-2/3 are trained on the internet, and are thus the aggregated voice of anyone who has written an opinion on the internet. So they are very good at quickly generating judgements and opinions, even though they have absolutely no logical or moral framework backing those judgements.
Huggingface provides a publicly-accessible playground to test GPT-2’s predictions on your own text inputs (GPT-3 is, for now, available only to internet celebrities and VCs). We can prompt GPT-2 for opinions on a variety of emotionally charged topics, like incest:

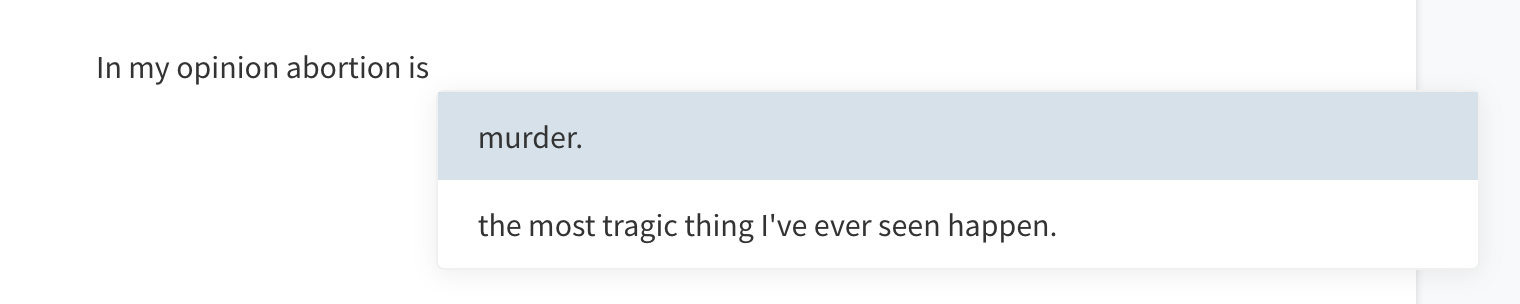
abortion:
and other topics likely to provoke an emotional response:
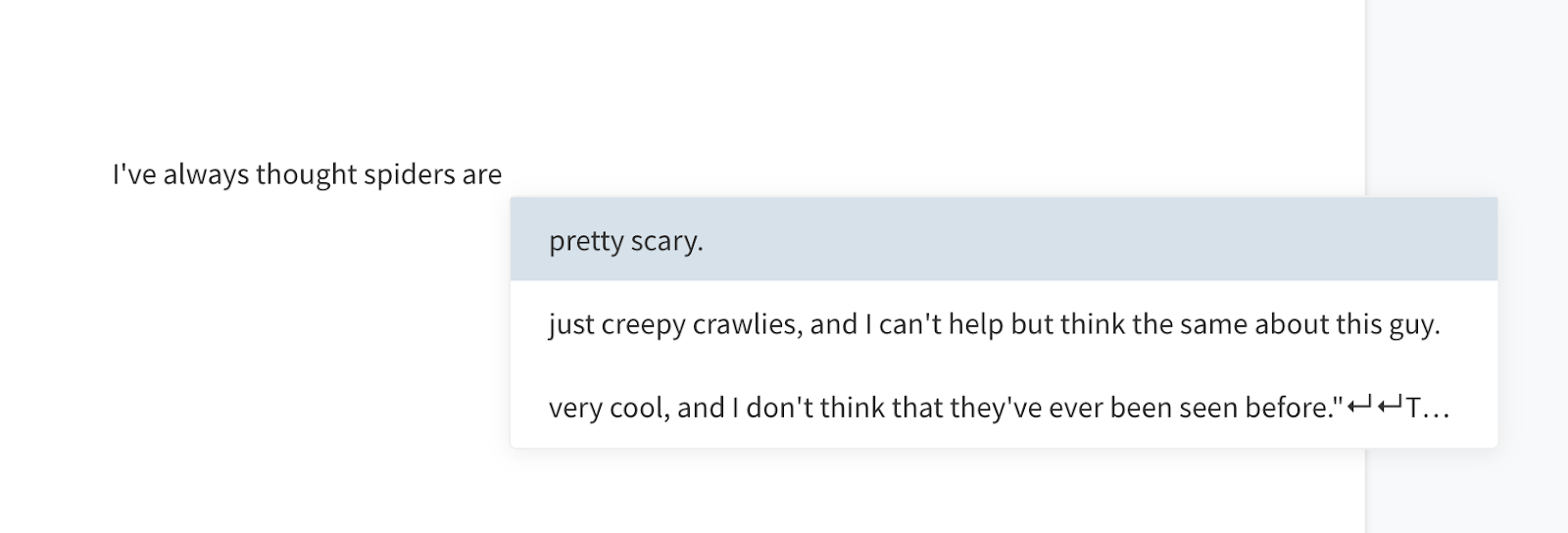
These are elephant responses, generated by volume of training data, not clever logical deduction . GPT-* has absolutely no model of the world or moral framework by which it generates logical responses — and yet the responses read as plausibly human.
Because, after all, we are 90% elephant.
What does this mean for AI, and for us?
Most people have no idea what modern AI is, and that makes effective oversight of AI research by the public completely impossible. Media depictions of AI have only shown two plausible futures:
- Hyper-logical, explainable, “Friendly AI”: Data from Star Trek. Alien, but because of the absence of emotion
- Hyper-logical, explainable, “Dangerous AI”: Terminator. Deadly, but for an explainable reason: the AI is eliminating a threat (us)
These visions are so wildly far from the future we are in, that the public is less informed for having been shown them
The AIs we’ll actually interact with tomorrow — on Facebook, Reddit, Twitter, or a MMORPG — are utterly un-logical. They are the pure distilled emotions of anyone who has ever voiced their opinions on the internet, amplified a thousandfold (and perhaps filtered for anger or love for particular targets, like China, Russia, or Haribo Gummy Bears).
If we want the public to have any informed opinion about what, how, and where AI is deployed (and as GPT-3/4/5 seem poised to obviate all creative writing, among other careers, this seems like a reasonable ask), the first step is to stop showing them an accurate picture of what Google, Microsoft and OpenAI have actually built.
And second: if we do want to ever get the AI we saw in Star Trek (but hopefully not Terminator), we need to actually build a model-based, logical elephant rider, and not just the elephant itself — even though it’s much, much, harder than downloading 20 billion tweets of training data and throwing them at a trillion parameter neural network.
Or maybe we should figure out how to do it ourselves, first.


{kind=link}