Hit another QGIS snag. This one took a day or so to sort through, and I actually had to write code. So I figured I’d write it up.
I struggled to solve the following problem using QGIS GUI tools:
- I have a bunch of points (as a vector layer)
- I have a bunch of vector layers of polygons
- I want to know, for each point, which layers have at least one feature which contain this point
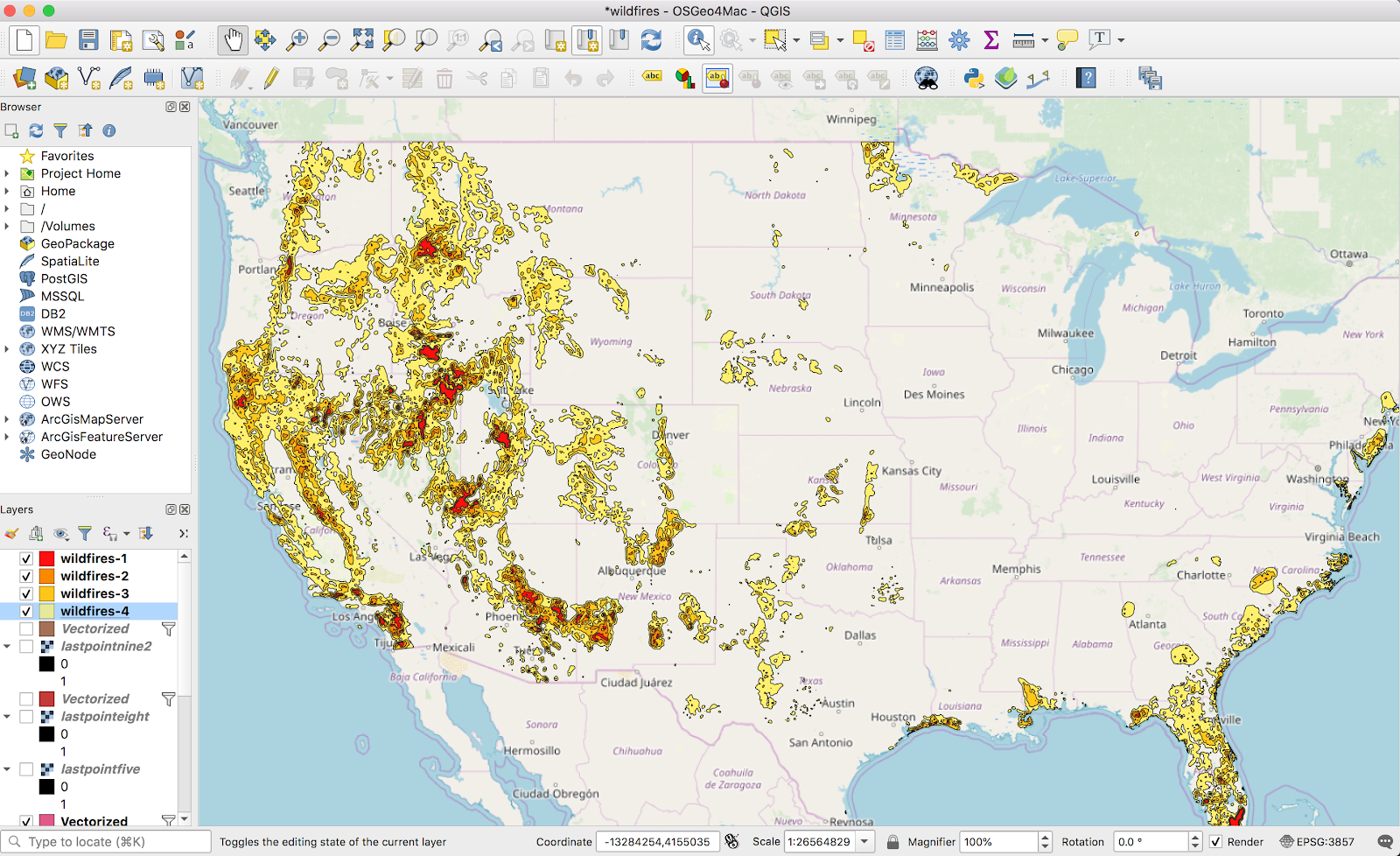
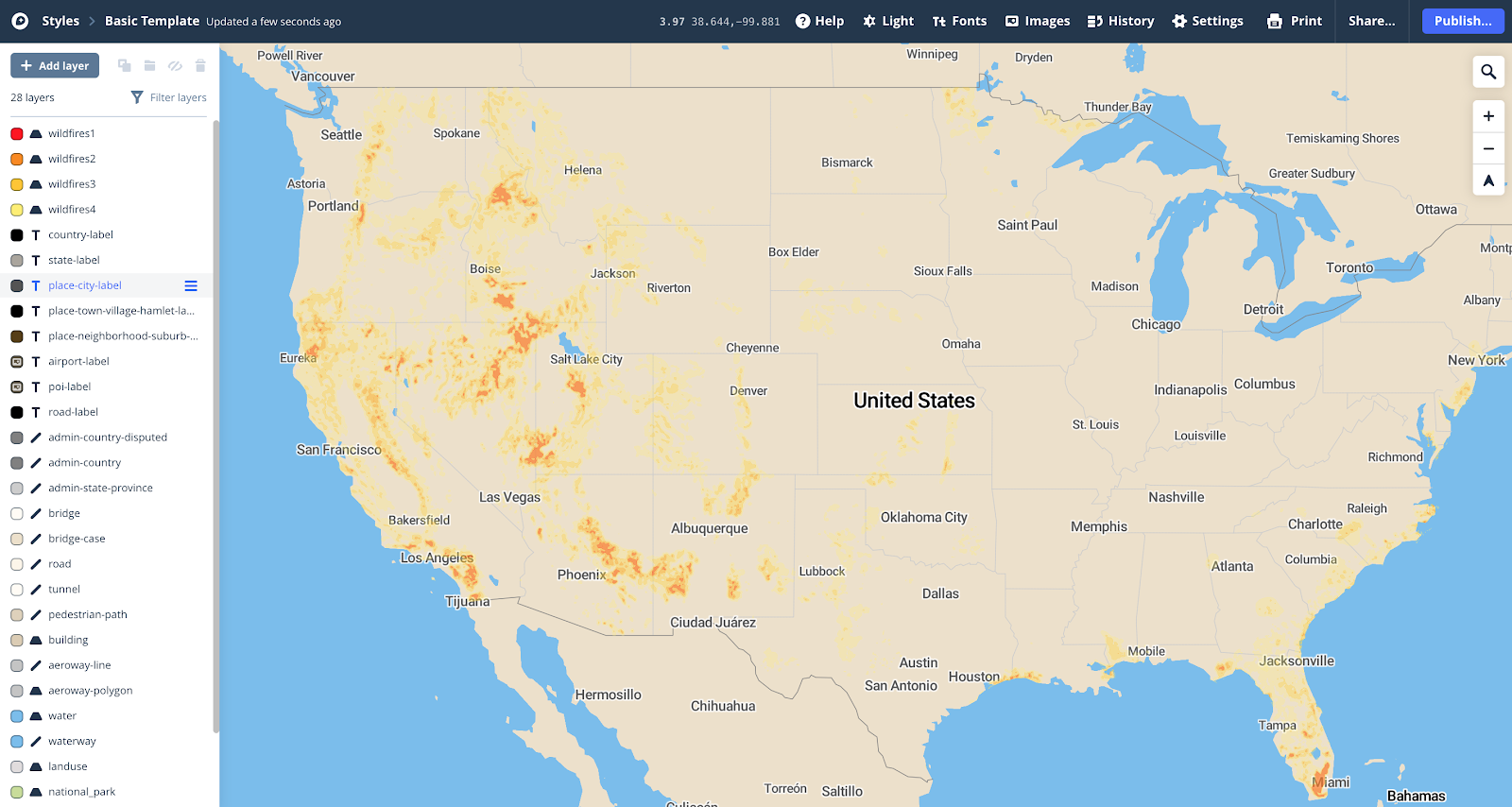
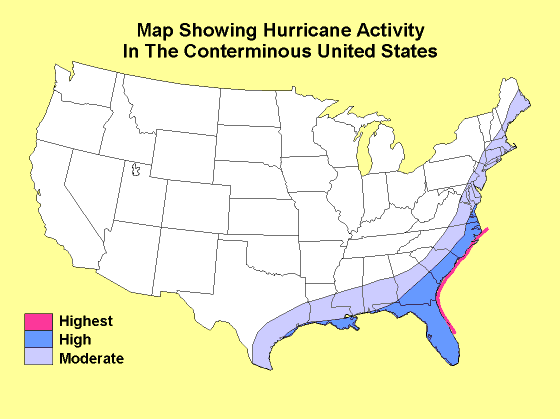
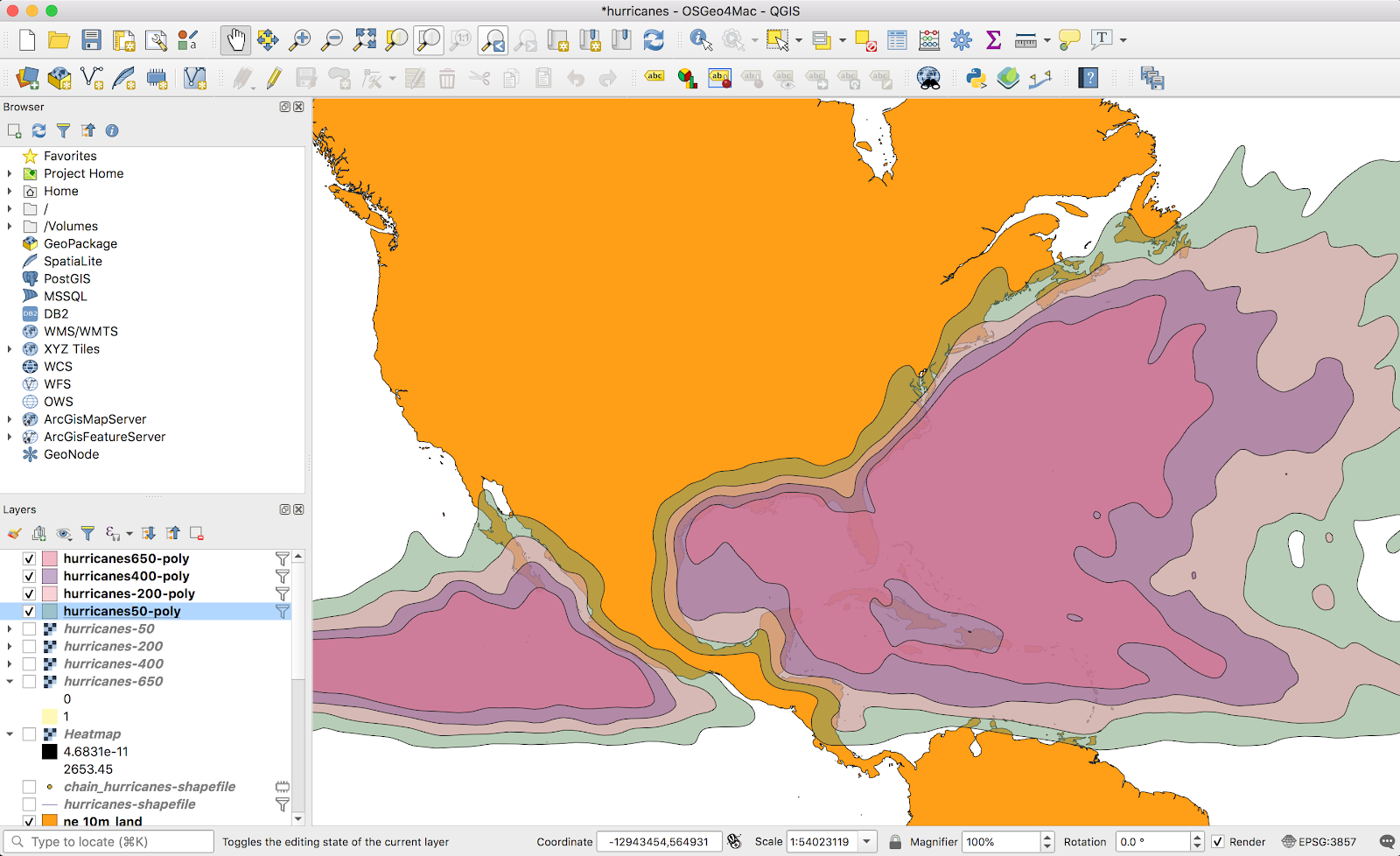
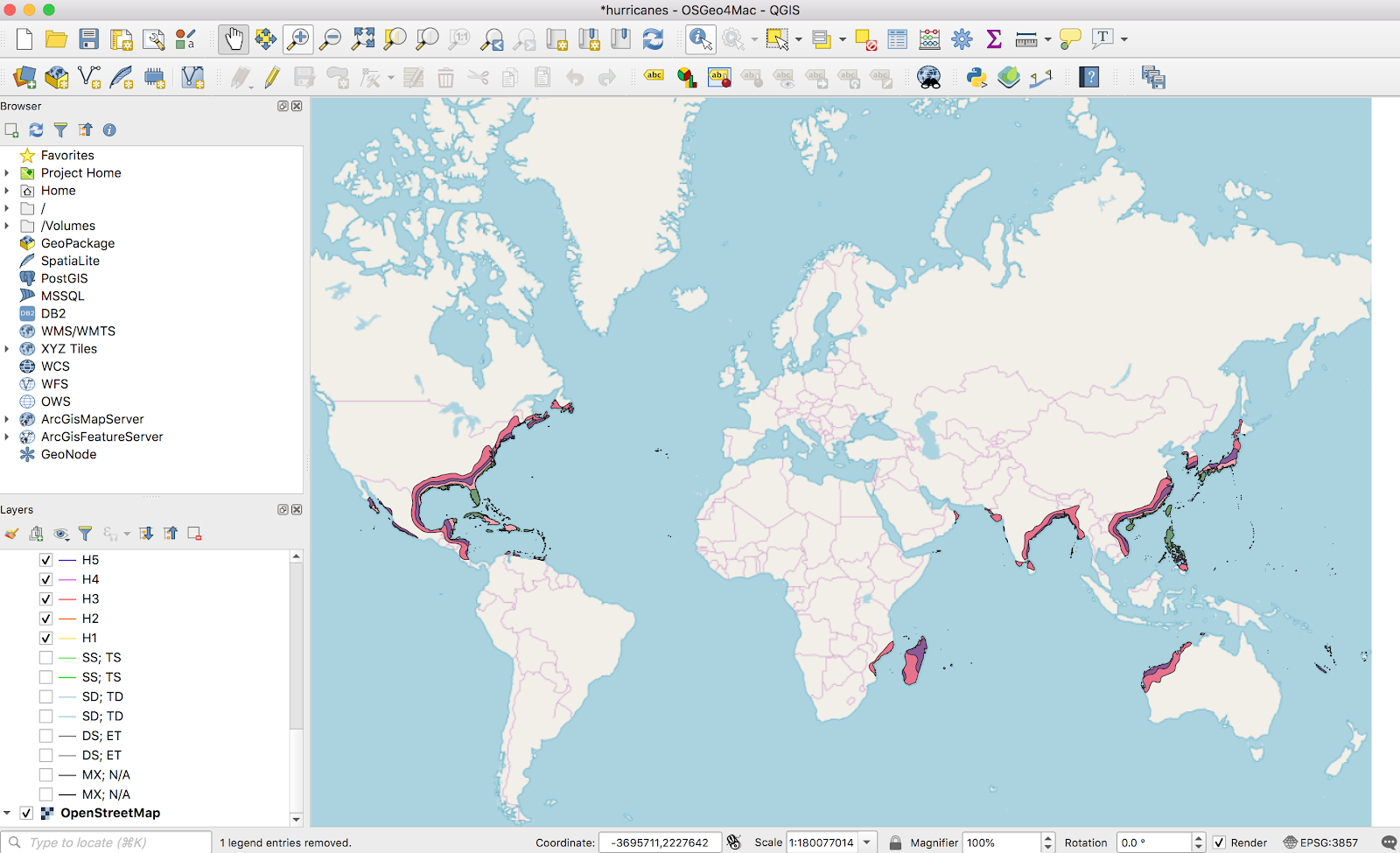
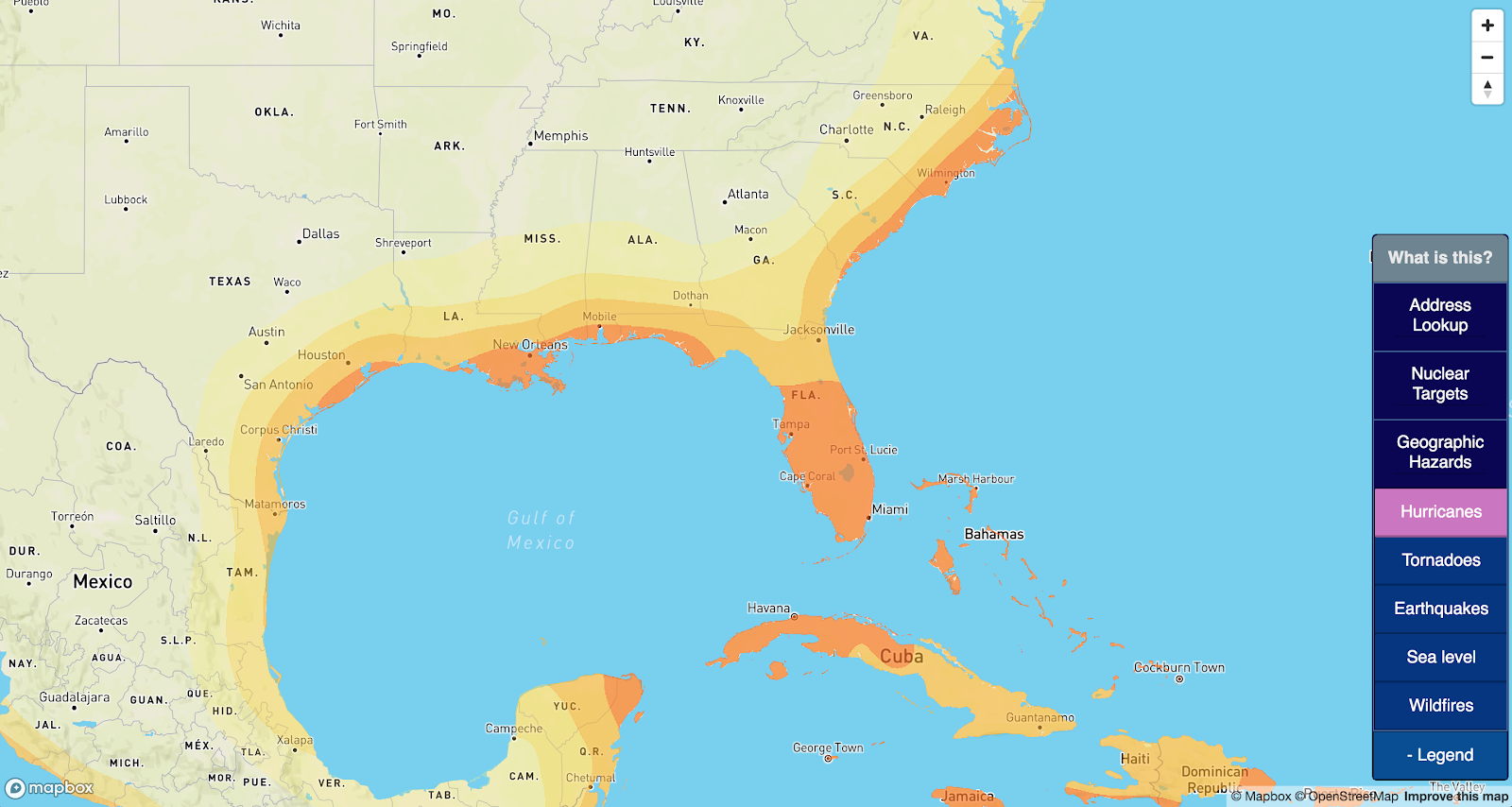
Speaking more concretely: I have cities (yellow), and I have areas (pink). I want to find which cities are in the areas, and which are not:

I assumed this would be a simple exercise using the GUI tools. It might be. But I could not figure it out. The internet suggests doing a vector layer join, but for whatever reason, joining a point layer to a vector layer crashed QGIS (plus, this is slow overkill for what I need — simple overlap, not full attribute joins).
Luckily, QGIS has rich support for scripting tools. There’s a pretty good tutorial for one example here. The full API is documented using Doxygen here. So I wrote a script to do this. I put the full script on GitHub —you can find it here.
I will preface this before I walk through the code — this is not a clever script. It’s actually really, really dumb, and really, really slow. But I only need this to work once, so I’m not going to implement any potential optimizations (which I’ll describe at the end).
First, the basic-basics: navigate Processing → Toolbox. Click “Create New Script from Template”

This creates — as you might expect — a new script from a template. I’ll go over the interesting bits here, since I had to piece together how to use the API as I went. Glossing over the boilerplate about naming, we only want two parameters: the vector layer with the XY points, and the output layer:
def initAlgorithm(self, config=None):
self.addParameter(
QgsProcessingParameterFeatureSource(
self.POINT_INPUT,
self.tr('Input point layer'),
[QgsProcessing.TypeVectorPoint]
)
)
self.addParameter(
QgsProcessingParameterFeatureSink(
self.OUTPUT,
self.tr('Output layer')
)
)
Getting down into the processAlgorithm block, we want to turn this input parameter into a source. We can do that with the built-in parameter methods:
point_source = self.parameterAsSource(
parameters,
self.POINT_INPUT,
context
)
if point_source is None:
raise QgsProcessingException(self.invalidSourceError(parameters, self.POINT_INPUT))
A more production-ized version of this script would take a list of source layers to check. I could not be bothered to implement that, so I’m just looking at all of them (except the point layer). If it’s a vector layer, we’re checking it:
vector_layers = []
for key,layer in QgsProject.instance().mapLayers().items():
if(layer.__class__.__name__ == 'QgsVectorLayer'):
if(layer.name() != point_source.sourceName()):
vector_layers.append(layer)
else:
feedback.pushInfo('Skipping identity point layer: %s:' %point_source.sourceName())
We want our output layer to have two types of attributes:
- The original attributes from the point layer
- One column for each other layer, for which we can mark presence with a simple 0/1 value.
output_fields = QgsFields(point_source.fields())
for layer in vector_layers:
feedback.pushInfo('layer name: %s:' %layer.name())
field = QgsField(layer.name())
output_fields.append(field)
Similar to the input, we want to turn the parameter into a sink layer:
(sink, dest_id) = self.parameterAsSink(
parameters,
self.OUTPUT,
context,
output_fields,
point_source.wkbType(),
point_source.sourceCrs()
)
if sink is None:
raise QgsProcessingException(self.invalidSinkError(parameters, self.OUTPUT))
Although it seems like a “nice to have”, tracking progress as we iterate through our points is pretty important; this script ran for 24 hours on the data I ran through it. If I had hit the 2 hour mark with no idea of progress — I’d certainly have given up.
Likewise, unless you explicitly interrupt your script when the operation is cancelled, QGIS has no way to stop progress. Having to force-kill QGIS to stop a hanging processing algorithm is super, duper, annoying:
points = point_source.getFeatures()
total = 100.0 / point_source.featureCount() if point_source.featureCount() else 0
for current, point in enumerate(points):
if feedback.isCanceled():
break
feedback.setProgress(int(current * total))
From here on, we iterate over the target layers, and add to the target attributes if point is present in any feature in the target layer:
attr_copy = point.attributes().copy()
for layer in vector_layers:
features = layer.getFeatures()
feature_match = False
geometry = point.geometry()
for feature in features:
if (feature.geometry().contains(geometry)):
feature_match = True
break
if(feature_match):
attr_copy.append(1)
else:
attr_copy.append(0)
Last but not least, we just output the feature we’ve put together into the output sink:
output_feature = QgsFeature(point)
output_feature.setAttributes(attr_copy)
feedback.pushInfo('Point attributes: %s' % output_feature.attributes())
sink.addFeature(output_feature, QgsFeatureSink.FastInsert)
And that’s about it (minus some boilerplate). Click the nifty “Run” button on your script:
Because we wrote this as a QGIS script, we get a nice UI out of it:

When we run this, it creates a new temporary output layer. When we open up the output layer attribute table, we get exactly what we wanted: for each record, a column with a 0/1 for the presence or absence within a given vector layer:
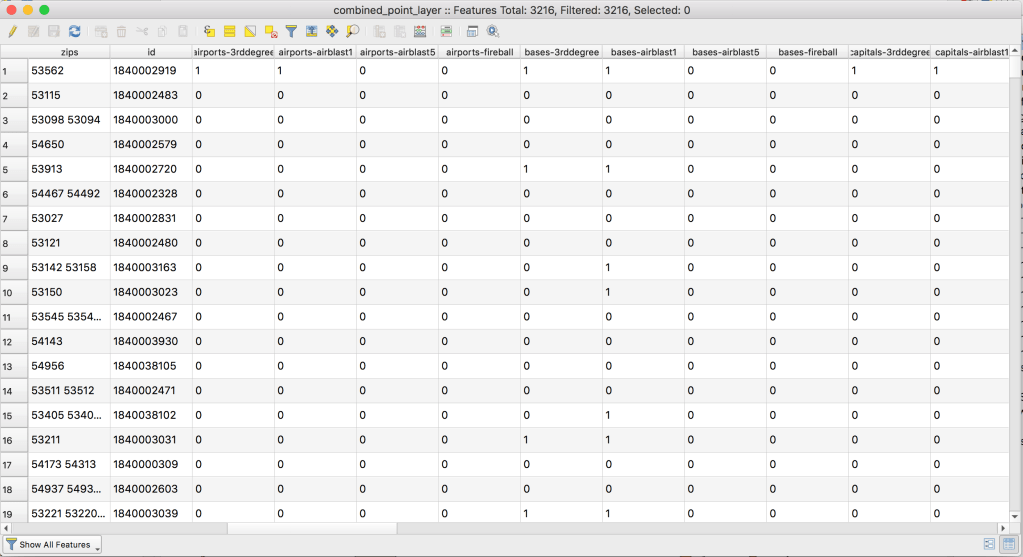
Perfect.
Now, this script is super slow, but we could fix that. Say we have n input points and m total vector features. The obvious fix is to run in better than n*m time — we’re currently checking every point against every feature in every layer. We could optimize this by geo-bucketing the vector layer features:
- Break the map into a 10×10 (or whatever) grid
- For each vector layer feature, insert the feature into the grid elements it overlaps.
- When we check each point for layer membership, only check the features in the grid element it belongs to.
If we’re using k buckets (100, for a 10×10 grid), this takes the cost down to, roughly, k*m + n*m/k, assuming very few features end up in multiple buckets. We spend k*m to assign each feature to the relevant bucket, and then each point only compares against 1/k of the vector features we did before.
I’m not implementing this right now, because I don’t need to, but given the APIs available here, I actually don’t think it would be more than an hour or two of work. I’ll leave it as an exercise to the reader.
Anyway, I’d been doing my best to avoid QGIS scripting, because it seemed a bit hardcore for a casual like me. Turned out to be pretty straightforward, so I’ll be less of a wimp in the future. I’ll follow up soon™ with what I actually used this script for.